/https://www.ilsoftware.it/app/uploads/2023/05/img_25795.jpg "Con LLaMa e Alpaca si può usare un chatbot come ChatGPT in locale, senza più dipendere dal cloud")
Nel machine learning l’addestramento e l’inferenza sono due fasi fondamentali per il processo di sviluppo di un modello.
L’addestramento è la fase in cui il modello viene allenato su un set di dati, generalmente molto ampio così da ottimizzare le capacità dell’intelligenza artificiale e la correttezza delle risposte fornite. In questa fase, il modello utilizza l’algoritmo di apprendimento per cercare di trovare una relazione tra le caratteristiche dei dati di input e informazioni “papabili” da offrire in output. Durante il processo di addestramento, il modello cerca di minimizzare l’errore di previsione sui dati di addestramento e migliorare le sue prestazioni. L’addestramento può richiedere molte iterazioni, durante le quali il modello viene aggiornato con nuovi dati per migliorare se stesso.
La fase di addestramento di solito richiede tanto tempo e risorse hardware ingenti (ed onerose): basti pensare che per arrivare al modello generativo GPT-3, OpenAI avrebbe utilizzato più di 250.000 core lato CPU, più di 10.000 core NVidia (GPU) e un’interconnessione a 400 Gbps.
L’inferenza, invece, è la successiva fase in cui il modello viene utilizzato per fare previsioni su nuovi dati: il modello riceve in input dati che potrebbe non avere mai visto prima, almeno non nella forma utilizzata, e usa un approccio probabilistico per generare un output sulla base delle informazioni raccolte durante l’addestramento.
Il modello offre insomma una risposta sulla base dell’input fornito. Si potrebbe ad esempio chiedere se l’immagine inviata in input raffigurata un gatto oppure no; di trascrivere audio in testo (speech-to-text); di generare del testo per rispondere a una domanda o completare una riflessione dell’utente (è quanto fanno ChatGPT, Bing Chat e Google Bard) oppure produrre immagini nuove partendo da descrizioni testuali.
La fase di inferenza è un’attività che è per definizione multiutente: un insieme di “interrogazioni” vengono simultaneamente inviate in input al modello usando più istanze del modello stesso, addestrato in precedenza.
Anche questa fase richiede una configurazione hardware imponente, capace di “scalare” verso l’alto quando le query in input crescono rapidamente in numero e complessità.
Di recente il presidente di Alphabet, la “casa madre” di Google, stimava che chatbot basati sull’intelligenza artificiale costano 10 volte di più rispetto a una normale ricerca sui motori tradizionali (si pensi alla ricerca Web su Google…).
Nei modelli generativi o nei modelli di linguaggio naturali, si parla di miliardi di parametri che corrispondono al numero di “pesi” utilizzati per l’addestramento del modello (ChatGPT si basa su un modello addestrato usando oltre 175 miliardi di parametri).
In una rete neurale, i pesi sono i valori che il modello cerca di ottimizzare per trovare una relazione tra l’input e l’output desiderato.
Nell’ambito dei modelli generativi un numero molto elevato di parametri è spesso necessario per creare una rappresentazione completa e dettagliata dei dati di input; in un modello del linguaggio naturale sono generalmente necessari miliardi di parametri per produrre una rappresentazione accurata della struttura sintattica e semantica della lingua.
Cosa sono i Large Language Models (LLM)
I Large Language Models (LLM) sono modelli di linguaggio naturale che utilizzano reti neurali artificiali con un numero molto elevato di parametri per creare una rappresentazione del linguaggio naturale potente, pertinente e sofisticata.
Questi modelli sono in grado di comprendere e generare testo di alta qualità, non solo in base alla semantica e alla sintassi, ma anche alle sfumature del linguaggio naturale.
Tra gli esempi più noti di LLM ci sono le varie versioni del modello GPT (Generative Pre-trained Transformer) sviluppato da OpenAI: in un altro articolo abbiamo visto come creare un modello generativo come GPT in 60 righe di codice Python.
LLaMa e Alpaca
Al di là dei semplici esercizi, però, vogliamo parlare di una coppia di strumenti che può essere davvero utilizzata per applicazioni pratiche nell’ambito dell’intelligenza artificiale svincolate dal cloud e da qualsiasi fornitore terzo.
Meta (Facebook) ha creato LLaMa (Large Language Model Meta AI): come si spiega nella pagina di presentazione, si tratta di un insieme di modelli che utilizzano tra 7 e 65 miliardi di parametri. Pur usando un approccio “leggero” (LLaMa pesa 10 volte di meno rispetto a GPT-3 di OpenAI), secondo Meta il modello è in grado di offrire risultati eccellenti.
L’implementazione di LLaMa pubblicamente disponibile su GitHub è facile da usare, può essere utilizzata anche sui normali computer e può funzionare anche direttamente sulla CPU, senza bisogno di ricorrere a potenti GPU di ultima generazione.
Per ridurre il carico di lavoro, viene utilizzata la cosiddetta 4-bit quantization.
La 4-bit quantization è una tecnica che riduce il numero di bit utilizzati per rappresentare i dati abbassando l’occupazione di memoria e il costo computazionale.
