/https://www.ilsoftware.it/app/uploads/2023/05/img_12489.jpg "OCR da PDF, come estrarre il testo in poche mosse")
Di strumenti software e metodologie per effettuare il riconoscimento ottico dei caratteri (OCR, optical character recognition) abbiamo spesso parlato nelle pagine de IlSoftware.it.
Per effettuare l’OCR da PDF fino a qualche tempo fa era necessario dotarsi di un apposito programma a pagamento. Può infatti capitare spesso di avere a che fare con documenti PDF contenenti semplicemente delle immagini acquisite da scanner.
Molti utenti, trovandosi dinanzi ad un PDF del genere pensano che si tratti di un documento protetto contro la copia e non si accorgono, invece, che il file è modificabile ma contiene semplicemente immagini tratte da documenti cartacei ed inserite nel PDF senza effettuare l’OCR ossia il riconoscimento ottico dei caratteri.
Per verificare se in un documento PDF fosse stata attivata la protezione anticopia, basta ad esempio aprirlo con Adobe Reader quindi scegliere la voce Proprietà dal menu File.
Se si legge Consenti accanto alle varie voci Copia contenuto e Stampa, significa che il PDF non integra alcun tipo di protezione. Se quindi non si riuscisse a estrarre e copiare il testo dal PDF è altamente probabile che il documento contenga semplici immagini acquisite da scanner.
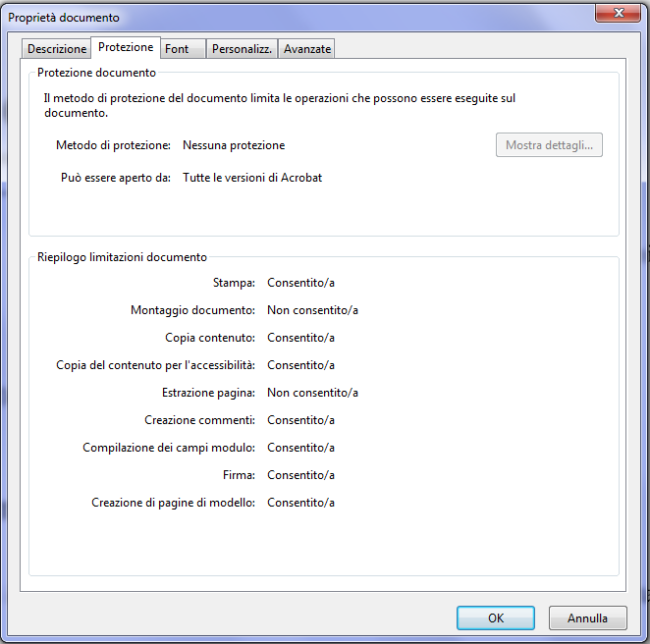
L’unico controllo da effettuare è che nel programma per la visualizzazione e la gestione dei file PDF (ad esempio Acrobat Reader) si sia attivato lo strumento per la selezione del testo (premere il tasto destro del mouse sul documento e scegliere Strumento selezione).

Vediamo di seguito alcune soluzioni, pronte per l’uso, per effettuare l’OCR da PDF:
1) Utilizzare l’applicazione Office Lens
L’applicazione Microsoft Office Lens si rivela particolarmente utile per tutti coloro che hanno spesso a che fare con documenti cartacei e desiderano effettuarne la scansione OCR senza neppure il bisogno di usare lo scanner.
L’app Office Lens si dimostra efficace e davvero versatile: è sufficiente puntare la fotocamera dello smartphone o del tablet verso il documento da acquisire. “I confini” del documento inquadrato con la fotocamera saranno automaticamente riconosciuti da Office Lens.
Dopo l’acquisizione, scegliendo di salvare il documento come PDF su OneDrive – quindi sul servizio cloud di Microsoft – il suo contenuto sarà immediatamente sottoposto a OCR.
Si potrà verificarlo semplicemente aprendo il documento PDF in Office Online previo login su OneDrive con il proprio account Microsoft. Selezionando una porzione di testo ed usando la combinazione di tasti CTRL+C questo potrà essere salvato nell’area degli appunti del sistema operativo.
