/https://www.ilsoftware.it/app/uploads/2023/05/img_16471.jpg "Regular expression o espressioni regolari: cosa sono e come utilizzarle")
Quante volte vi è capitato di dover effettuare delle modifiche su un documento, un file di testo o un foglio elettronico non riuscendo a trovare la via migliore per intervenire in blocco su un gran numero di informazioni?
Come fare, per esempio, a eliminare quanto appare su ogni riga dopo un certo carattere oppure a sostituire in blocco diverse varianti di occorrenze nel testo?
Cosa sono le regular expression o espressioni regolari e come si usano
Le regular expression o espressioni regolari in italiano sono stringhe composte anche da sequenze di simboli che permettono di individuare un insieme di stringhe.
La sintassi non è universale: programmi diversi usano approcci sintattici differenti ma l’approccio è comunque sempre lo stesso.
I programmi del pacchetto Office, LibreOffice e gli editor di testo come Notepad++ supportano tutti le regular expression accedendo alle funzioni Trova o Sostituisci.
Un’espressione regolare definisce una funzione che prendendo in ingresso una stringa restituisce in uscita un valore del tipo sì/no a seconda che la stringa segua o meno lo schema o pattern indicato.
Ecco perché le regular expression si utilizzano con i comandi Trova e Sostituisci: se una o più stringhe contenute nel file rispettano lo schema indicato nell’espressione regolare, la sequenza di caratteri viene evidenziata oppure sostituita con quella specificata dall’utente.
I simboli seguenti sono certamente interessanti per iniziare a creare le proprie regular expression:
. = qualunque carattere
\. = carattere “punto”
.? = corrispondenza con qualunque carattere, zero o una volta
.* = corrispondenza con qualunque carattere, zero o più volte
.+ = corrispondenza con qualunque carattere, una o più volte
Cercando, per esempio, R.ssi, l’editor di testo restituirà sia le occorrenze di Rossi che quelle di Russi.
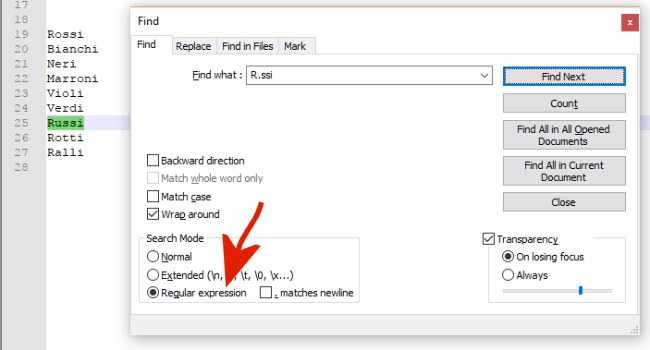
L’importante, quando si effettua una ricerca o una sostituzione con una regular expression, è attivare l’apposita casella che consente di informare il programma che quella richiesta non è una ricerca normale.
Rilevanti anche i seguenti simboli:
^ = Trova il termine cercato solo se appare all’inizio di un paragrafo
^. = Individua il primo carattere di ogni paragrafo o riga
$ = Trova il termine cercato solo se appare alla fine di un paragrafo
^$ = Individua una riga vuota
| = Trova i termini che compaiono sia prima che dopo il simbolo |. Ad esempio, cercando con il criterio questo|quello, vengono individuate nel testo sia le occorrenze di “questo” che di “quello”. Si ottiene di fatto un “OR”.
{2} = Definisce il numero di ripetizioni del carattere che precede la parentesi graffa aperta. Ad esempio, “mol{2}e” trova e seleziona “molle”.
{1,2} = Definisce il numero minimo e massimo di volte di ripetizioni del carattere che precede la parentesi graffa aperta. Ad esempio, “mol{1,2}e” trova e seleziona “mole” e “molle”.
{1,} = Definisce il numero minimo di volte che il carattere che precede la parentesi graffa aperta può ripetersi. Ad esempio, “mol{2}e” trova “molle”, “mollle” e “mollllle”.
Si supponga di voler trasformare il seguente elenco:
Mario Bianchi
Mauro Verdi
Giuseppe Neri
Flavio Marroni
Franco Violi
in questo:
Bianchi, Mario
Verdi, Mauro
Neri, Giuseppe
Marroni, Flavio
Violi, Franco
L’obiettivo è cioè quello di effettuare la trasposizione di nomi e cognomi in un elenco in cui figurino prima i cognomi e poi i nomi, separati da virgole.
La sintassi da usare nel campo per la ricerca è la seguente: ^([a-z]+) ([a-z]+)
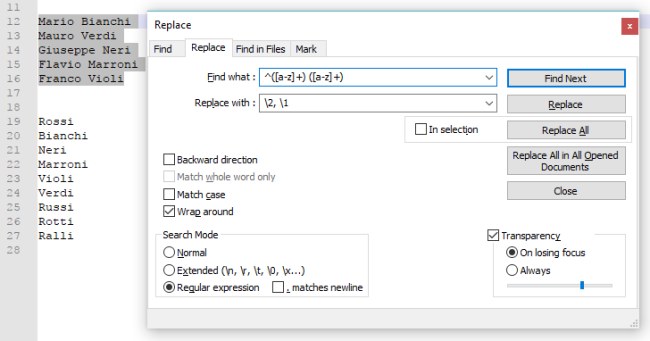
Il primo carattere della regular expression consente, come visto in precedenza, di selezionare i termini che compaiono all’inizio di ciascun paragrafo (riga) mentre quanto tra parentesi tonde indica di selezionare qualunque termine contenente lettere dell’alfabeto.
Al primo termine, in questo caso il nome, sarà assegnato l’identificativo “1” mentre al secondo (seconda parentesi tonda), l’identificativo “2”.
Nel campo Sostituisci con è quindi possibile inserire \2, \1 per avere, in ogni riga, prima il cognome e poi il nome, opportunamente separati da una virgola.
Eliminare tutto quanto compare dopo una certa stringa, su ogni riga
Per rimuovere qualsiasi stringa di caratteri che comparisse dopo un certo carattere o un insieme di essi, è possibile digitare quanto segue nel campo Trova:
Mentre nella casella Sostituisci con si dovrà digitare:
A questo indirizzo si possono trovare diversi esempi di utilizzo delle regular expression nel caso di Office mentre qui una guida per LibreOffice, utilizzabile anche nel caso degli editor di testo migliori come Notepad++.
/https://www.ilsoftware.it/app/uploads/2025/07/estensione-copilot-chat-visual-studio-code-open-source.jpg "Copilot Chat per Visual Studio Code diventa open source")
/https://www.ilsoftware.it/app/uploads/2025/07/debug-chip-snapdragon-porta-usb-nascosta.jpg "Gli Snapdragon hanno una porta USB nascosta: di cosa si tratta")
/https://www.ilsoftware.it/app/uploads/2025/06/gemini-cli-cose-funzionamento.jpg "Gemini CLI: agente AI open source (gratuito) di Google arriva nel terminale")
/https://www.ilsoftware.it/app/uploads/2025/06/programmazione-software-manuale-AI.jpg "Intelligenza artificiale e sviluppo software: perché la programmazione manuale resta fondamentale")