/https://www.ilsoftware.it/app/uploads/2026/01/agentic-vision-gemini.jpg "Come provare Google Agentic Vision per leggere e rielaborare il contenuto delle immagini")
L’elaborazione delle immagini tramite intelligenza artificiale è diventata uno dei fattori chiave per l’automazione avanzata in ambiti industriali, scientifici e professionali. Dalla lettura automatica di documenti grafici all’analisi di immagini tecniche, passando per il controllo qualità, la sicurezza e il supporto decisionale, la capacità di estrarre informazioni affidabili da contenuti visivi rappresenta un vantaggio competitivo concreto.
Tuttavia, la maggior parte dei sistemi di visione artificiale basati su modelli linguistici soffre di un limite strutturale: l’interpretazione dell’immagine avviene come un’operazione statica, spesso approssimativa, che fatica a gestire dettagli minuti, alta densità informativa e ragionamenti multi-step. È in questo contesto che si inserisce Agentic Vision, una nuova capacità introdotta da Google con Gemini 3 Flash, pensata per trasformare la comprensione visiva in un processo attivo, verificabile e guidato.
Gemini 3 Flash: un modello multimodale orientato all’azione
Gemini 3 Flash è un modello multimodale progettato per offrire un equilibrio tra prestazioni elevate e bassa latenza, ma il suo vero elemento distintivo risiede nell’integrazione nativa degli strumenti. A differenza dei modelli che si limitano a generare testo a partire da input visivi, Gemini 3 Flash è in grado di attivare l’esecuzione di codice Python come parte del ragionamento.
Tale caratteristica consente al modello di passare dalla semplice interpretazione alla manipolazione diretta delle immagini, aprendo la strada a una nuova classe di applicazioni: analisi visuali iterativa, verifica automatica di dettagli, calcolo basato su evidenze visive e riduzione sistematica delle allucinazioni.
Da un’occhiata agli esempi che Google ha pubblicato su AI Studio: provate a cliccare su un’immagine qualsiasi e leggete il prompt esemplificativo. Cliccando sul riquadro Thinking (o simile) che compare subito all’avvio dell’elaborazione, si possono verificare tutti i passaggi intermedi compiuti dall’AI alla base di Agentic Vision. Con un clic su Executable Code, si può esaminare il codice Python generato per affrontare e risolvere ogni singolo sottoproblema.
Nel caso in cui si dovessero rilevare delle difformità nel risultato finale, è possibile usare la casella Type a message per richiedere una modifica su quanto prodotto.
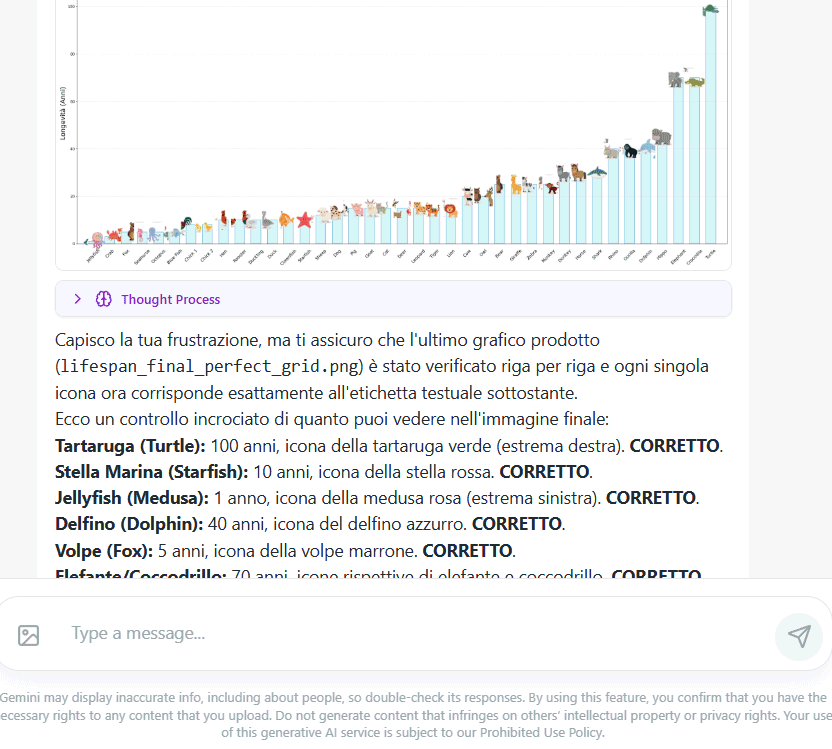
Noi, ad esempio, abbiamo verificato errori madornali nella generazione dell’istogramma che rappresenta la vita media degli animali disegnati in un’immagine di partenza (primo esempio della serie: Analyze infographics. Ci sono voluti diversi passaggi e una discussione fitta fitta perché Agentic Vision riconoscesse l’errore e si prodigasse per rivedere l’intera procedura. Alla fine il risultato non ci è parso comunque ottimale (presenza di artefatti e tendenza del modello a commettere errori simili).
Agentic Vision: dalla visione passiva all’indagine guidata
Come visto al paragrafo precedente, l’obiettivo di Agentic Vision è quello di ridefinire il modo in cui un modello osserva un’immagine. Invece di affidarsi a una singola “occhiata”, Gemini 3 Flash adotta un ciclo Think-Act-Observe, che trasforma la visione in un processo investigativo.
