/https://www.ilsoftware.it/app/uploads/2023/05/img_14593.jpg "Estrarre dati da una pagina HTML: come si fa")
Quante volte vi è capitato, per le ragioni più disparate, di dover estrarre dati da un sito web per poterli rielaborare ed eventualmente riutilizzare?
In questo articolo non ci occupiamo degli aspetti legali connessi con l’estrazione dei dati da una pagina HTML ma ci concentriamo invece sugli strumenti che permettono di raccogliere i dati in forma ragionata e strutturata per poi avere la possibilità di gestirli utilizzando, ad esempio, un normale foglio di calcolo.
I dati pubblicati nelle pagine web sono generalmente inseriti all’interno di tabelle, di tag div oppure entro altri tag HTML di vario genere.
Pochi sanno che Fogli Google e, in generale, le altre app della suite Drive mettono a disposizione alcune potenti funzioni per estrarre dati da una pagina HTML, anche se pubblicata su un server remoto.
Nell’articolo Foglio di calcolo: la potenza delle formule abbiamo spiegato quanto siano versatili le funzioni utilizzabili nei fogli elettronici per creare formule più o meno complesse.
Nell’articolo Importare dati da HTML a Excel: come fare abbiamo invece presentato la funzione Google ImportHTML che consente di estrarre codice HTML da pagine web di qualunque sito.
Ancora più versatile è la funzione ImportXML che consente di importare dati partendo da vari tipi di dati strutturati, tra cui XML, HTML, CSV, TSV e feed XML RSS e ATOM (vedere questa pagina di supporto).
Per estrarre dati da un sito web, è sufficiente aprire un nuovo documento Fogli Google portandosi su Google Drive quindi cliccando su Nuovo, Fogli Google.
Dopo aver selezionato, ad esempio, la prima cella del foglio di calcolo, si potrà impostare la formula basata sull’utilizzo di ImportXML.
Il corretto utilizzo di ImportXML non può prescindere da un attento studio del sorgente HTML del sito dal quale si desiderano importare i dati.
L’importante è non scoraggiarsi mai: una soluzione per importare i dati pubblicati nella pagina HTML remota si trova sempre!
Estrarre dati da una pagina HTML con Google ImportXML
Il miglior modo per imparare l’utilizzo della funzione ImportXML è partire da qualche esempio pratico.
Si supponga che la pagina HTML contenente i dati d’interesse mostri una lista puntata o numerata costruita usando il tag li.
Per estrarre i dati contenuti in una lista HTML, è sufficiente ricorrere alla formula che segue:
Se, all’interno di ciascun tag li, fosse contenuto un link (tag anchor), e si volesse estrarre solo il nome del link, basterà modificare la formula come segue:
La seguente formula, invece, consentirà di estrarre solo l’URL (attributo href di ciascun tag anchor contenuto all’interno dei tag li):
Per evitare di estrarre dati inutili, suggeriamo di individuare, ad esempio, il “contenitore” (tag div) che ospita le informazioni d’interesse.
Il tag div sarà contraddistinto, di solito, col nome di una classe CSS (class) o un ID.
Per fare in modo che la funzione Google estragga i dati contenuti in un certo div, basterà usare la seguente sintassi:
=importxml("http://urldellapaginaweb.com/nomepagina";
"//div[@class='NOMECLASSE']//li")
In questo modo le varie celle del foglio di calcolo Google verranno “popolate” recuperando le informazioni contenute nei tag li ospitati all’interno di ciascun div chiamato NOMECLASSE.
La funzione importxml elimina le tag HTML eventualmente presenti. Così, specificando il nome del div, la funzione importerà solamente il testo. Per importare il contenuto delle singole tag contenute nel div, è necessario “ingegnarsi” come spiegato più avanti.
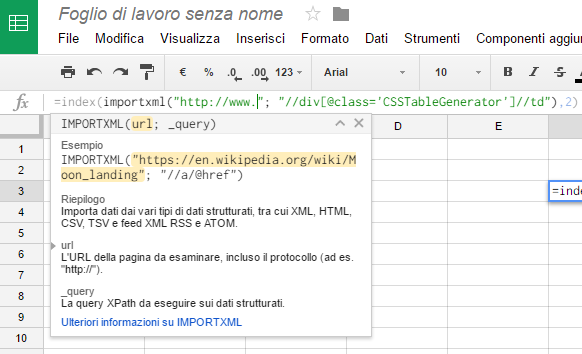
L’utilizzo di una funzione nidificata come la seguente permette invece di estrarre solamente il contenuto del secondo tag td dei div NOMECLASSE:
=index(importxml("http://urldellapaginaweb.com/nomepagina";
"//div[@class='NOMECLASSE']//td");2)
La volontà di estrarre il contenuto del secondo tag è indicata dal numero 2 all’interno della funzione index.
Nulla vieta, comunque, di usare una funzione più complessa, come la seguente per estrarre i dati dalla pagina web HTML a seconda del numero di riga del foglio elettronico (funzione ROW()):
=index(importxml("http://urldellapaginaweb.com/nomepagina";
"//div[@class='NOMECLASSE']//td");ROW())
Una formula come quella seguente può sembrare complicata, in realtà importerà il contenuto delle tag td con indice 1, 5, 9, 13 e così via:
=index(importxml("http://urldellapaginaweb.com/nomepagina";
"//div[@class='NOMECLASSE']//td");4*(ROW()-1)+1)
Niente male vero?
È importante tenere presente che tutte le formule, comprese quelle presentate in questo articolo, vanno incollate su un’unica riga.
/https://www.ilsoftware.it/app/uploads/2026/07/codex-security-cli.jpg "OpenAI rilascia in segreto Codex Security CLI, per trovare falle nel codice")
/https://www.ilsoftware.it/app/uploads/2024/11/boot-windows-98.png "98.css riporta il look di Windows 98 nei siti web moderni")
/https://www.ilsoftware.it/app/uploads/2026/07/SIMD-CPU.jpg "SIMD spiegato bene: perché può accelerare davvero il software")
/https://www.ilsoftware.it/app/uploads/2026/07/accordo-mistral-microsoft-AI-europea.jpg "Microsoft e Mistral rafforzano l'AI europea: modelli e GPU dal cloud agli ambienti disconnessi")