/https://www.ilsoftware.it/app/uploads/2023/05/img_8032.jpg "Riconoscimento ottico dei caratteri con OpenOCR")
I software per il riconoscimento ottico dei caratteri (OCR, optical character recognition) sono programmi che si occupano di trasformare un’immagine contenente del testo, solitamente acquisita utilizzando uno scanner, in un documento digitale liberamente modificabile ricorrendo ad un editor di testo. Solitamente, le applicazioni OCR più abili sono anche in grado di rilevare la “formattazione” del documento cercando di riprodurne l’impostazione grafica il più fedelmente possibile.
Sul mercato è oggi disponibile una gran varietà di OCR ma il numero di quelli che sappiano coniugare gratuità con efficienza ed efficacia in fase di riconoscimento dei caratteri è piuttosto limitato.
In passato abbiamo ripetutamente affrontato il tema del riconoscimento ottico dei caratteri presentando numerose soluzioni, sia a costo zero che a pagamento (ved. questi nostri articoli). Oggi però torniamo sull’argomento presentandovi CuneiForm OpenOCR, un software che raccoglie l’eredità del software commerciale CuneiForm e che da qualche anno è disponibile come applicazione opensource. In calce a questa pagina, infatti, è disponibile non solo il file d’installazione del programma ma anche un pacchetto contenente il suo codice sorgente.
Precisiamo subito che CuneiForm OpenOCR non è un programma recentissimo e non è particolarmente abile nel riconoscere il layout e la formattazione di un documento. Il programma dovrebbe essere utilizzato, quindi, solo per avviare il riconoscimento ottico dei caratteri su documenti poco complessi in termini di formattazione.
Dopo aver prelevato il file d’installazione per Windows cliccando qui, al termine della procedura d’installazione, si noterà una piccola discrepanza (noi abbiamo effettuato l’installazione su una macchina Windows 7).
Nel menù Tutti i programmi di Windows, infatti, si noterà la presenza di alcune voci piuttosto strane:
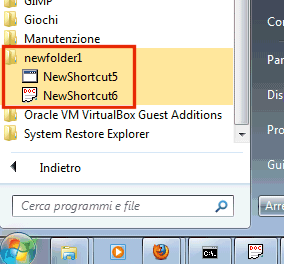
Si tratta delle voci di menù aggiunte dalla procedura d’installazione di CuneiForm OpenOCR. Purtroppo, la loro denominazione non è corretta: il gruppo newfolder1 dovrà quindi essere manualmente rinominato facendovi clic col tasto destro del mouse, cliccando su Proprietà infine digitando CuneiForm OpenOCR nell’apposita casella.
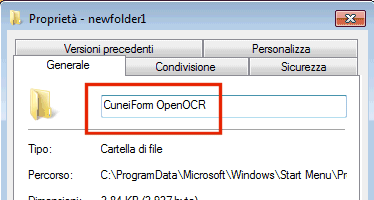
Analoga operazione dovrà essere effettuata sia sul collegamento NewShortcut5 denominandolo Riconoscimento batch sia sul collegamento NewShortcut6 chiamandolo CuneiForm OpenOCR.
Dopo l’intervento manuale, il menù Start di Windows dovrebbe così presentarsi:
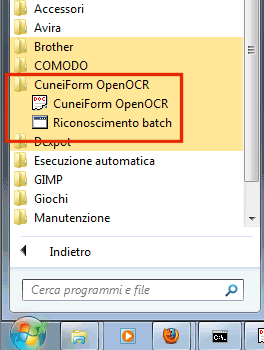
CuneiForm OpenOCR è il componente principale del software OCR mentre Riconoscimento batch consentirà di avviare il riconoscimento ottico, automaticamente, su più documenti.
