/https://www.ilsoftware.it/app/uploads/2023/05/img_18419.jpg "AlphaZero, l'intelligenza artificiale di Google DeepMind che impara da sola")
A distanza di poco più di un anno dall’annuncio degli enormi progressi compiuti dall’intelligenza artificiale AlphaGo di DeepMind, società controllata da Google/Alphabet (vedere AlphaGo Zero: l’intelligenza artificiale di Google DeepMind impara da sola), in un articolo apparso quest’oggi sulla rivista Science lo stesso team presenta AlphaZero.
AlphaZero è un’intelligenza artificiale che riesce a vincere senza problemi, confrontandosi con i campioni di caratura mondiale, a giochi come scacchi, Go e Shogi.
La sua principale peculiarità è che, diversamente rispetto alle versioni precedenti, è in grado di autoapprendere un nuovo gioco stilando le migliori tattiche per vincere in appena tre giorni.
Il lavoro pubblicato su Science è arricchito con un commento di Murray Campbell, ricercatore presso il centro IBM Thomas J. Watson Research Center ed esperto di intelligenze artificiali. Secondo Campbell, che nel 1997 era membro del team di esperti IBM che mise a punto e “addestrò” Deep Blue (computer che riuscì a battere a scacchi il campione Garry Kasparov), AlphaZero “ha sapientemente chiuso un capitolo in materia di ricerca sull’intelligenza artificiale durato decenni”
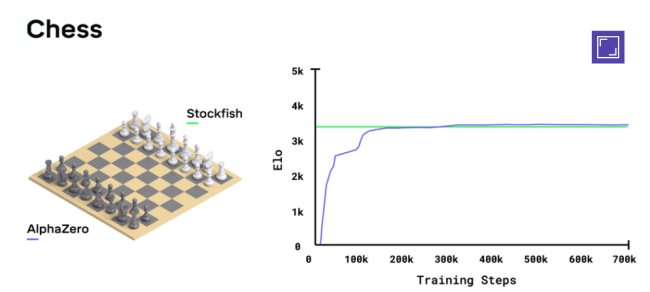
AlphaZero riesce a risultare vittorioso in qualunque gioco che di per sé fornisca le informazioni utili per simulare artificialmente un processo decisionale vincente.
Se Deep Blue era un sistema di dimensioni mastodontiche oggi addirittura un’app può battere l’attuale campione di scacchi Magnus Carlsen.
Niente a che vedere, però, con AlphaZero che è riuscito a sconfiggere l’apprezzatissimo motore di scacchi Stockfish dopo appena 24 ore di autoapprendimento.
L’annuncio di oggi è importante perché pone una vera e propria pietra miliare: un sistema come AlphaZero riesce ad adattarsi a molteplici giochi e a individuarne “i segreti” per giungere il più rapidamente possibile alla vittoria.
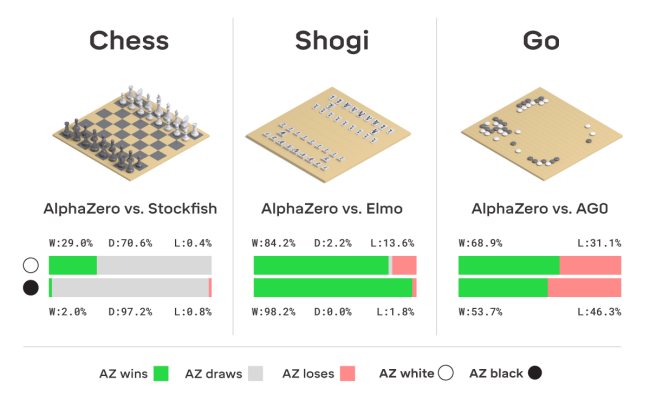
Le problematiche della vita reale difficilmente sono analizzabili utilizzando un insieme di informazioni predefinito: come spiega Campbell la sfida è a questo punto quella di ampliare ulteriormente il raggio d’azione di AlphaZero così che l’intelligenza artificiale possa prendere decisioni (si pensi ai multiplayer o allo stesso gioco del poker) in cui non ci sono solo schemi noti da seguire e da recuperare al bisogno.
Vincere quest’ulteriore sfida – che solo all’apparenza è “ludica” – significherebbe scoprire di fatto il Santo Graal delle intelligenze artificiali.
Siamo certi che Waymo, impresa di Google/Alphabet impegnata nel mercato delle vetture a guida autonoma, stia già beneficiando dei passi in avanti compiuti dalla “sorella” londinese DeepMind.
Maggiori informazioni sul lavoro svolto dai tecnici di DeepMind sono disponibili a questo indirizzo.
/https://www.ilsoftware.it/app/uploads/2025/07/estensione-copilot-chat-visual-studio-code-open-source.jpg "Copilot Chat per Visual Studio Code diventa open source")
/https://www.ilsoftware.it/app/uploads/2025/07/debug-chip-snapdragon-porta-usb-nascosta.jpg "Gli Snapdragon hanno una porta USB nascosta: di cosa si tratta")
/https://www.ilsoftware.it/app/uploads/2025/06/gemini-cli-cose-funzionamento.jpg "Gemini CLI: agente AI open source (gratuito) di Google arriva nel terminale")
/https://www.ilsoftware.it/app/uploads/2025/06/programmazione-software-manuale-AI.jpg "Intelligenza artificiale e sviluppo software: perché la programmazione manuale resta fondamentale")