/https://www.ilsoftware.it/app/uploads/2024/02/analisi-dati-apache-superset-SQL.jpg "Apache Superset: analisi dati diventa semplice grazie all'open source")
L’analisi dati è fondamentale per qualunque tipo di attività lavorativa. È il sale della cosiddetta business intelligence, espressione con cui ci riferiamo all’insieme dei processi aziendali che aiutano a raccogliere dati rilevanti e ad analizzare informazioni strategiche. Estrarre informazioni dai dati, infatti, è essenziale per qualunque realtà d’impresa e la presentazione in forma strutturata, magari attraverso grafici e rappresentazioni efficaci, risulta essenziale per prendere decisioni.
Cos’è Apache Superset e a cosa serve
Per tutti coloro che hanno la necessità di collegarsi con i database più disparati ed estrarre informazioni da proporre poi in forma grafica, un progetto open source come Apache Superset assume un’importanza a dir poco essenziale.
Apache Superset è una piattaforma di esplorazione e visualizzazione dati open source, progettata per adattarsi alle esigenze più evolute di analisi dati. Con la sua leggerezza, potenza e intuitività, Superset offre un’ampia gamma di opzioni, rendendo semplice per gli utenti – indipendentemente dal loro livello di esperienza – configurare visualizzazioni dei dati personalizzate. Da semplici grafici a linee fino all’utilizzo di mappe geospaziali altamente dettagliate.
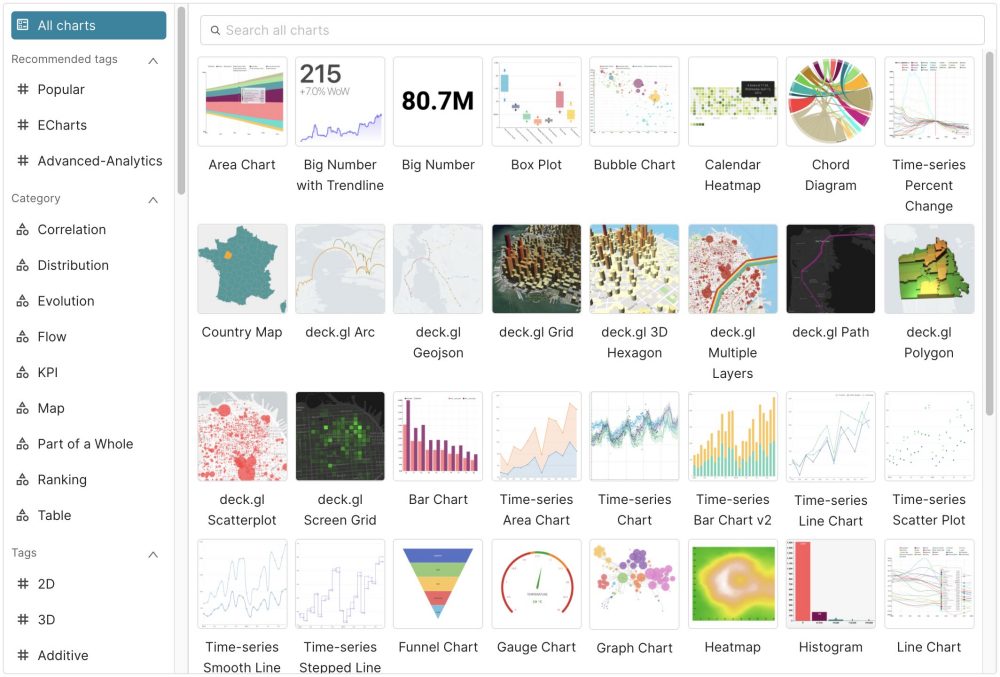
La struttura di Apache Superset
Superset mette a disposizione strumenti evoluti per creare facilmente dashboard interattive, utili per per esplorare i dati e individuare insight. Il Chart Builder è un costruttore di grafici e tabelle mentre SQL Lab permette di scrivere query SQL personalizzate, esplorare metadati del database e utilizzare templating Jinja. Quest’ultima caratteristica si riferisce alla possibilità di incorporare espressioni e variabili dinamiche all’interno dei componenti della piattaforma. Jinja è un motore di templating per il linguaggio di programmazione Python che consente di inserire dinamicamente valori o logica all’interno di stringhe e modelli.