Sui sistemi operativi Windows 7 e Windows Vista suggeriamo di fare clic con il tasto destro su CuneiForm OpenOCR quindi scegliere il comando Esegui come amministratore:
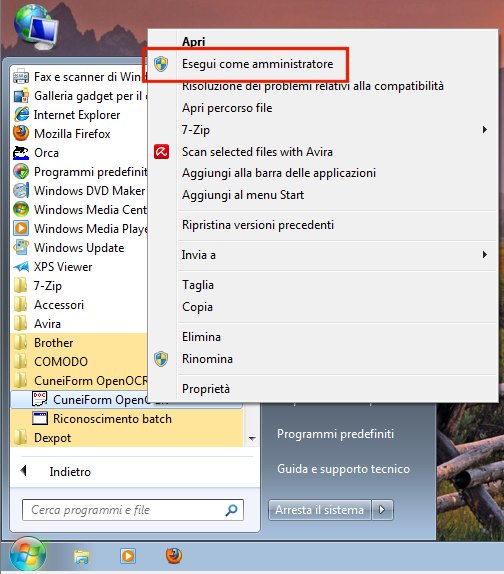
Diversamente, ad ogni avvio del programma, verrebbe mostrato il seguente messaggio d’errore:
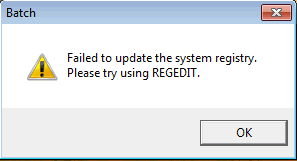
La medesima operazione (avvio del programma con i diritti di amministratore) dev’essere effettuata nel caso di Riconoscimento batch. Effettuata una volta, non sarà poi più necessario ripeterla.
CuneiForm OpenOCR è capace di rilevare il testo da riconoscere direttamente interfacciandosi con il driver dello scanner oppure esaminando il file d’immagine trasmesso dall’utente. Ciò che non è in grado di fare è il riconoscimento ottico dei caratteri a partire da un file PDF contenente, ad esempio, elementi grafici (i.e. pagine a loro volta precedentemente acquisite tramite scanner).
Per iniziare l’acquisizione di un documento con CuneiForm OpenOCR è sufficiente avviare il programma quindi cliccare sul primo pulsante della barra degli strumenti (Recognition wizard):
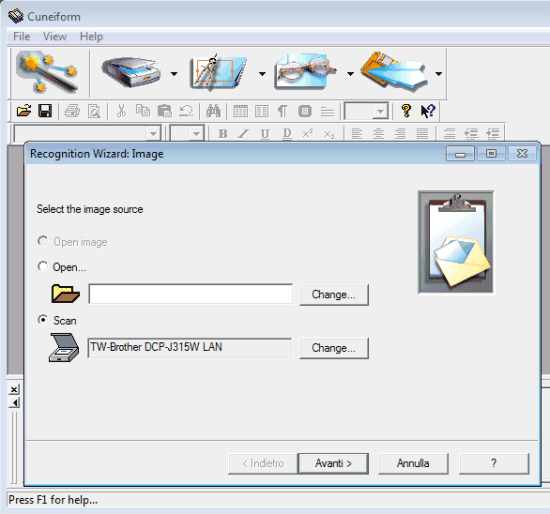
La finestra che verrà proposta consente di scegliere il file d’immagine da aprire o di specificare lo scanner da impiegare per l’acquisizione del documento.
Optando per l’uso dello scanner, attraverso le successive schermate, si potranno impostare alcune preferenze come i bordi del documento, la risoluzione per la scansione, il range di colori, luminosità, contrasto e così via.
Purtroppo, però, abbiamo notato come CuneiForm OpenOCR non sia in grado di interfacciarsi correttamente con tutti i driver TWAIN degli scanner disponibili oggi sul mercato. Con alcuni device, infatti, OpenOCR avvia la procedura di acquisizione del documento ma, al termine di essa, mostra il laconico messaggio d’errore “Can’t save the image“. In questo caso, è purtroppo necessario ripiegare sul riconoscimento ottico dei caratteri a partire da un file d’immagine. In altre parole, il documento va acquisito da scanner utilizzando un altro programma quindi salvato come immagine.
