/https://www.ilsoftware.it/app/uploads/2026/04/gemma-4-google.jpg "Google Gemma 4 arriva come modello open source: cosa può fare davvero")
La diffusione dei modelli linguistici (LLM, Large Language Models) aperti ha cambiato il modo in cui sviluppatori e aziende costruiscono applicazioni basate su intelligenza artificiale. Dalla prima release di Gemma nel 2024 fino alla terza generazione nel 2025, Google DeepMind ha progressivamente ridotto i requisiti hardware mantenendo capacità avanzate di comprensione e generazione del linguaggio. Con Gemma 4 (pagina di riferimento) si compie un ulteriore passo avanti presentando modelli progettati per funzionare in modo efficiente su dispositivi eterogenei, dal data center fino allo smartphone, senza rinunciare a funzioni di reasoning e coding sempre più sofisticate.
Il percorso evolutivo della famiglia Gemma aiuta a comprendere la portata di questa nuova versione. I primi modelli, basati su architetture transformer decoder-only simili a quelle utilizzate in Gemini, introducevano varianti da 2 e 7 miliardi di parametri pensate rispettivamente per CPU e GPU. Con Gemma 3, Google aveva già dimostrato la possibilità di eseguire modelli con finestre di contesto fino a 128K token su una singola GPU. Gemma 4 prosegue su questa linea, puntando a una maggiore efficienza computazionale e a un uso più diffuso in ambienti reali.
Architettura e ottimizzazione: modelli open più compatti ma avanzati
Gemma 4 rientra nella categoria degli open-weight model: Google distribuisce i pesi delle reti neurali, permettendo download, esecuzione locale e fine-tuning. La struttura resta basata su transformer ottimizzati, ma con interventi mirati sulla gestione della memoria e sull’inferenza.
Un elemento particolarmente importante è l’ottimizzazione per dispositivi di uso comune, come computer portatili e smartphone. I modelli possono funzionare anche su questi device grazie a tecniche come la quantizzazione avanzata, che riduce la precisione numerica dei calcoli per diminuire il consumo di memoria, e a una gestione più efficiente dei livelli di attenzione (i meccanismi che permettono al modello di concentrarsi sulle informazioni più rilevanti). In questo modo si riduce l’uso complessivo di memoria senza penalizzare in modo significativo l’accuratezza e la capacità di elaborare informazioni complesse.
Le varianti disponibili coprono più scenari: modelli compatti per inferenza locale, versioni più estese per ambienti server e configurazioni ibride pensate per orchestrare task complessi. È una modularità che consente di adattare il modello al carico computazionale disponibile, evitando sprechi di risorse.
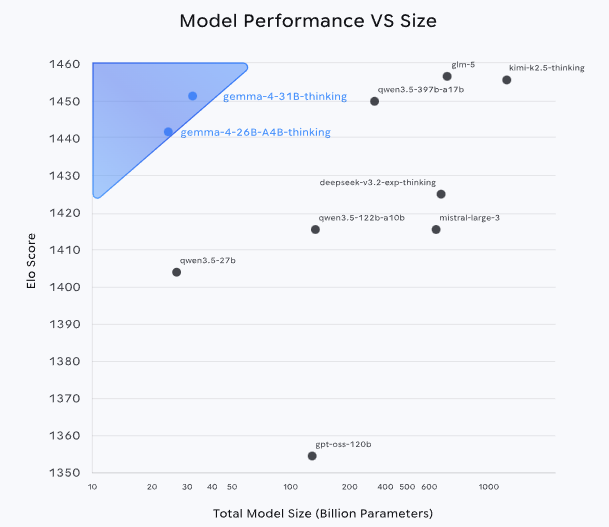
Capacità di reasoning e coding: cosa cambia
Gemma 4 introduce miglioramenti significativi nelle attività di reasoning, ossia nella capacità di elaborare informazioni in modo strutturato e coerente. Il modello riesce a gestire sequenze logiche più lunghe e a mantenere consistenza nelle risposte, anche quando il contesto cresce.
