/https://www.ilsoftware.it/app/uploads/2023/05/img_23086.jpg "Come funziona un processore")
I moderni processori sono ordini di grandezza più complessi rispetto alla trattazione “per sommi capi” scelta per questo articolo: sono il risultato di oltre trent’anni di continui progressi tecnici e tecnologici. I concetti generali rimangono però sempre gli stessi e la loro comprensione è utile per capire come funzionano i processori che equipaggiano tutti i sistemi che utilizziamo ogni giorno.
I computer, infatti, comprendono il linguaggio macchina a sua volta basato sul codice binario: ciò significa che sono in grado di utilizzare soltanto un “alfabeto” composto da 0 e 1. Al di sopra del linguaggio macchina sono stati sviluppati linguaggi di programmazione ad alto livello che introducono una significativa astrazione dei dettagli del funzionamento di un calcolatore e permettono una più semplice interazione con la macchina.
A un livello più alto rispetto al linguaggio macchina si pone Assembly: ne abbiamo parlato nell’articolo incentrato su codice binario, bit e byte.
Assembly è comunque un linguaggio decisamente più ostico rispetto ai linguaggi ad alto livello perché implica l’utilizzo di riferimenti diretti al contenuto dei registri del processore e della memoria (vedere più avanti).
Il vantaggio derivante dai linguaggi ad alto livello è che essi adottano una sintassi e uno specifico insieme di regole, sono intuitivi da usare, il codice può essere generalmente compilato su più architetture diverse ed è quindi possibile ottenere il codice macchina senza dover riscrivere il codice ad alto livello.
Con Assembly, invece, struttura e sintassi sono legate a doppio filo con ciascuno specifico tipo di processore.
Le istruzioni da utilizzare in Assembly sono diverse sulla base della Instruction Set Architecture (ISA) sulla quale poggia il processore, ad esempio x86, x86-64, ARM, RISC-V e così via. In altri articoli parliamo delle differenze tra architetture x86 e ARM, dello storico ruolo rivestito dalla piattaforma x86 e del perché sia rimasta feudo di Intel e AMD, della promettente ISA RISC-V contraddistinta da uno schema aperto e da un limitato numero di istruzioni (circa un centinaio quando x86 ne prevede circa 10.000).
Un linguaggio di programmazione ad alto livello non fa altro che convertire le istruzioni fornite utilizzando strutture e sintassi più comprensibili “agli umani” in Assembly e poi in codice macchina, l’unica lingua che il processore è in grado di capire.
Ciò che vale la pena evidenziare è che, ad esempio, una semplice istruzione scritta con differenti linguaggi ad alto livello sarà alla fine trasformata nella stessa sequenza di 0 e 1.
Di base, infatti, un elaboratore informatico comprende soltanto due stati: acceso e spento.
Il transistor, la base del funzionamento di tutti i processori, e le porte logiche
Per eseguire i calcoli in binario vengono usati i transistor: si tratta di semiconduttori che permettono il passaggio di corrente solo quando c’è corrente sul terminale chiamato gate. Il gate è il terminale di controllo ma ne esistono altri due o tre: source, drain e bulk.
Source è l’ingresso, drain l’uscita mentre bulk è il substrato generalmente connesso al source.
Applicando una tensione sul gate si forma un canale che permette agli elettroni di fluire dal source al drain attraversando il semiconduttore.
Si tratta di interruttori binari che si aprono o si chiudono al passaggio della corrente sulla base di un secondo segnale in ingresso.
I computer moderni usano miliardi di transistor per eseguire i calcoli ma per eseguire le operazioni fondamentali ne servono soltanto una manciata.
Combinando più transistor si ottiene ciò che viene chiamato porta logica: essa utilizza due ingressi binari, esegue un’operazione sui valori in ingresso e restituisce un output.
La porta OR, per esempio, restituisce vero se uno dei due ingressi è vero; AND controlla se entrambi gli ingressi sono veri, XOR verifica se solo uno degli ingressi è vero mentre le varianti N (NOR, NAND e XNOR) sono versioni invertite delle porte logiche di base.
Il comportamento di ciascuna porta logica si rispecchia nelle cosiddette tabelle di verità: esse mostrano ciò che si ottiene in uscita a seconda degli ingressi.
