/https://www.ilsoftware.it/app/uploads/2026/06/ricerca-nomi-dominio-autocompletamento.jpg "Come ottenere un autocompletamento istantaneo su 240 milioni di domini Internet")
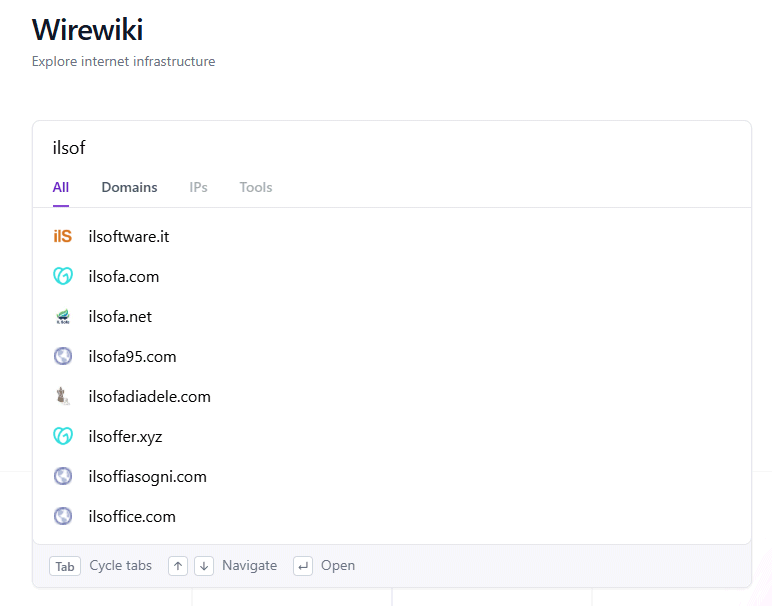
Come si può attivare una funzionalità di autocompletamento quasi istantanea utilizzando una base dati formata da circa 240 milioni di record?
A riuscire nell’impresa è stato lo sviluppatore Ruurtjan Pul, fondatore di Wirewiki, che ha allestito un meccanismo di ricerca in grado di individuare qualunque nome di dominio registrato sulla faccia della terra e restituire tutti i dati associati.
L’autocompletamento esiste da decenni e compare praticamente ovunque: motori di ricerca, editor di codice, sistemi DNS, piattaforme cloud e pannelli amministrativi. Ciò che rende interessante l’esperimento di Wirewiki non è soltanto la quantità di dati coinvolti, ma il tentativo di raggiungere una latenza percepita pari a zero per il 99% delle interazioni. Un obiettivo che richiede un approccio diverso rispetto alla semplice ottimizzazione del database o dell’infrastruttura.
Il trucco non è rendere tutto più veloce, ma anticipare l’utente
L’idea alla base del progetto ruota attorno a una tecnica di prefetching estremamente aggressiva.
Quando l’utente preme un tasto, il sistema avvia immediatamente una richiesta che recupera non solo i risultati relativi al prefisso corrente, ma anche quelli associati ai possibili caratteri successivi.
Ad esempio, durante la digitazione della sequenza git, il server riceve già una richiesta per gi mentre il secondo carattere è ancora in fase di pressione. Quando il tasto successivo viene rilasciato, gran parte delle informazioni necessarie risulta già disponibile nella cache locale del browser.
La conseguenza è interessante: la latenza continua a esistere, ma l’utente non la percepisce. I suggerimenti appaiono nel momento stesso in cui il carattere è visualizzato sullo schermo.
L’autore ha misurato il tempo che intercorre tra la pressione di un tasto e il rilascio del successivo durante la digitazione di cento domini differenti. I risultati mostrano una finestra operativa pari a circa 121 millisecondi al percentile 99. Significa che il sistema dispone di oltre un decimo di secondo per completare l’intera operazione senza che l’utente percepisca alcun ritardo.
Come cercare tra 240 milioni di domini senza rallentamenti
Una volta definito il budget temporale, resta il problema principale: interrogare un archivio enorme senza introdurre colli di bottiglia.
Wirewiki utilizza due strutture dati differenti. La prima contiene i domini più popolari estratti dalla classifica Tranco, che raccoglie circa un milione di siti ad alto traffico. Per questa sezione il sistema sfrutta un trie, ovvero un albero prefissato che consente di individuare rapidamente tutte le stringhe che condividono gli stessi caratteri iniziali.
Ogni nodo memorizza in anticipo gli 8 suggerimenti più rilevanti: la ricerca richiede semplicemente di percorrere alcuni puntatori seguendo i caratteri digitati. Il costo computazionale dipende quasi esclusivamente dalla lunghezza della query.
Per i restanti centinaia di milioni di domini il progetto adotta una soluzione diversa. I dati sono archiviati su SSD attraverso una struttura indicizzata composta da blocchi compressi e ordinati lessicograficamente. L’indice principale occupa circa 27 MB in memoria, mentre l’intero archivio raggiunge circa 2,5 GB di spazio disco.
La ricerca avviene tramite una combinazione di ricerca binaria sull’indice e scansione locale di blocchi contenenti 256 record: per ogni blocco viene memorizzata una chiave di riferimento all’interno di un indice residente in memoria. L’operazione di ricerca binaria individua rapidamente il blocco che contiene il prefisso desiderato: a quel punto il sistema legge soltanto il segmento necessario dall’unità SSD.
Il ruolo della cache e della rete globale
La piattaforma utilizza Cloudflare come livello intermedio tra browser e server applicativo. Le richieste attraversano quindi browser, edge network, proxy Nginx e applicazione di backend.
Secondo i test pubblicati, l’API riesce a rispondere nella maggior parte dei casi in circa 2 millisecondi. Anche con carichi superiori a 1.600 richieste al secondo, il percorso completo tra Nginx e applicazione mantiene il percentile 99 intorno ai 15 millisecondi.
Ovviamente, se la connessione tra utente finale e data center aggiunge decine di millisecondi, migliorare ulteriormente il backend – ad esempio per ridurre il tempo di elaborazione da 2 a 1 millisecondo – cambia ben poco.
Il risultato più interessante del progetto, comunque utilissimo anche per raccogliere informazioni sui nomi di dominio, non riguarda i 240 milioni di record archiviati né le prestazioni dell’infrastruttura. La vera intuizione consiste nell’aver trasformato il tempo che normalmente consideriamo “morto” in una risorsa da utilizzare a proprio vantaggio e a beneficio dell’esperienza utente.
/https://www.ilsoftware.it/app/uploads/2026/06/directx-dump-files-crash-gpu.jpg "DirectX Dump Files: Microsoft semplifica il debug dei crash GPU")
/https://www.ilsoftware.it/app/uploads/2026/06/metodo-query-http.jpg "HTTP cambia dopo oltre 30 anni: arriva QUERY, il nuovo metodo che affianca GET e POST")
/https://www.ilsoftware.it/app/uploads/2026/06/amazon-echo-show-5-monitoraggio-rete-dashboard.jpg "Credevano fosse da buttare: oggi questo Echo Show monitora un'intera rete")
/https://www.ilsoftware.it/app/uploads/2026/06/emulatore-windows-microsoft.jpg "Quando il compilatore generò 65.000 istruzioni inutili e Microsoft intervenne sull'emulatore")