/https://www.ilsoftware.it/app/uploads/2025/09/Qwen3-Omni-AI.jpg "Qwen3-Omni: l’AI che guarda, ascolta e risponde in tempo reale!")
Immagina un assistente virtuale in grado di capire contemporaneamente quello che dici, ciò che mostri in un’immagine e il contenuto di un video, rispondendo immediatamente in maniera naturale, come se parlassi con una persona reale. Questo è Qwen3-Omni, il nuovo modello di intelligenza artificiale generativa rilasciato il 22 settembre 2025 da Alibaba DAMO Academy, il centro di ricerca avanzata del gruppo Alibaba. Con Qwen3-Omni, la comprensione e la generazione di contenuti multimediali diventano più rapide e precise che mai.
Qwen3-Omni nasce dall’esigenza di strumenti AI capaci di elaborare dati complessi e multimodali. È progettato per applicazioni come assistenti virtuali avanzati, analisi multimediale automatica e supporto ad aziende e ricercatori nella gestione di contenuti testuali, audio, immagini e video in maniera integrata e in tempo reale.
Funzionalità principali di Qwen3-Omni
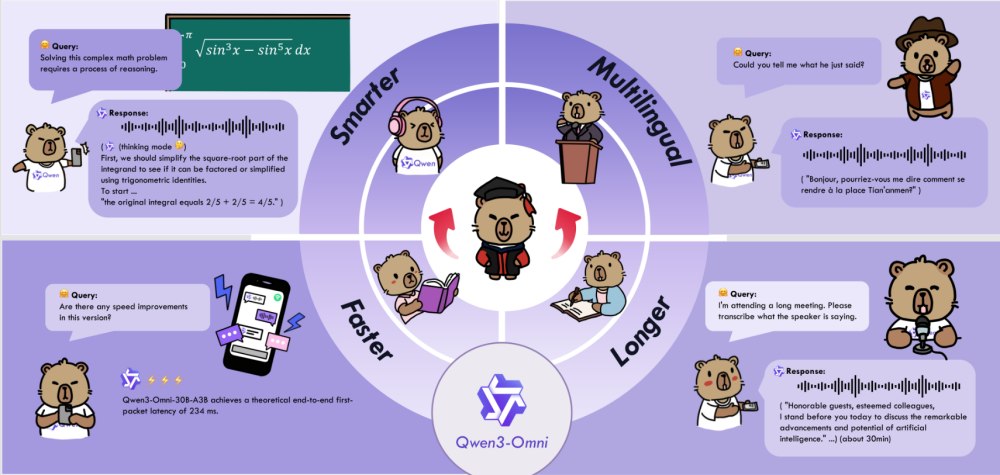
Il modello AI Qwen3-Omni integra diverse tecnologie all’avanguardia. La sua architettura MoE Thinker–Talker con pretraining AuT (Audio-Text pretraining: combina dati audio e testuali fin dalle prime fasi dell’addestramento) consente di elaborare informazioni complesse in tempo reale, minimizzando la latenza. Il modello supporta 119 lingue testuali e 19 lingue di input vocale, con output audio in 10 lingue. È in grado di generare risposte testuali e vocali con naturalezza, mantenendo performance di alto livello su benchmark audio, video e testuali.
Il modello Qwen3-Omni-30B-A3B-Captioner, open source, fornisce descrizioni audio dettagliate e a basso tasso di errore, colmando un vuoto importante tra i progetti a sorgente aperto.
Campi applicativi
Qwen3-Omni trova applicazione in contesti estremamente vari. Può trascrivere audio, tradurre tra lingue diverse, analizzare musica, rumori ambientali o effetti sonori.
Per quanto riguarda la visione, il modello è capace di riconoscere testi complessi, rilevare oggetti, rispondere a domande su immagini e video e risolvere problemi matematici presenti nelle immagini.
L’integrazione audio-video permette di comprendere scene complesse, interagire in modo conversazionale e generare didascalie sincronizzate. Grazie alla capacità di elaborare input multimodali, può anche agire come un vero agente digitale, eseguendo comandi tramite audio o video.
Come installare e utilizzare Qwen3-Omni
Per iniziare rapidamente, è possibile installare il modello tramite Hugging Face Transformers. Dopo aver installato le librerie necessarie, il modello e il processore possono essere caricati con poche righe di codice Python.