Provate a usare lo strumento online Logic.ly. Uno schema come il seguente permette di creare il cosiddetto semisommatore (half-adder) usando una porta XOR e una AND.
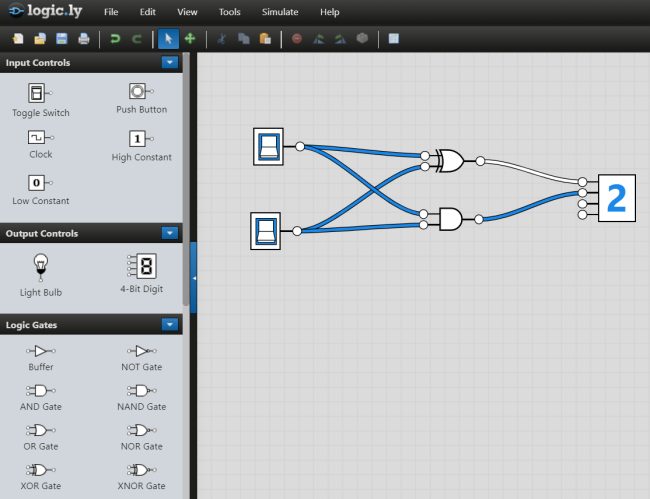
Le due porte consentono di ottenere la somma dei due bit in ingresso ed esporta in uscita.
La porta XOR si attiva se uno solo degli ingressi è acceso ma non entrambi. La porta AND si accende se entrambi gli ingressi sono attivi ma rimane spenta se non c’è nessun ingresso.
Se entrambi gli ingressi sono accesi lo XOR rimane spento e la porta AND si accende quindi in uscita si ottiene correttamente la somma 2.
L’insieme di due half-adder e una porta logica OR opportunamente collegati permette di realizzare un full-adder per eseguire la somma tra due numeri espressi in formato binario.
Il full-adder consta di tre ingressi e due uscite. In ingresso si hanno i due valori da sommare e un riporto (carry in). Quest’ultimo viene usato quando il numero finale supera quello che può essere memorizzato in un singolo bit.
I full-adder vengono combinati a formare una catena e il riporto viene passato da un addizionatore al successivo (ecco perché si ha un carry out come seconda uscita).
Il riporto viene aggiunto al risultato della porta XOR in un primo half-adder ed è previsto l’utilizzo di una porta OR aggiuntiva per gestire entrambi i casi in cui il così dovrebbe essere acceso.
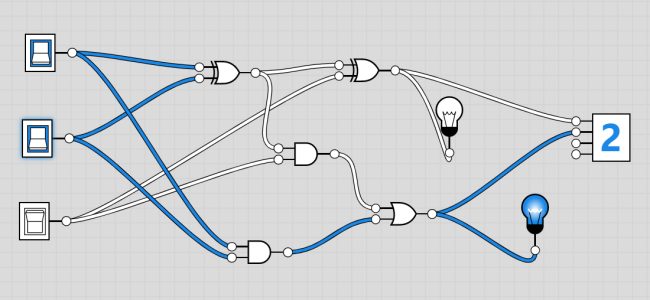
Quando entrambi gli ingressi sono attivi, il carry out si accende e invia il valore al sommatore successivo nella catena. Aggiungere più bit implica “semplicemente” inserire più full-adder in una catena ancora più lunga.
La maggior parte delle operazioni matematiche possono essere fatte ricorrendo all’addizione; la moltiplicazione, infatti, è solo un’addizione ripetuta mentre la sottrazione può concretizzarsi usando le inversioni di bit. Infine, la divisione è solo sottrazione ripetuta.
Tutti i computer moderni poggiano su soluzioni in hardware per accelerare le operazioni più avanzate ma dal punto di vista meramente tecnico si può fare tutto con l’ausilio di full-adder opportunamente combinati in “catene” più lunghe e articolate.
Cosa sono e a che cosa servono i registri del processore
Utilizzando soltanto le porte logiche come appena descritto si crea una calcolatrice che non mantiene nulla in memoria e non svolge alcuna operazione con i risultati ottenuti come output. In realtà un computer si serve di un ampio numero di porte NAND che permettono di scrivere i bit e mantenerli memorizzati accendendo all’apposito bit di scrittura.