Un altro ambito chiave riguarda il codice. Le prestazioni in generazione e analisi di script migliorano grazie a dataset di addestramento più ampi e a tecniche di fine-tuning mirate. Il risultato si traduce in output più accurati per linguaggi come Python, JavaScript e C++, con una riduzione degli errori sintattici e semantici.
Il supporto a task reali, come la gestione di workflow applicativi o la trasformazione di dati, evidenzia un’evoluzione verso modelli utilizzabili non solo per generazione testuale, ma anche come componenti operativi all’interno di sistemi software.
Esecuzione locale e controllo dei dati
Uno degli elementi distintivi di Gemma 4 riguarda la possibilità di eseguire il modello completamente offline. Lo sviluppatore scarica in locale i pesi del modello (cioè i parametri già addestrati che ne determinano il comportamento) ed esegue l’inferenza, ovvero il processo con cui il modello genera risposte o previsioni, senza dover utilizzare servizi o API esterne. L’approccio porta vantaggi concreti: riduzione dei costi, latenza più bassa e maggiore controllo sui dati.
La gestione locale elimina il problema del trasferimento di informazioni sensibili verso servizi cloud. In ambito aziendale, ciò consente di sviluppare sistemi di supporto interno, chatbot o strumenti di analisi mantenendo i dati all’interno dell’infrastruttura.
Resta comunque il limite legato alle risorse hardware disponibili: modelli più grandi richiedono GPU con memoria adeguata, mentre le versioni ottimizzate per dispositivi mobili sacrificano parte della precisione per garantire fluidità operativa.
Dal data center allo smartphone: un modello multi-piattaforma
Gemma 4 nasce con una logica chiaramente multi-piattaforma.
Le varianti della famiglia coprono ambienti molto diversi: cluster GPU, workstation locali e dispositivi portatili. L’obiettivo consiste nel rendere l’intelligenza artificiale accessibile anche a sviluppatori indipendenti o piccoli team, senza necessità di infrastrutture complesse.
La capacità di funzionare su smartphone apre scenari interessanti: assistenti offline, strumenti di traduzione in tempo reale e applicazioni embedded. In questi casi, l’ottimizzazione energetica diventa cruciale: il modello deve bilanciare prestazioni e consumo, evitando impatti negativi sull’autonomia del dispositivo.
La distribuzione su più piattaforme richiede anche un adattamento delle librerie di inferenza. Framework come TensorFlow Lite o runtime specifici per AI edge permettono di eseguire modelli ridotti, mantenendo tempi di risposta accettabili.
Sicurezza, limiti e implicazioni per gli sviluppatori
Google integra componenti come classificatori per il rilevamento di contenuti non conformi, già presenti in varianti come ShieldGemma. Tuttavia, l’esecuzione locale lascia maggiore responsabilità agli sviluppatori, che devono implementare controlli adeguati.
Dal punto di vista tecnico, persistono alcune limitazioni: la qualità delle risposte può degradare con input particolarmente complessi, mentre la gestione di contesti estremamente lunghi resta un’area in evoluzione. Inoltre, la quantizzazione spinta, necessaria per l’esecuzione su dispositivi leggeri, introduce inevitabili compromessi in termini di precisione delle risposte ottenibili.
Nonostante questi limiti, Gemma 4 segna un passaggio importante: modelli avanzati diventano realmente utilizzabili senza infrastrutture costose. Per chi sviluppa applicazioni AI, cambia il punto di equilibrio tra prestazioni, costi e controllo dei dati; una combinazione che apre possibilità concrete anche fuori dai grandi ambienti cloud.
/https://www.ilsoftware.it/app/uploads/2026/04/claude-code-unpacked.jpg "Claude Code spiegato: guida visiva alle funzionalità")
/https://www.ilsoftware.it/app/uploads/2026/04/stampante-termica-open-source-smart.jpg "PC-1, Stampante termica open source locale: niente cloud né abbonamenti")
/https://www.ilsoftware.it/app/uploads/2026/04/caratteristiche-sorprendenti-claude-code.jpg "Dentro il leak Claude Code: dettagli tecnici sorprendenti")
/https://www.ilsoftware.it/app/uploads/2026/03/axios-npm-compromesso.jpg "Axios compromesso: rischio enorme per milioni di progetti open source")