/https://www.ilsoftware.it/app/uploads/2025/08/GPU-NVIDIA-Blackwell-Ultra.jpg "GPU NVIDIA Blackwell Ultra: inferenza AI su larga scala con NVFP4 e PCIe 6.0")
La domanda globale di potenza computazionale AI cresce esponenzialmente e, dal canto suo, NVIDIA risponde ampliando i confini della capacità hardware, potenziando la precisione e riducendo la latenza dei modelli utilizzati per l’inferenza su grande scala. Blackwell Ultra, la nuova punta di diamante delle GPU per data center e AI, è progettata per guidare l’era dell’AI reasoning e delle cosiddette AI factory.
NVIDIA Blackwell Ultra: all’avanguardia per il calcolo AI con NVFP4 e PCIe 6.0
NVIDIA Blackwell Ultra rappresenta la nuova frontiera nelle GPU accelerate per l’intelligenza artificiale, offrendo innovazioni significative sia a livello di architettura che di supporto di sistema.
Con un design dual-reticle che integra due die da 208 miliardi di transistor, questa GPU spinge le prestazioni di calcolo per l’addestramento e l’inferenza AI a nuovi livelli, grazie a caratteristiche come il formato di precisione low-bit NVFP4 e la connettività PCI Express 6.0 a 256 GB/s.
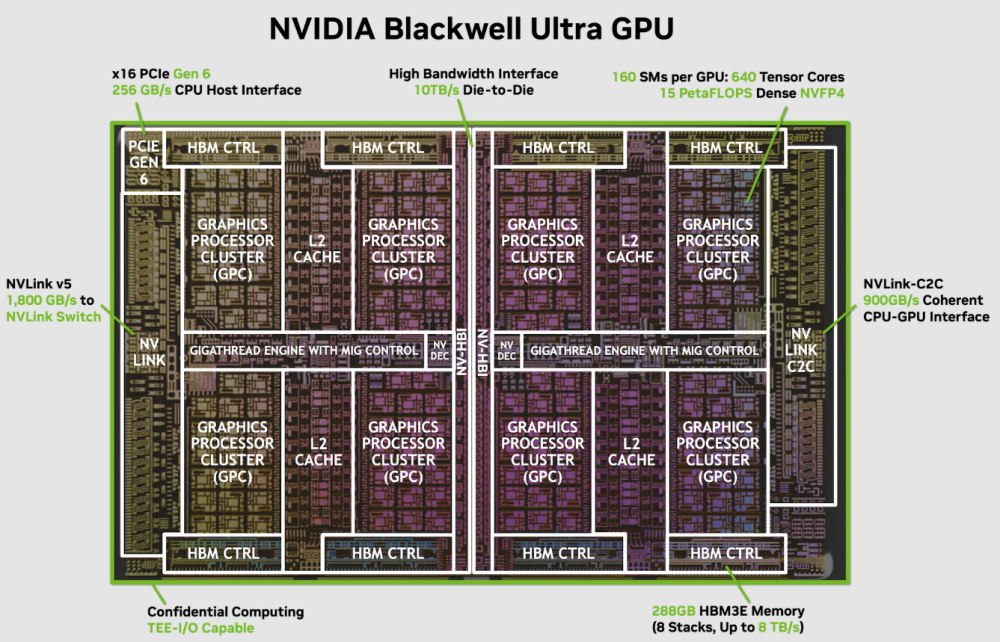
Architettura di riferimento e design dual-reticle
Blackwell Ultra è realizzata avvalendosi del processo TSMC 4NP, incorporando due reticoli (die) connessi tramite l’innovativa NVIDIA High-Bandwidth Interface (NV-HBI) che offre un collegamento die-to-die a 10 TB/s di banda.
La tecnologia in questione permette di mantenere un dominio di calcolo unificato, programmabile con il tradizionale modello CUDA, assicurando compatibilità e scalabilità per gli sviluppatori.
L’intera GPU integra 160 Streaming Multiprocessor (SM) suddivisi in 8 Graphics Processing Cluster (GPC), per un totale di 20.480 CUDA core e 640 tensor core di quinta generazione.
