/https://www.ilsoftware.it/app/uploads/2024/04/RAG-intelligenza-artificiale-RAGFlow.jpg "RAG, portare l'intelligenza artificiale in azienda e migliorare il business con RAGFlow")
Un RAG (Retrieval-Augmented Generation) è un tipo di modello di linguaggio che combina tecniche di recupero e generazione per produrre contenuti. Può essere un po’ considerato come l’evoluzione dei modelli generativi, ad esempio GPT (Generative Pre-trained Transformer), che sono in grado di generare testo coerente e comprensibile in base al contesto fornito. Ricorrendo al RAG, il modello può accedere a informazioni specifiche da una fonte esterna durante il processo di generazione.
Il modello utilizza un sistema di recupero delle informazioni per estrarre documenti rilevanti da un corpus di testo. Questi documenti fungono da “fonte di conoscenza” per il modello.
Il processo di recupero e generazione può essere ripetuto più volte per migliorare la qualità del testo prodotto. È possibile inoltre raffinare le risposte sulla base di feedback o di metriche di valutazione prestabilite.
A cosa serve un RAG
Il RAG può essere utilizzato in molteplici campi applicativi: abbiamo già detto che può essere sfruttato in contesti di domanda-risposta dal momento che può utilizzare informazioni estratte da fonti esterne per arricchire le risposte generate, fornendo così contenuti più dettagliati e accurati.
In ambito aziendale o di ricerca, il RAG può essere utilizzato per fornire aiuto nel processo decisionale, proponendo informazioni contestualmente rilevanti estratte da un ampio volume di dati.
In generale, quindi, il RAG unisce i vantaggi della generazione di contenuti in linguaggio naturale con l’accesso a fonti esterne di conoscenza, consentendo la produzione di testo più informativo e contestualmente accurato.
![]()
Cos’è RAGFlow e come funziona
RAGFlow è un motore open source RAG che permette di attivare una “comprensione profonda” dei documenti aziendali. Il funzionamento di RAGFlow è ottimizzato per le imprese di qualsiasi dimensione: accoppia l’uso dei Large Language Models (LLM) con le informazioni specifiche acquisite dai dati aziendali. I riferimenti e le citazioni di dati complessi completano il quadro, facendo emergere le informazioni rilevanti per ciascuna attività e realtà aziendale.
La comunità di sviluppo di RAGFlow mette in evidenza il fatto che, grazie a questo strumento, è letteralmente possibile trovare l’ago nel pagliaio. In un oceano di token (pensati come parole o raggruppamenti di esse), RAGFlow aiuta a estrarre conoscenza basandosi sulla comprensione profonda dei documenti da dati non strutturati, anche con formati complicati.
Una dimostrazione del funzionamento di RAGFlow è pubblicamente accessibile previa registrazione o effettuando il login con un account GitHub. È possibile toccare con mano i vantaggi della piattaforma prima di installarla e servirsene in locale.
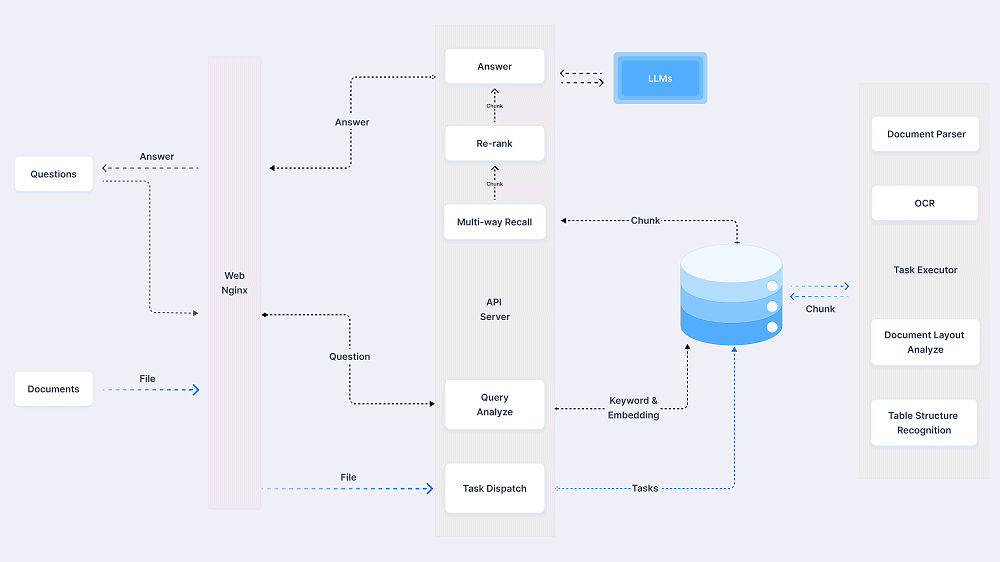
Schema del funzionamento di RAGFlow.
Chunking personalizzabile e modelli già pronti
Il chunking è un processo di linguistica computazionale che coinvolge la suddivisione di una frase o un testo in unità semantiche più piccole e significative, chiamate appunto chunk o “frammenti”. Sono gruppi di parole correlate che formano una parte della struttura grammaticale o semantica più ampia della singola frase.
Con il chunking si possono individuare e raggruppare parole o token all’interno di un testo che condividono un significato o una funzione simile. Questo processo aiuta a semplificare la comprensione del testo: RAGFlow lo sfrutta per far venire a galla informazioni rilevanti dai documenti non strutturati e per presentare queste informazioni in modo comprensibile e utilizzabile per rispondere alle domande degli utenti o per generare nuovi contenuti.