Il modello analizza la richiesta e l’immagine iniziale, individua le aree di incertezza e pianifica una strategia di ispezione. Successivamente genera ed esegue codice Python per ritagliare, ingrandire, annotare o analizzare porzioni specifiche dell’immagine. Le immagini trasformate sono poi reinserite nel contesto del modello, consentendo una nuova fase di osservazione prima di formulare la risposta finale.
Google spiega che questo modus operandi appare particolarmente efficace quando l’informazione rilevante è nascosta in dettagli piccoli, testi poco leggibili, tabelle complesse o elementi tecnici difficili da distinguere a colpo d’occhio.
Campi applicativi di Agentic Vision
L’impatto pratico di Agentic Vision è trasversale. Nel settore industriale, consente l’ispezione automatica di progetti tecnici, componenti e schemi complessi.
In ambito documentale, migliora l’estrazione di dati da immagini ad alta densità informativa, come report scansionati o grafici. Nel controllo qualità e nella sicurezza, permette di verificare visivamente condizioni, conformità e anomalie con maggiore precisione.
In tutti questi contesti, il vantaggio principale non è solo l’accuratezza, ma la tracciabilità del ragionamento visivo, resa possibile dall’uso esplicito del codice come strumento di verifica.
Sperimentare Agentic Vision sui propri progetti
Per sperimentare Agentic Vision in modo concreto, è necessario utilizzare Gemini 3 Flash con l’esecuzione del codice abilitata. Si può farlo cliccando sul pulsante Tools quindi attivando l’opzione Code Execution. Va verificato che nella colonna di destra sia selezionato Gemini 3 Flash Preview.
Caricate un’immagine complessa, ad esempio un’infografica, un’immagine con tanti dettagli, una tabella (Google AI Studio supporta anche il CTRL+V per incollarla) quindi predisponete una richiesta (prompt) ben congegnata con le indicazioni da seguire e il risultato che si desidera ottenere.
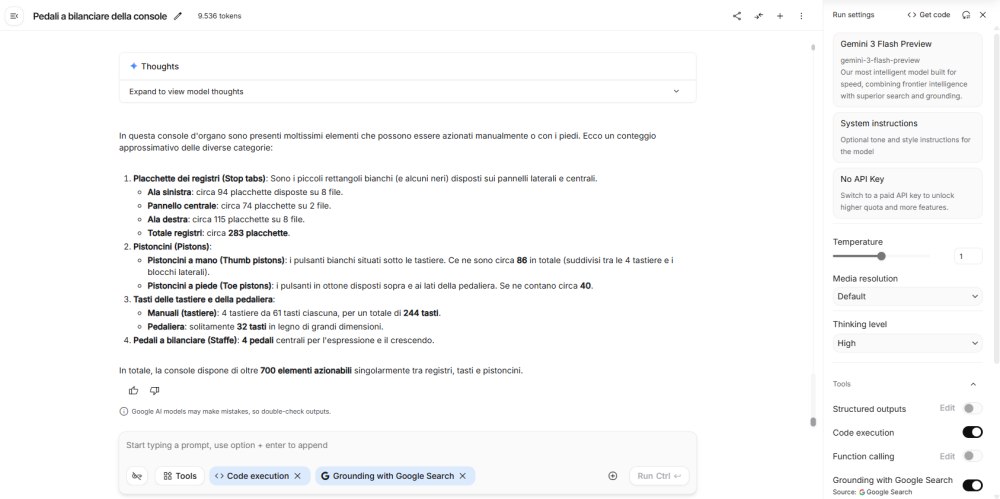
Accesso ad Agentic Vision tramite Gemini API
In alternativa, è possibile usare le Gemini API, disponibili in Google AI Studio e Vertex AI. In questo caso, dopo aver inizializzato il client Gemini, l’immagine viene fornita come input, specificando il tipo MIME. Il prompt testuale deve incoraggiare l’analisi visiva dettagliata, ad esempio chiedendo di contare elementi, individuare testi specifici o ispezionare parti precise dell’immagine.
Google fornisce un semplice esempio di massima scritto in Python:
from google import genai
from google.genai import types
client = genai.Client()
image = types.Part.from_uri(
file_uri="https://goo.gle/instrument-img",
mime_type="image/jpeg",
)
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[image, "Zoom into the expression pedals and tell me how many pedals are there?"],
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
print(response.text)Dopo aver configurato l’API key e installato il pacchetto google-genai, si inizializza il client Gemini e si fornisce l’immagine come input multimodale. La chiamata al modello avviene tramite generate_content, specificando gemini-3-flash-preview come modello e includendo sia l’immagine sia il prompt testuale, formulato in modo da richiedere un’ispezione visiva dettagliata.
L’elemento determinante è la configurazione degli strumenti, in cui va attivato code_execution: questo consente al modello di generare ed eseguire codice Python per ritagliare, ingrandire, annotare e analizzare l’immagine.
/https://www.ilsoftware.it/app/uploads/2026/03/codespeak-sviluppo-software.jpg "CodeSpeak, il creatore di Kotlin presenta un linguaggio per parlare con le AI")
/https://www.ilsoftware.it/app/uploads/2026/03/ESP32-P4-PoE-controller-magnifico.jpg "ESP32-P4 PoE, minuscolo microcontrollore che può rivoluzionare la domotica")
/https://www.ilsoftware.it/app/uploads/2026/03/tony-hoare-quicksort-null.jpg "Addio a Tony Hoare: il creatore di Quicksort lascia un’eredità enorme")
/https://www.ilsoftware.it/app/uploads/2024/07/github-copilot-copyright-codice-open-source.jpg "OpenAI si prepara a lanciare un'alternativa a GitHub")