Il design a doppio die consente un uso massimizzato del silicio, con una densità di transistor 2,6 volte superiore rispetto alla precedente generazione Hopper, mantenendo un bilanciamento ottimale tra prestazioni e consumi energetici.
NVFP4: nuovo formato di precisione low-bit per l’AI di prossima generazione
Uno degli elementi distintivi di Blackwell Ultra è l’introduzione del nuovo formato di precisione NVFP4 a 4 bit, sviluppato per fornire calcoli efficienti e accurati a bassa precisione, ottimizzando il rapporto tra velocità e accuratezza negli algoritmi AI.
La struttura con cui NVFP4 è progettato consente una compressione della memoria fino a 3,5 volte inferiore rispetto al formato FP16 e fino a 8 volte rispetto a FP8, mantenendo un errore di quantizzazione vicino all’1%.
Grazie a questa innovazione, Blackwell Ultra raggiunge fino a 15 petaFLOP di prestazioni in calcoli NVFP4 densi, migliorando notevolmente il throughput computazionale e l’efficienza energetica per i modelli Transformer di grandi dimensioni, largamente utilizzati in ambito NLP (Natural Language Processing) e AI multimodale.
Memoria avanzata: HBM3e ad alta capacità
Blackwell Ultra monta una quantità record di memoria HBM3e, con 8 stack che portano la capacità a 288 GB e una banda di 8 TB/s, rispettivamente 3,6 e 2,4 volte superiori rispetto a H100.
Questa capacità è determinante per ospitare modelli AI “trillion-parameter” senza necessità di memory swapping esterno, e per gestire contesti di input notevolmente estesi in tempo reale.
Il controller di memoria si compone di un controller 16 × 512-bit, offrendo un bus totale di 8.192 bit, con piena coerenza di accesso alla cache L2 condivisa tra i due die. Scelte tecniche che si traducono in una latenza inferiore e una maggiore efficienza nel caricamento dei dati.
Innovazioni lato I/O: PCIe 6.0 e NVLink 5 per la massima velocità
Blackwell Ultra introduce il supporto PCI Express 6.0 x16, raddoppiando il throughput del predecessore a 256 GB/s totali tra GPU e CPU. L’incremento si traduce in una comunicazione dati migliorata per carichi di lavoro AI-driven, riducendo i colli di bottiglia nella gestione dei dati tra host e acceleratori.
Inoltre, il sistema GPU-to-GPU comunica tramite la tecnologia NVLink 5, offrendo fino a 1,8 TB/s di banda bidirezionale tramite 18 link a 100 GB/s ciascuno; supporta inoltre NVLink-C2C per la coerenza di memoria e la comunicazione diretta con CPU NVIDIA Grace, essenziale in sistemi data center ad alte prestazioni.
Conclusioni
NVIDIA Blackwell Ultra si presenta come una pietra miliare per il calcolo AI e l’accelerazione HPC di nuova generazione, definendo nuovi standard in termini di potenza, efficienza e scalabilità.
L’adozione di un design dual-reticle con 208 miliardi di transistor e un collegamento chip-to-chip da 10 TB/s consente di unire due die in un’unica GPU programmabile e altamente efficiente, capace di affrontare con successo le sfide computazionali del training e dell’inferenza negli AI factory di scala industriale.
Questa nuova GPU rappresenta dunque non solo un progresso tecnologico di rilievo, ma una piattaforma progettata per sostenere e guidare la prossima generazione di innovazioni nell’intelligenza artificiale e nelle scienze computazionali avanzate.
/https://www.ilsoftware.it/app/uploads/2024/07/grok.jpg "Causa contro Grok per generazione di immagini con abusi sessuali su minori")
/https://www.ilsoftware.it/app/uploads/2024/05/plugin-openvino-intelligenza-artificiale-generativa-GIMP.jpg "Manus lancia My Computer, l'agente AI che lavora sui file locali")
/https://www.ilsoftware.it/app/uploads/2026/03/quale-modello-AI-eseguire-in-locale-hardware.jpg "CanIRun.ai: scopri subito quali modelli AI girano davvero sul tuo PC")
/https://www.ilsoftware.it/app/uploads/2024/03/matx-hardware-modelli-intelligenza-artificiale.jpg "Stop al generatore di video AI di Hollywood a causa del copyright")