/https://www.ilsoftware.it/app/uploads/2023/05/img_25805.jpg "Universal Speech Model, riconoscimento vocale automatico con oltre 300 lingue. Compreso l'italiano")
La presentazione di Google Bard, il chatbot che è in corso di integrazione con il motore di ricerca ha un po’ deluso le aspettative.
L’azienda di Mountain View ha però compiuto più di recente un deciso passo in avanti presentando Universal Speech Model (USM), uno strumento – utilizzabile tramite API – che abilita il riconoscimento vocale automatico a oltre 300 lingue.
Cos’è il riconoscimento vocale automatico
In un altro articolo abbiamo visto come dettare testi e attivare il riconoscimento vocale senza installare nulla.
Il riconoscimento vocale automatico (ASR) è una tecnologia che consente alle “macchine” di “comprendere” e trascrivere il parlato umano in testo scritto.
“Comprendere” è un verbo forte e non va inteso in senso letterale. Il processo ASR si basa sull’analisi delle caratteristiche del segnale vocale, come ad esempio la frequenza, l’intensità e la durata dei suoni emessi. I suoni acquisiti in digitale vengono analizzati e grazie a tecniche di apprendimento automatico e di intelligenza artificiale, la macchina può generare associazioni con le parole precedentemente fornite durante la fase di addestramento.
Con gli approcci convenzionali, i dati audio devono essere etichettati manualmente (apprendimento supervisionato): si tratta di un’operazione lunga e costosa. In alternativa si possono usare trascrizioni preesistenti che tuttavia sono molto difficili da trovare per le lingue prive di un’ampia rappresentazione.
L’apprendimento auto-supervisionato può sfruttare solo i dati audio che sono disponibili in quantità molto maggiori in tutte le lingue.
Universal Speech Model è una famiglia di modelli vocali all’avanguardia basati su 2 miliardi di parametri. I modelli sono stati addestrati a partire da 12 milioni di ore di parlato e 28 miliardi di frasi di testo in oltre 300 lingue.
USM, che viene utilizzato anche su YouTube per la generazione automatica dei sottotitoli, è in grado di comprendere anche lingue parlate da gruppi di persone non molto vasti.
I tecnici di Google spiegano che alcune lingue sono parlate da meno di venti milioni di persone, cosa che ha reso molto difficile reperire i dati di formazione necessari.
Il progetto USM, figlio dell’iniziativa 1.000 Languages presentata a novembre 2022 che mira a costruire un modello universale per supportare le mille lingue più parlate al mondo, ha permesso di dimostrare che l’utilizzo di un ampio set di dati multilingue ha permesso di gestire anche lingue sottorappresentate.
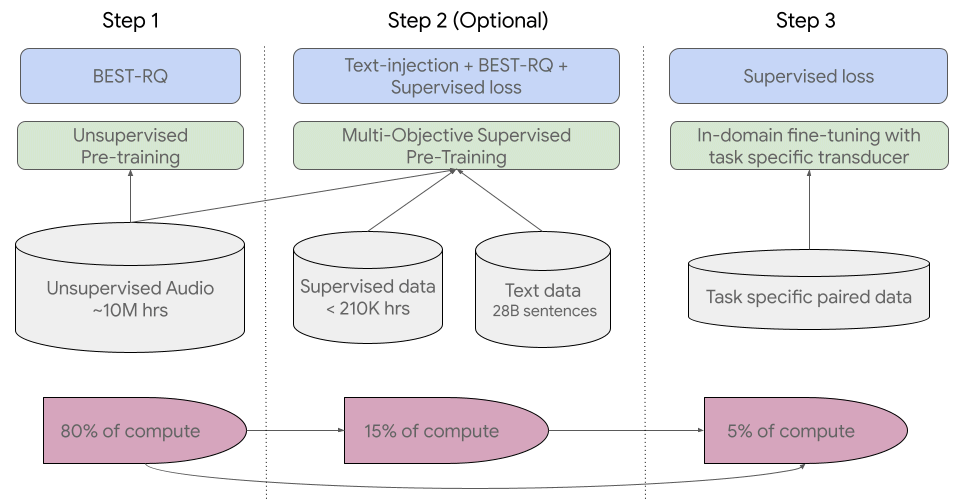
La “pipeline” dell’addestramento del modello usato da USM. Fonte: Google
“I dati di YouTube supervisionati includono 73 lingue e hanno in media meno di tremila ore di dati per lingua. Nonostante i dati supervisionati limitati, il modello raggiunge in media un tasso di errore di parole inferiore al 30% (WER; più basso è meglio) nelle 73 lingue, un traguardo che non abbiamo mai raggiunto prima“, spiegano i ricercatori di Google. Per l’inglese americano USM ha evidenziato un valore WER inferiore del 6% rispetto al migliore modello usato internamente dall’azienda di Mountain View.
Gli sviluppatori che volessero provare USM possono fare riferimento alla pagina ufficiale del progetto quindi fare clic sul pulsante Request API Access in alto.
/https://www.ilsoftware.it/app/uploads/2024/04/Corsi-online.jpg "Corsi online di Domestika: offerta a 5,99 euro per tutti")
/https://www.ilsoftware.it/app/uploads/2024/04/wasmer-compilare-python-wasm-codice.jpg "Compilare codice Python in WebAssembly: come fare e qual è l'utilità")
/https://www.ilsoftware.it/app/uploads/2024/04/blocco-cookie-terza-parte-chrome.jpg "Blocco dei cookie di terze parti Chrome: slitta ancora, a inizio 2025")
/https://www.ilsoftware.it/app/uploads/2024/04/javascript-cose-js-naked-day.jpg "JavaScript: il Web potrebbe farne a meno secondo gli organizzatori di JS Naked Day")