L’approccio di RAGFlow consiste nell’offrire un chunking basato su template tra i quali è possibile scegliere. Gli utenti hanno ampie possibilità di personalizzazione, avendo modo di accedere a una vista rapida dei riferimenti chiave e delle citazioni, tutte tracciabili. Le API (Application Programming Interface) intuitive di RAGFlow si integrano senza soluzione di continuità con l’attività.
Come installare e usare RAGFlow
Il sistema alla base del funzionamento di RAGFlow poggia su Docker e richiede almeno l’utilizzo di una CPU dual core e di 8 GB di memoria RAM. Docker, ovviamente, deve risultare installato sulla macchina locale. Suggeriamo di fare riferimento alle indicazioni per l’installazione di Docker Engine.
Prima di clonare il repository GitHub di RAGFlow, è necessario assicurarsi che il parametro vm.max_map_count sia superiore a 65535. Si tratta di un parametro del kernel Linux che controlla il numero massimo di aree di memoria mappate che ciascun processo può gestire. È importante per le applicazioni che richiedono un utilizzo intensivo della memoria mappata per l’indicizzazione e il recupero dei dati. La mappatura della memoria è un metodo utilizzato per ottimizzare l’accesso ai dati e per consentire ai processi di interagire in modo efficiente con grandi quantità di dati.
Il comando seguente, permette di verificare l’impostazione del parametro:
sysctl vm.max_map_count
Di seguito, lo impostiamo a 262144:
sudo sysctl -w vm.max_map_count=262144
Per fare in modo che la modifica sia conservata dopo ciascun riavvio, è sufficiente aggiungere la riga seguente nel file /etc/sysctl.conf (o comunque modificarla in modo opportuno):
vm.max_map_count=262144
Clonazione del repository e avvio di RAGFlow
Iniziare a usare RAGFlow nell’ambito della propria attività è molto semplice: si comincia con la clonazione del repository (git clone https://github.com/infiniflow/ragflow.git) quindi si prosegue con l’avvio del server e il boot dell’immagine Docker:
cd ragflow/docker
docker compose up -d
L’immagine pesa all’incirca 15 GB: è quindi piuttosto voluminosa e potrebbe necessitare di un po’ di tempo per essere correttamente e completamente caricata. Il comando seguente permette di verificare che il software sia in esecuzione e pronto per ricevere indicazioni:
docker logs -f ragflow-server
L’indirizzo IP locale mostrato nell’output di RAGFlow, consente di accedere alla sua interfaccia: basta digitarlo nella barra degli indirizzi del browser Web.
Nel file service_conf.yaml, all’interno della sezione user_default_llm, è necessario specificare il LLM da usare come “base” e la relative chiave API (API_KEY). RAGFlow ne supporta alcuni ma altri sono in arrivo nel breve termine. L’API Key può essere impostata anche attraverso l’interfaccia Web dell’applicazione.
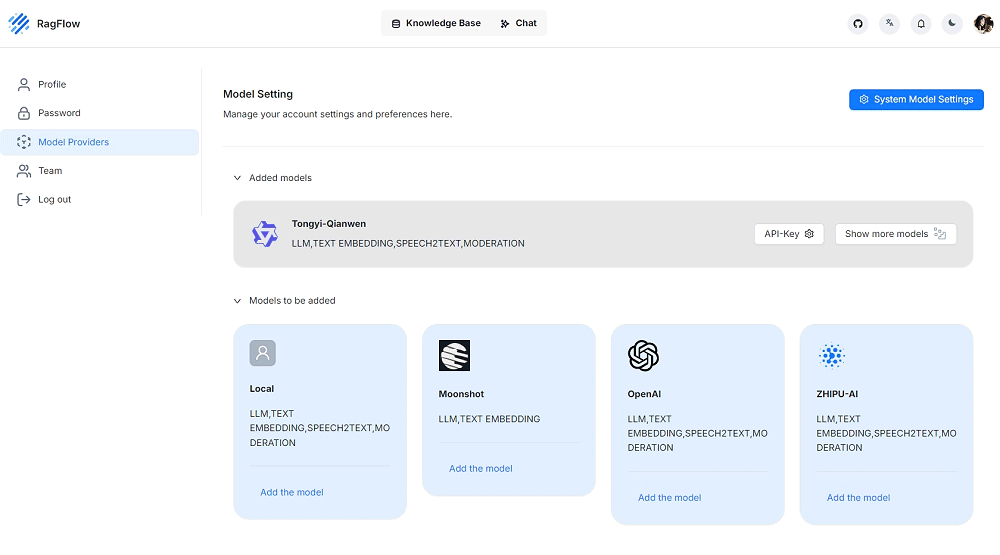
Al paragrafo Configurations della guida ufficiale, si trovano alcune indicazioni utile per modificare, ad esempio, la porta sulla quale è in ascolto RAGFlow, quella per l’accesso al database MySQL e la password utile al fine di interagire con MinIO, server di archiviazione ad oggetti ad alte prestazioni che offre un’alternativa open source e self-hosted a servizi come Amazon S3.
Maggiori informazioni su RAGFlow sono reperibili sul sito ufficiale del progetto.
/https://www.ilsoftware.it/app/uploads/2025/05/anthropic-claude-system-prompt.jpg "Anthropic accusa Alibaba: avrebbe copiato Claude con milioni di query")
/https://www.ilsoftware.it/app/uploads/2024/06/openai-multi-acquisizione.jpg "OpenAI lancia un'anteprima di GPT-5.6 accessibile a pochi")
/https://www.ilsoftware.it/app/uploads/2023/07/usa-flag-stati-uniti.jpg "Casa Bianca chiede a OpenAI di rallentare il rilascio del suo nuovo modello AI?")
/https://www.ilsoftware.it/app/uploads/2026/06/OCR-multipagina-AI-Unlimited-OCR.jpg "Unlimited-OCR promette di leggere decine di pagine in un colpo solo")