L’utente può quindi preparare input di tipo testo, audio, immagini e video e ottenere output sia testuali che vocali. Per chi necessita di inferenze veloci o elaborazioni batch di molti di dati importanti, il motore vLLM consente di utilizzare più GPU contemporaneamente, ottimizzando la velocità e la gestione della memoria. Chi preferisce un setup già pronto può utilizzare il container Docker fornito da Alibaba, che include tutte le librerie necessarie e supporta l’accesso GPU, permettendo di avviare rapidamente demo e test locali.
Preparazione dell’ambiente
Per prima cosa, è bene assicurarsi di avere installato Python 3.8 o superiore e di usare una GPU compatibile con CUDA. È quindi possibile lavorare direttamente sul sistema in uso o usare Docker per un ambiente preconfigurato.
Il comando seguente (modificare opportunamente almeno il valore della variabile LOCAL_WORKDIR) permette di impostare un container Docker contenente il modello:
LOCAL_WORKDIR=/path/to/your/workspace
HOST_PORT=8901
CONTAINER_PORT=80
docker run --gpus all --name qwen3-omni \
-v $LOCAL_WORKDIR:/data/shared/Qwen3-Omni \
-p $HOST_PORT:$CONTAINER_PORT \
--shm-size=4gb \
-it qwenllm/qwen3-omni:3-cu124
In questo modo si ha subito a disposizione un container Docker già pronto con GPU accessibile e tutte le librerie installate.
Se invece si preferisse lavorare senza Docker, è necessario installare i pacchetti necessari con Python pip.
Caricare il modello Qwen3-Omni
A seconda delle esigenze, è possibile optare tra diverse versioni del modello:
- Instruct: per input multimodali con output testo e audio.
- Thinking: per ragionamento profondo e output testuale.
- Captioner: per generare didascalie dettagliate da audio.
Di seguito un estratto di codice per caricare il modello Instruct con Python:
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(MODEL_PATH, dtype="auto", device_map="auto")
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
Preparare input audio o video ed elaborare input multimodali
Con Qwen3-Omni si possono utilizzare file locali o link diretti a contenuti video/audio. Il modello supporta video con audio integrato, audio puro e immagini: un esempio concreto.
Per trasformare video e audio in input interpretabili dal modello, è quindi sufficiente usare questa sintassi.
Come accennato in precedenza, è possibile ottenere sia testo che audio sintetizzato in risposta all’input multimodale. Esempio:
import soundfile as sf
text_ids, audio = model.generate(**inputs, speaker="Ethan", thinker_return_dict_in_generate=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
# Decodifica testo
text = processor.batch_decode(text_ids.sequences[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print("Risposta testuale:", text[0])
# Salva output audio
if audio is not None:
sf.write("output.wav", audio.reshape(-1).detach().cpu().numpy(), samplerate=24000)
print("Audio generato salvato in output.wav")
Note finali
Abbiamo cercato di semplificare al massimo i dettagli tecnici sul funzionamento del modello Qwen3-Omni. Suggeriamo di fare riferimento al repository GitHub ufficiale per accedere alla guida all’uso completa.
In generale, è bene mantenere l’elaborazione dell’audio dei video abilitata (use_audio_in_video=True) per risposte più complete. Inoltre, è importante inserire sempre una richiesta testuale chiara insieme al video o all’audio: il modello comprenderà meglio il compito da svolgere. Per inferenze veloci o procedure batch su grandi volumi di dati, è opportuno usare vLLM o Docker con GPU.
/https://www.ilsoftware.it/app/uploads/2023/12/notebookLM-google-funzionamento.jpg "Google introduce banner personalizzabili per NotebookLM")
/https://www.ilsoftware.it/app/uploads/2024/01/intelligenza-artificiale-applicazioni-ollama-librerie.jpg "Agenti AI sempre più potenti ma non aumenta la trasparenza")
/https://www.ilsoftware.it/app/uploads/2026/02/wp_drafter_496540.jpg "Anthropic porta Claude in PowerPoint con il piano Pro: cosa cambia?")
/https://www.ilsoftware.it/app/uploads/2025/06/gemini-azioni-programmate.jpg "Google lancia Gemini 3.1 Pro: i primi test impressionano gli esperti")