/https://www.ilsoftware.it/app/uploads/2025/08/eseguire-modelli-gpt-oss-openai-su-chip-amd.jpg "Addio cloud: grazie ad AMD, i modelli OpenAI GPT-OSS 20B e 120B funzionano sul tuo PC")
Nei giorni scorsi OpenAI ha annunciato la disponibilità dei suoi primi modelli linguistici open-weight di nuova generazione, GPT-OSS 20B e GPT-OSS 120B, pensati per portare capacità di reasoning avanzato anche in locale, senza demandare le elaborazioni ad infrastrutture cloud. Si tratta di un passo importante in ambito AI, non solo per le prestazioni dei modelli, ma soprattutto per la possibilità di eseguirli su hardware consumer di fascia alta, grazie al supporto nativo dei processori AMD Ryzen AI e delle GPU Radeon.
Architettura e specifiche tecniche dei modelli OpenAI GPT-OSS
Abbiamo già descritto nel dettaglio le caratteristiche di entrambi i nuovi modelli OpenAI. Ricordiamo tuttavia che GPT-OSS 120B, da 116,8 miliardi di parametri totali (5,1 miliardi attivi grazie a un’architettura Mixture of Experts), richiede circa 61 GB di VRAM nella versione GGML/MXFP4.
GPT-OSS 20B è invece formato da 20,9 miliardi di parametri totali (3,6 miliardi attivi) ed è progettato per garantire bassa latenza e prestazioni elevate anche su sistemi desktop con GPU dedicate di fascia enthusiast.
Entrambi i modelli sono ottimizzati per l’esecuzione su chip Ryzen AI e GPU Radeon GPUs tramite llama.cpp (programma leggero che permette di eseguire modelli di linguaggio come LLaMA o derivati direttamente su CPU o GPU locali, senza bisogno di server cloud o framework pesanti come PyTorch), con possibilità di sfruttare l’accelerazione hardware AMD e la gestione avanzata della memoria (Variable Graphics Memory).
Ryzen AI Max+ 395: il primo processore consumer in grado di eseguire GPT-OSS 120B
AMD segna un punto storico nel settore AI con il suo Ryzen AI Max+ 395, in grado di supportare fino a 128 GB di memoria unificata ad altissima velocità (8000 MT/s). È il primo processore per PC consumer capace di eseguire localmente un modello da 120 miliardi di parametri, abilità finora osservabili solo all’interno dei data center.
L’ampia banda passante della memoria permette di sostenere fino a 30 token/sec nel modello 120B mentre l’architettura Mixture-of-Experts riduce il numero di parametri attivi e ottimizza il calcolo. Il supporto per MCP (Model Context Protocol) è utile in scenari come analisi di documenti complessi, simulazioni e applicazioni industriali AI-driven.
Prestazioni e configurazioni consigliate
Per GPT-OSS 120B, AMD consiglia appunto Ryzen AI Max+ 395 (128GB), driver Adrenalin Edition 25.8.1 WHQL o successivi, VGM impostato secondo le specifiche indicate per garantire la piena allocazione della memoria. Il pacchetto GGML MXFP4 di GPT-OSS 120B richiede circa 61 GB di VRAM effettiva.
Per GPT-OSS 20B, si può usare una GPU Radeon RX 9070 XT 16GB abbinata a CPU ad alte prestazioni (i.e. Intel Core i9-13900K). Il modello, eseguito su RX 9070 XT, offre un valore in termini di tokens/s molto elevato e TTFT (time-to-first-token) eccellente.
