/https://www.ilsoftware.it/app/uploads/2023/05/img_25995.jpg "Nasce l'intelligenza artificiale multimodale e olistica: cos'è e come funziona Meta ImageBind")
Quando un’azienda come Meta rilascia un modello generativo come prodotto open source c’è sempre da drizzare le antenne. Si pensi a quanto avvenuto con il rilascio del modello LLaMa e del successivo Alpaca.
La soluzione che viene presentata questa volta si chiama ImageBind e si presenta come uno strumento che guarda all’intelligenza artificiale olistica. L’AI olistica descrive un approccio che cerca di sviluppare sistemi basati sull’intelligenza artificiale che integrano una varietà di tecniche di apprendimento automatico, modelli e algoritmi in modo da poter disporre di un sistema in grado di affrontare problemi complessi in modo più completo e flessibile, integrando diversi aspetti dell’intelligenza artificiale, come il riconoscimento del linguaggio naturale, la visione artificiale, l’elaborazione del suono e il “ragionamento” basato sulla conoscenza.
Invece di sviluppare un sistema AI che si concentra solo su un aspetto specifico del problema, come la classificazione delle immagini o la generazione di testi, l’AI olistica guarda a un sistema capace di apprendere e adattarsi continuamente in base ai dati disponibili.
Quando gli esseri umani assorbono informazioni dal mondo, usiamo innatamente più sensi: Meta offre le chiavi per avvicinare le macchine alle nostre capacità partendo da quella che consente l’apprendimento simultaneo, olistico e diretto da molte e diverse forme di informazioni, senza la necessità di una supervisione esplicita.
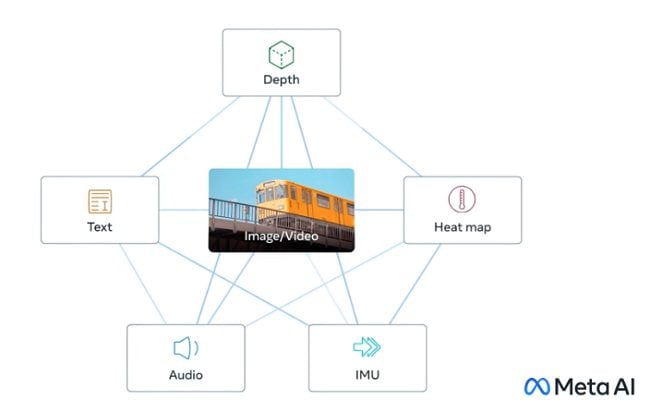
ImageBind fa proprio questo interconnettendo reciprocamente più flussi di dati, inclusi testo, audio, dati visivi, dati di temperatura e calcoli di movimento/posizione: sono complessivamente 6 le modalità al momento conosciute al modello di casa Meta.
“ImageBind può superare i precedenti modelli specialistici addestrati individualmente per una particolare modalità e, cosa più importante, aiuta a far progredire l’intelligenza artificiale consentendo alle macchine di analizzare meglio molte diverse forme di informazioni insieme“, si legge nella nota di presentazione diramata dall’azienda di Mark Zuckerberg.
Modello multimodale, ImageBind integra modelli di visione artificiale come DINOv2, un nuovo metodo che non richiede la messa a punto di modelli di visione artificiale ad alte prestazioni e Segment Anything (SAM), un modello di segmentazione universale in grado di segmentare qualsiasi oggetto in qualsiasi immagine, in base a qualsiasi richiesta dell’utente. ImageBind fa propri questi strumenti e cerca di apprendere dalle varie modalità in contemporanea migliorando via via le sue abilità.
Il concetto centrale è il collegamento di più tipi di dati in un unico indice multidimensionale (o embedding space, per usare il linguaggio di Meta): può sembrare un’idea un po’ astratta, ma è lo stesso concetto alla base del recente successo dell’IA generativa.
Generatori di immagini come DALL-E, Stable Diffusion e Midjourney si basano tutti su sistemi che collegano testo e immagini durante la fase di addestramento: cercano schemi nei dati visivi collegando tali informazioni alle descrizioni delle immagini. È “il sale” che permette poi di produrre immagini nuove che descrivono quanto richiesto dall’utente con il suo prompt. Lo stesso vale per molti strumenti di intelligenza artificiale che generano video o audio in ugual modo.
ImageBind è di fatto il primo modello conosciuto a combinare 6 tipi di dati in un unico embedding space. Un futuristico dispositivo per la realtà virtuale potrebbe così generare non soltanto contenuti audiovisivi ma anche l’ambiente e gestire il movimento del soggetto su una sorta di palcoscenico fisico. In questo modo si può chiedere di simulare l’esperienza di un viaggio per mare: il visore non solo collocherebbe l’utente su una nave con il rumore delle onde in sottofondo, ma potrebbero divenire riproducibili anche il dondolio del ponte sotto i piedi e la fresca brezza dell’aria dell’oceano. Stupefacente e agghiacciante allo stesso tempo. Ma tant’è. D’altra parte gli ingegneri di Meta anticipano che in futuro si potranno legare a ImageBind anche informazioni provenienti da altri sensori, ad esempio meccanismi per rilevare il tocco, il parlato, l’olfatto e addirittura per rispondere a segnali fMRI cerebrali.
I segnali fMRI cerebrali sono rappresentativi dei cambiamenti nel flusso sanguigno cerebrale e sono rilevabili in seguito all’attivazione di specifiche aree del cervello. Questi segnali possono essere utilizzati per identificare le regioni cerebrali coinvolte in determinate funzioni cognitive, come l’elaborazione del linguaggio, l’attenzione, la memoria e le emozioni.
/https://www.ilsoftware.it/app/uploads/2026/06/metodo-query-http.jpg "HTTP cambia dopo oltre 30 anni: arriva QUERY, il nuovo metodo che affianca GET e POST")
/https://www.ilsoftware.it/app/uploads/2026/06/amazon-echo-show-5-monitoraggio-rete-dashboard.jpg "Credevano fosse da buttare: oggi questo Echo Show monitora un'intera rete")
/https://www.ilsoftware.it/app/uploads/2026/06/emulatore-windows-microsoft.jpg "Quando il compilatore generò 65.000 istruzioni inutili e Microsoft intervenne sull'emulatore")
/https://www.ilsoftware.it/app/uploads/2026/06/html-first-raddoppio-utenti-sito-web.jpg "Un sito HTML-first ha raddoppiato gli utenti in una notte: ecco come")