Allo scopo è possibile ricorrere all’uso di IrfanView, noto software che, tra le varie funzionalità, consente di acquisire immagini e documenti dallo scanner. Dopo aver prelevato IrfanView da questa pagina ed eventualmente tradotto la sua interfaccia in italiano (per procedere è necessario scaricare questo file, eseguirlo, avviare il programma, cliccare sul menù Options, Change language quindi su Italian.dll), si dovrà scegliere lo scanner da utilizzare (comando File, Seleziona sorgente TWAIN):
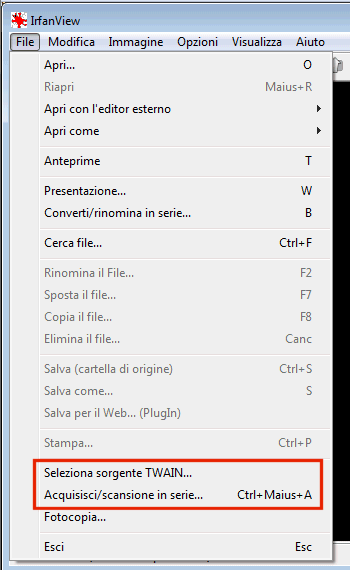
Cliccando su Acquisisci/scansione in serie…, si potrà avviare la procedura di acquisizione di un documento oppure di tutta una serie di pagine.
La finestra che apparirà a video consenterà di scegliere se limitarsi ad acquisire una sola pagina (Immagine singola, mostra immagine acquisita nel visualizzatore) oppure un insieme di esse (Immagini multiple (modalità in serie)).
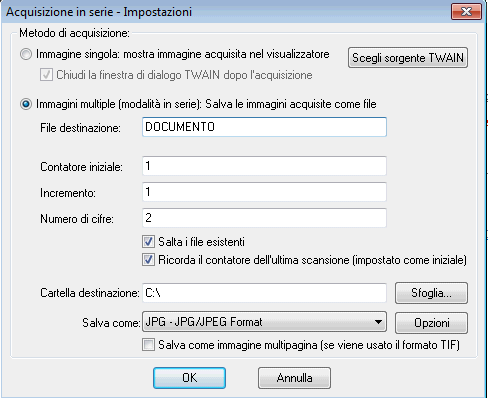
Nel secondo caso, le immagini saranno memorizzate sul disco fisso ciascuna come file d’immagine separato. Tutti i vari file potranno poi essere “dati in pasto” ad OpenOCR.
Le varie pagine potranno essere acquisite una dopo l’altra, senza mai abbandonare l’interfaccia dello scanner TWAIN. I file saranno salvati su disco, nella directory specificata, secondo le preferenze impostate in IrfanView:
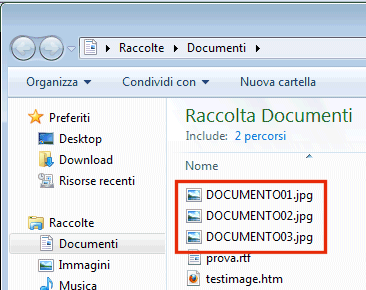
A questo punto, soprattutto nel caso in cui si siano acquisite molte pagine sotto forma di file d’immagine, suggeriamo di aprire il software Riconoscimento batch, l’altra applicazione che è parte del pacchetto di CuneiForm OpenOCR.