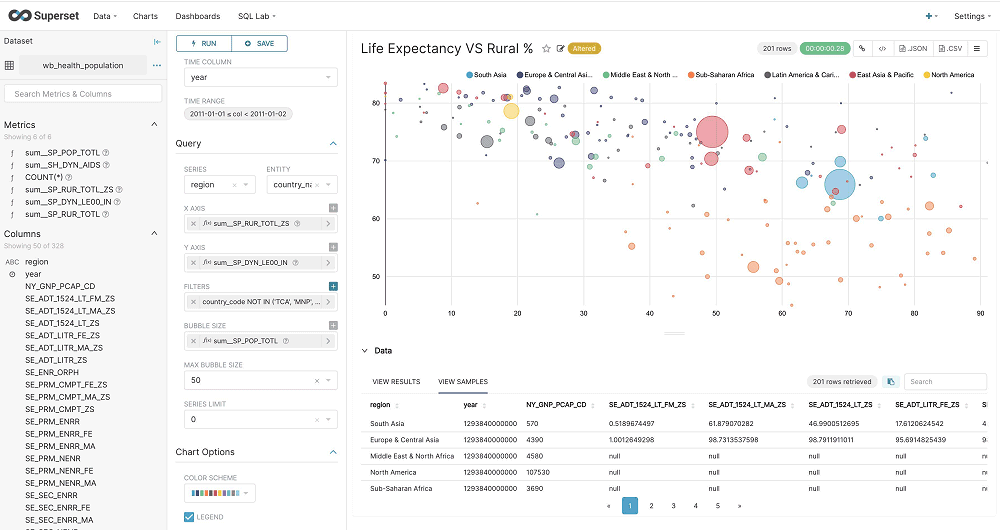
Nell’immagine, il Chart Builder di Apache Superset permette di creare grafici senza usare codice di programmazione.
La piattaforma Superset consente infine di creare dataset fisici e virtuali: i primi si riferiscono a un insieme di dati effettivamente memorizzato in un database o in una sorgente dati. Un dataset virtuale è invece un’astrazione o una definizione logica di dati che potrebbe non essere effettivamente memorizzata, ma creata in modo dinamico (ad esempio derivata da diverse fonti di dati).
Gli utenti di Superset possono quindi esplorare e visualizzare dati da diverse fonti senza dover creare manualmente un nuovo dataset per ciascuna sorgente. Si tratta di un aspetto particolarmente utile quando si lavora con grandi volumi di dati provenienti da fonti eterogenee.
IDE SQL per l’analisi dati
Veloce, leggero e ricco di opzioni che lo rendono adatto a un’ampia varietà di possibili campi applicativi, Superset punta al raggiungimento dei traguardi prefissi da ciascun utente senza scrivere codice. Integra comunque un moderno ambiente IDE SQL per esplorare i dati: Superset è capace di collegarsi a qualunque database basato sul linguaggio SQL, compresi quelli moderni su “scala Petabyte”.

In figura, il potente editor SQL di Apache Superset.
Grazie all’approccio leggero e scalabile, Superset sfrutta l’infrastruttura dati esistente senza richiedere un ulteriore livello di ingestion. Con il termine ingestion, ci si riferisce al processo di acquisizione, trasformazione e caricamento dei dati da una fonte all’altra.
In molte soluzioni di analisi dati, potrebbe essere necessario implementare un livello aggiuntivo per preparare i dati. Superset, di contro, spazza via questo requisito, consentendo agli utenti di esplorare e visualizzare i dati direttamente dalla fonte senza richiedere complessi processi aggiuntivi.
Tra i database supportati (o comunque “fonti di dati”) ci sono, ad esempio, PostgreSQL, MySQL, BigQuery, Snowflake, Amazon Redshift, Amazon Athena, Apache Druid, Databricks, Google Fogli, CSV, ClickHouse, Rockset, Dremio, Trino, Oracle, Apache Pinot, Presto, IBM Db2, SAP Hana, Microsoft SQL Server e Apache Doris.
Superset include oltre 40 tipi di visualizzazioni pre-installate, con un’architettura a plug-in che semplifica la creazione di “ricette” personalizzate.
Per maggiori informazioni, è possibile fare riferimento anche al repository GitHub del progetto Apache Superset.
Credit immagine in apertura: iStock.com – champpixs
/https://www.ilsoftware.it/app/uploads/2024/11/boot-windows-98.png "98.css riporta il look di Windows 98 nei siti web moderni")
/https://www.ilsoftware.it/app/uploads/2026/07/SIMD-CPU.jpg "SIMD spiegato bene: perché può accelerare davvero il software")
/https://www.ilsoftware.it/app/uploads/2026/07/accordo-mistral-microsoft-AI-europea.jpg "Microsoft e Mistral rafforzano l'AI europea: modelli e GPU dal cloud agli ambienti disconnessi")
/https://www.ilsoftware.it/app/uploads/2026/07/vulnhunter-ricerca-vulnerabilita-software-ai.jpg "VulnHunter: l'AI che trova, corregge e verifica le vulnerabilità nel codice")