Per leggere i valori memorizzati viene utilizzato un insieme di porte AND per ciascun bit della memoria (enabler).
Tutto questo pacchetto è racchiuso in quello che è conosciuto come registro.
I registri del processore sono collegati al bus, un canale di comunicazione che corre all’interno del sistema ed è collegato a ogni componente. Essi hanno il ruolo di consentire il flusso dei dati da un luogo all’altro e memorizzare valori.
Ogni registro ha ancora un bit di scrittura e di lettura ma in questa configurazione l’ingresso e l’uscita sono la stessa cosa.
Se si volesse copiare il contenuto del registro R1 in R2 si accende il bit di lettura (enable) per R1. Il contenuto di R1 viene immesso sul bus e accendendo il bit di scrittura (set) per R2 la configurazione di R1 viene effettivamente copiata in R2.
Cos’è il clock di un processore
Il clock di un processore è un valore che esprime il numero di cicli che possono essere eseguiti in un secondo (si misura in Hertz). Un chip da 5 GHz può eseguire 5 miliardi di cicli al secondo.
Il clock ha tre stati diversi: il clock di base, enable e set. Il primo risulta attivo per metà ciclo e spento per l’altra metà; il secondo è usato per attivare i registri e dovrà essere acceso più a lungo per assicurarsi che i dati siano disponibili; il terzo deve essere sempre attivato in contemporanea con l’enable clock altrimenti potrebbero essere scritti dei dati non corretti.
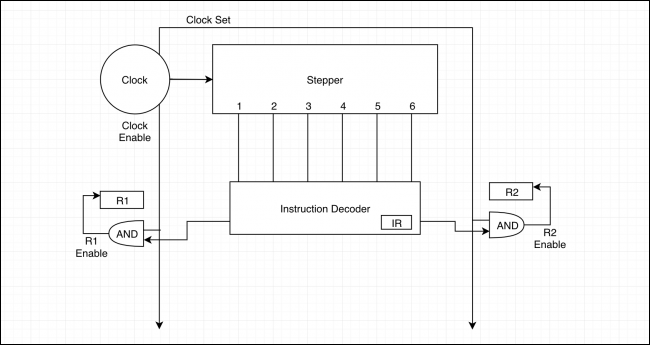
Il clock è collegato allo stepper che effettua un conteggio da 1 fino al passo massimo impostato reimpostandosi automaticamente al termine di ciascuna attività. È inoltre collegato a porte AND per ogni registro sulle quali la CPU può scrivere.
Le porte AND sono a loro volta collegate con l’uscita di un componente detto instruction decoder: esso ha il compito di prendere un’istruzione e trasformarla (operazione di decodifica) in qualcosa che può essere compreso dalla CPU. Il registro interno, chiamato Instruction Register, memorizza l’operazione corrente.
Le istruzioni del programma da eseguire sono memorizzate nella RAM (o nella cache L1 nei sistemi moderni, più vicina alla CPU). Poiché i dati del programma sono memorizzati nei registri, proprio come ogni altra variabile, essi possono essere manipolati “al volo”.
Si pensi alle strutture comunemente utilizzate nei programmi (istruzioni if e cicli): un’istruzione di salto imposta la posizione corrente nella memoria che l’instruction decoder sta leggendo in una posizione diversa.
I salti sono tra l’altro gestiti usando un’unità “ad hoc” chiamata Branch Prediction Unit (BPU): se è parlato tanto da gennaio 2018 in avanti perché fu proprio allora che un gruppo di ricercatori porto il “grande pubblico” a conoscenza delle vulnerabilità legate all’esecuzione speculativa.
In pratica furono evidenziate alcune “leggerezze” nella gestione del meccanismo che si occupa di indovinare con anticipo quale percorso seguirà il flusso di esecuzione di un programma. Se l’ipotesi dovesse rivelarsi corretta il processore avrà risparmiato tempo prezioso perché il risultato sarà già stato scritto in memoria; diversamente dovrà tornare a ritroso al salto e seguire la diramazione corretta. Per approfondire suggeriamo la lettura dell’articolo che avevamo pubblicato a distanza di un anno dalla scoperta di Spectre e Meltdown, le prime di una lunga serie di vulnerabilità di sicurezza emerse nei processori relativamente all’esecuzione speculativa, per capire se gli aggiornamenti contro le falle nei processori siano davvero indispensabili.