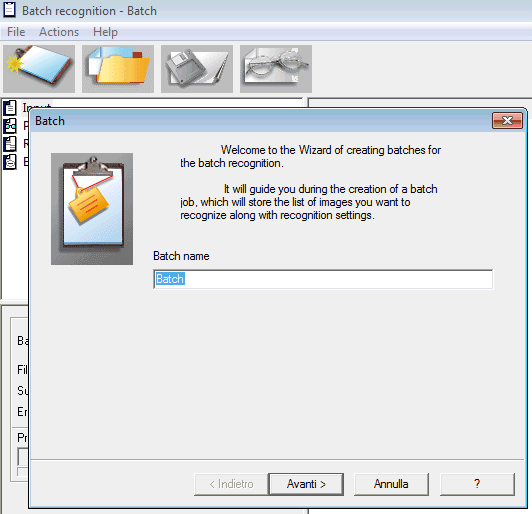
Una volta avviata, è necessario cliccare sul menù Actions, Create new batch oppure sul primo pulsante da sinistra della barra degli strumenti. OpenOCR richiederà di assegnare un nome alla procedura batch ossia alla conversione automatica che si sta configurando, quindi si dovrà impostare la lingua utilizzata nei documenti, indicare se sono presenti tabelle o immagini e così via:
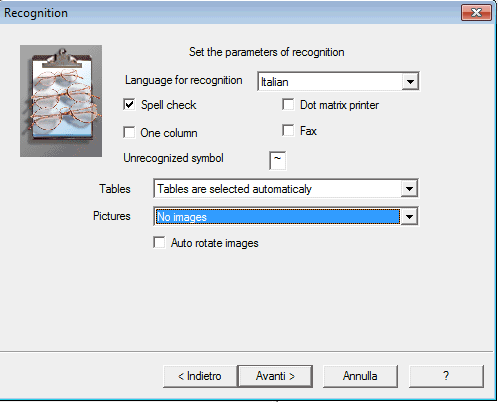
A questo punto, cliccando sul piccolo pulsante visualizzato in figura, si dovrà selezionare la cartella all’interno della quale si sono salvati tutti i file d’immagine acquisiti dallo scanner:
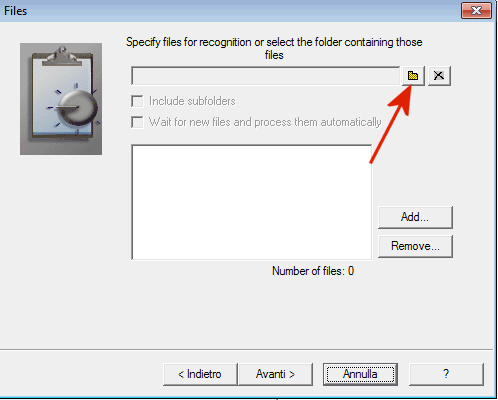
Attraverso la schermata successiva (Specify what should be done with input files after processing) si dovrà stabilire cosa fare dei file d’immagine acquisiti dallo scanner (nulla, procedere alla loro eliminazione o spostarli in un’altra cartella).
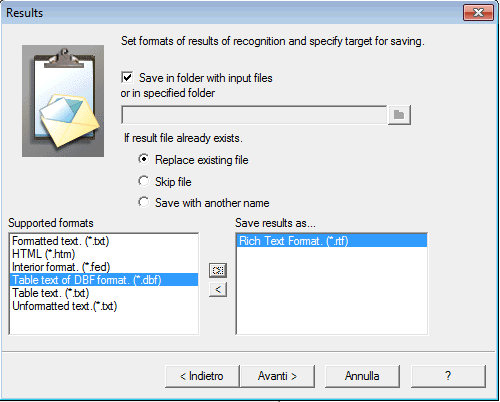
Come ultimo passo, si dovrà scegliere uno o più formati nei quali il contenuto dei vari file d’immagine sarà automaticamente convertito.

/https://www.ilsoftware.it/app/uploads/2025/06/windows-10-11-perdita-400-milioni-utenti.jpg "Crescita di Windows al palo: è davvero la fine di un’era?")
/https://www.ilsoftware.it/app/uploads/2025/06/windows-11-25H2-uscita.jpg "Microsoft annuncia Windows 11 25H2: ritardo di un anno per Windows 12")
/https://www.ilsoftware.it/app/uploads/2025/06/confronto-prestazioni-windows-10-windows-11.jpg "Microsoft: Windows 11 è il doppio più veloce di Windows 10. Sarà vero?")