Guida rapida per provare GPT-OSS 20B/120B in locale su AMD Ryzen AI e Radeon
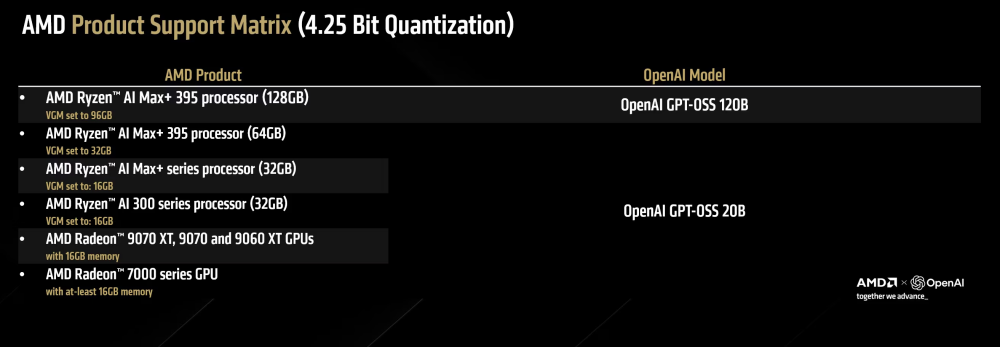
Per iniziare, è necessario installare il software AMD Adrenalin Edition 25.8.1 WHQL o superiore, riavviare il sistema quindi verificare la versione in Adrenalin, Impostazioni, Sistema.
Soltanto sui notebook Ryzen AI, è necessario impostare la Variable Graphics Memory (VGM). Per procedere, si deve fare clic con il tasto destro sul desktop, scegliere la voce AMD Software: Adrenalin Edition, selezionare Prestazioni (Performance), Tuning quindi impostare VGM secondo quanto riportato in tabella.
Installazione di LM Studio e download del modello OpenAI
LM Studio è un’applicazione che permette di eseguire modelli di linguaggio AI localmente sul tuo PC, sfruttando CPU e GPU compatibili. Serve a caricare e usare modelli AI (come OpenAI GPT-OSS 20B o 120B) senza passare dal cloud, gestire le impostazioni di memoria e GPU per ottimizzare prestazioni, interagire con il modello generativo tramite interfaccia grafica (chat, prompt, test di modelli).
Dopo aver scaricato e installato LM Studio, bisogna portarsi nella scheda Discover, cercare gpt-oss e, nell’elenco, individuare l’opzione con prefisso lm studio community. È quindi possibile scegliere GPT-OSS 20B (desktop RX 9070 XT / Ryzen AI 300) oppure GPT-OSS 120B (Ryzen AI Max+ 395 128 GB). Cliccando su Download si attiva lo scaricamento del modello.
È importante che la cartella models si trovi su una veloce unità SSD NVMe con abbondante spazio libero.
Configurare la sessione di chat
A download completato, si può aprire la scheda Chat quindi selezionare il modello OpenAI GPT-OSS dal menu a tendina.
È necessario spuntare Manually load parameters (caricamento manuale dei parametri) per poi portare lo slider GPU Offload tutto a destra (MAX). Infine, si deve attivare Remember settings per salvare la configurazione.
Caricare il modello in memoria
Il pulsante Load permette di avviare il caricamento del modello OpenAI in memoria.
Per la versione 120B il caricamento può sembrare “fermarsi” per qualche minuto. Si tratta di un comportamento normale, perché il trasferimento di decine di GB verso la memoria/VRAM può saturare la banda e gli SSD riducono la velocità dopo il burst iniziale.
È quindi necessario aspettare fintanto che lo stato non diventa Ready.
Eseguire il primo prompt
Nella casella di testo, si può adesso finalmente digitare un prompt di test (ad esempio, “In quanto tempo cade una sfera da un’altezza di 10 metri?”).
Dopo l’invio, è opportuno osservare e annotare due valori: tokens/s (velocità sostenuta) e TTFT ovvero il tempo che passa prima dell’effettiva ricezione del primo token da parte del modello sottostante.
Ulteriori informazioni sono disponibili nel documento pubblicato da AMD.
/https://www.ilsoftware.it/app/uploads/2026/03/shazam-chatgpt-riconoscimento-brani-musicali.jpg "ChatGPT ora riconosce le canzoni: Shazam arriva nella chat AI")
/https://www.ilsoftware.it/app/uploads/2026/03/scuola-AI-riconoscimento-testi.jpg "Scuola e AI, il paradosso che spinge gli studenti a scrivere peggio")
/https://www.ilsoftware.it/app/uploads/2024/07/1-34.jpg "Google Foto introduce toggle per scelta rapida tra ricerca classica o con AI")
/https://www.ilsoftware.it/app/uploads/2025/08/notebooklm-audio-video-overview-italiano.jpg "Google potenzia NotebookLM con supporto EPUB per riassunti multimediali")