I full-adder, insieme con tante altre operazioni, sono “impacchettati” nell’unità aritmetica e logica (ALU): essa dispone di connessioni al bus e dei suoi registri per memorizzare il secondo numero sul quale sta operando.
Per eseguire un calcolo, i dati del programma vengono caricati dalla RAM di sistema (fase fetch) nella sezione di controllo (control unit). Quest’ultima legge due valori dalla RAM, carica il primo nel registro delle istruzioni della ALU e poi il secondo sul bus. Nel frattempo invia all’ALU un instruction code per impartire il compito da eseguire. L’ALU esegue quindi tutti i calcoli e memorizza il risultato in un registro diverso che la CPU può leggere per poi continuare il processo.
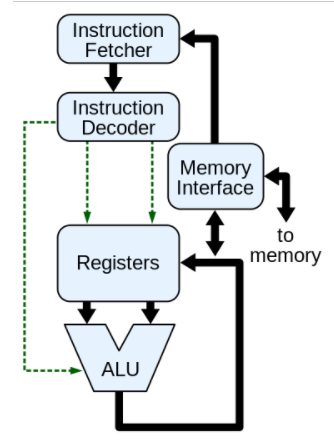
Un singolo ciclo di clock è quindi composto da quattro fasi separate: fetch, decode, execute e store che si riferiscono all’estrazione del dato dalla memoria, alla decodifica dell’operazione che il processore deve effettuare, l’esecuzione all’interno dell’ALU e di calcolo del risultato e infine la memorizzazione dell’output in memoria.
Per ogni ciclo di clock si verifica un cambio di stato di tutti i transistor nel processore oppure di una parte di essi. Il clock è insomma una sorta di metronomo che scandisce il tempo e definisce la finestra entro la quale i transistor devono aver ultimato le operazioni richieste. Ecco perché un overclock troppo spinto, quando si esagera con la tensione in ingresso sul processore, anziché velocizzare le performance contribuisce a rendere instabile il sistema e può portare al danneggiamento del processore stesso.
Va detto che i moderni processori usano un meccanismo chiamato pipeline che permette di non aspettare la conclusione di un ciclo di clock per eseguire nuove operazioni. Inoltre è possibile gestire più operazioni per ciclo di clock tenendo presente che un singolo ciclo di clock può comunque non essere sufficiente per concludere un’operazione.
Il Simultaneous Multi-Threading (SMT) è proprio questo ovvero l’abilità del processore di eseguire contemporaneamente più operazioni esaltando le capacità di parallelizzazione.
Nel processo di realizzazione di un processore il primo passo non viene però compiuto dagli ingegneri ma dal management che negozia contratti multimilionari con le diverse fonderie e fa le diverse previsioni in termini di livello di produzione e costi da sostenere. Le specifiche complessive e i costi del nodo di produzione suggeriranno ai tecnici l’area a disposizione per creare il chip, il numero di transistor utilizzabili e i tempi di sviluppo per arrivare a concepire un nuovo design.
Ma come fanno i produttori di processori a condensare miliardi di transistor in pochi centimetri quadrati? Ne parleremo in un prossimo articolo.
/https://www.ilsoftware.it/app/uploads/2026/03/intel-core-ultra-series-3-processori-business.jpg "Intel Core Ultra Series 3: AI, vPro e nuovo nodo 18A cambiano i PC aziendali")
/https://www.ilsoftware.it/app/uploads/2026/03/chip-arm-agi-cpu.jpg "Arm entra nel silicio: perché la nuova AGI CPU cambia i data center AI")
/https://www.ilsoftware.it/app/uploads/2026/03/APU-AMD-nuova-generazione-medusa-point.jpg "AMD Zen 6 Medusa Point: leak svela CPU mobile a 10 core")
/https://www.ilsoftware.it/app/uploads/2026/03/CPU-Intel-Core-Ultra-270K-Plus-250K-Plus.jpg "Intel lancia Core Ultra 270K Plus e 250K Plus: cosa cambia nel gaming")