Premendo CTRL+V in una qualunque applicazione, si potrà incollare il testo proveniente dal file PDF e riconosciuto via OCR.
La procedura da seguire è illustrata nel dettaglio nell’articolo Scansione documenti su Android con Office Lens.
2) Utilizzare l’OCR integrato in Office Online
Se si ha già un documento PDF composto da sole immagini, è possibile caricarlo su OneDrive quindi trasformare il PDF in Word cliccando sul suo nome quindi scegliendo Modifica in Word.
È da rimarcare il fatto che l’OCR da PDF viene anche in questo caso eseguito sui server di Microsoft senza la necessità di installare nulla in locale.
Dopo che si sarà conclusa la conversione del PDF in Word, si potrà aprire il documento risultante in Word Online ed utilizzare di nuovo le combinazioni di tasti CTRL+C e CTRL+V per estrarre e copiare il testo d’interesse.
I passaggi da seguire sono illustrati nel nostro articolo Come convertire PDF in Word.
3) Usare l’OCR di PDF-XChange PDF Viewer
Una soluzione alternativa, validissima, consiste nell’adoperare il programma gratuito PDF-XChange Viewer.
L’applicazione integra un completo modulo OCR che effettua il riconoscimento dei caratteri contenuti in un PDF rendendo quindi “ricercabile” ed estraibile il testo inserito nel documento sotto forma di immagine.
PDF-XChange Viewer permette il download e l’utilizzo del dizionario italiano: il risultato è che i testi contenuti nelle immagini inserite nel file PDF sono automaticamente rilevati in maniera di solito molto efficace.
Diversamente rispetto alle precedenti soluzioni, nel caso di PDF-XChange Viewer il documento PDF da sottoporre ad OCR resta sempre in locale e non viene inviato su alcun servizio cloud.
Nell’articolo Convertire un PDF in un PDF ricercabile con l’OCR abbiamo spiegato come effettuare l’OCR da PDF ricorrendo al comodissimo PDF-XChange Viewer.
4) Estrarre il testo dalle immagini con Google Keep
L’app Keep di Google consente di riconoscere ed estrarre il testo dalle immagini.
La procedura è molto semplice ed è descritta nell’articolo Trascrivere testo da foto con Google Keep su desktop e smartphone.
Diversamente dalle soluzioni descritte in precedenza, Google Keep non agisce sui file PDF ma solo sulle immagini.
Per provare Keep si può sempre estrarre il contenuto del documento PDF come immagine: Convertire PDF in JPG, come trasformare un PDF in immagine.
5) Utilizzare Microsoft OneNote
Tornando in orbita Microsoft, anche OneNote consente di lanciare l’OCR sulle pagine precedentemente sottoposte a scansione.
L’applicazione, utilizzabile anche da smartphone e tablet (servendosi quindi, in questo caso, della fotocamera digitale per l’acquisizione dei documenti cartacei), integra un modulo OCR che – servendosi del comando Copia testo dall’immagine – permetterà di estrarre il testo dalle immagini oggetto di scansione.
La funzionalità OCR di OneNote è descritta nel nostro articolo Cos’è e come usare OneNote per prendere note e appunti.
/https://www.ilsoftware.it/app/uploads/2025/07/7zip-compressione-parallelizzazione-cpu-moderne.jpg "7-Zip 25.00 sblocca oltre 64 thread: compressione parallela ultraveloce")
/https://www.ilsoftware.it/app/uploads/2025/05/microsoft-edit-editor-testo-riga-comando.jpg "Edit: nuovo editor di testo CLI open source integrato in Windows 11 (aggiornato)")
/https://www.ilsoftware.it/app/uploads/2025/05/microsoft-power-toys.jpg "Microsoft PowerToys 0.91: le novità della nuova versione")
/https://www.ilsoftware.it/app/uploads/2025/03/ripristino-windows-11-quick-machine-recovery.jpg "Ripristino remoto Windows 11 al debutto: come funziona")