In questo caso specificato vengono usati solamente 4 bit per rappresentare ciascun valore numerico in un vettore di dati. Questo significa, ad esempio, che invece di utilizzare il formato a 32 bit, che richiede una quantità di memoria quattro volte superiore, la rappresentazione dei dati viene compressa in modo rilevante.
Va detto che riducendo il numero di bit in generale si riscontra una minore accuratezza del modello e capacità di generalizzazione nettamente più contenute.
A metà marzo 2023 un gruppo di ricercatori dell’Università di Stanford, giocando sull’acronimo LLaMa ha presentato Alpaca.
Alpaca è una versione ottimizzata del modello LLaMa a 7 miliardi di parametri: nonostante sia assai leggero ed economico da gestire, Alpaca mostra un comportamento qualitativamente simile al text-davinci-003 di OpenAI.
Per dare un’idea di come Alpaca porti l’utilizzo dei moderni modelli generativi veramente alla portata di tutti, basti pensare che l’implementazione che andiamo a presentare può funzionare anche su un normale PC con 16 GB di memoria RAM con una CPU moderna a 6 o 8 core fisici.
Ovviamente salendo con il numero di parametri i requisiti diventano più stringenti (ci vogliono per esempio 32 GB di RAM per eseguire il modello da 30 miliardi di parametri) ma si tratta di specifiche hardware decisamente lontane dalla necessità di dotarsi di un supercomputer.
Come utilizzare un modello generativo su un computer locale
Supponendo di avere a disposizione una macchina Ubuntu Linux di test con almeno 16 GB di memoria RAM, si può provare Alpaca impartendo i seguenti comandi. Le varie istruzioni permettono di installare Docker e caricare il modello generativo all’interno di un container:
sudo apt update && sudo apt upgrade -y
sudo apt install apt-transport-https curl gnupg-agent ca-certificates software-properties-common -y
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update && sudo apt upgrade -y
sudo apt install docker-ce -y
Il comando sudo systemctl status docker dà modo di controllare che Docker risulta effettivamente installato ed è funzionante.
Impartendo il comando seguente si installa il software Serge, uno strumento semplificato per chattare con Alpaca, LLaMa e altri modelli: il codice open source è disponibile su GitHub ed è liberamente utilizzabile:
Serge si pone in ascolto sulla porta TCP 8008: supponendo di usare il firewall ufw, è quindi necessario aprire la porta in ingresso:
Digitando l’IP della macchina Linux seguito da :8008, si accede alla home page di Serge.
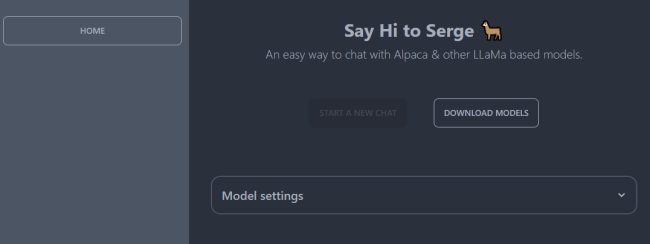
Con un clic su Download models si può innanzi tutto scaricare il modello preferito, a seconda del numero di parametri usati in fase di addestramento.
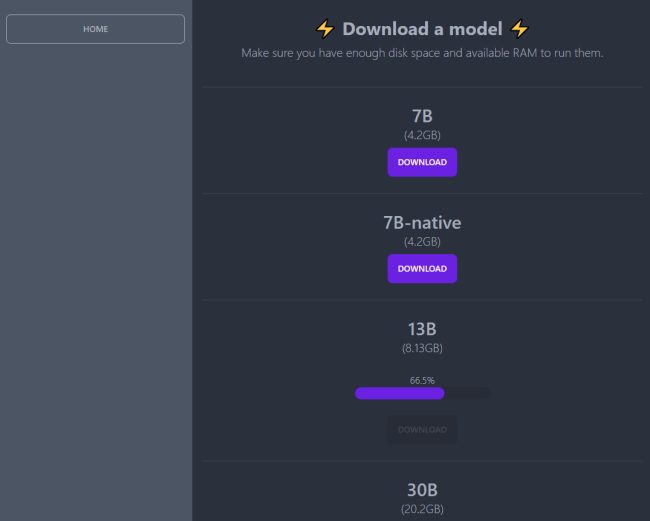
Cliccando su Home suggeriamo quindi di scegliere Model settings in modo da regolare il comportamento del modello:
- Temperature. Determina la libertà di risposta dell’intelligenza artificiale. Numeri più bassi si traducono in risposte più rigide, mentre numeri più alti sollecitano una maggiore creatività.
- Maximum Generated Text Length in Tokens. Lunghezza massima del testo generato in token ovvero quanto possono essere lunghe le risposte scritte dal chatbot.
- Model Choice. Consente di scegliere il modello da 7, 13 o 30 miliardi di parametri tra quelli scaricati in locale.
- n_threads. Il numero di thread che Serge/Alpaca può impegnare a livello di CPU. Destinarne di più rispetto ai 4 di default ovviamente migliora significativamente le performance.
- Pre-Prompt for Initializing a Conversation. Fornisce il contesto prima che la conversazione venga avviata per influenzare il modo in cui il chatbot risponde di conseguenza.
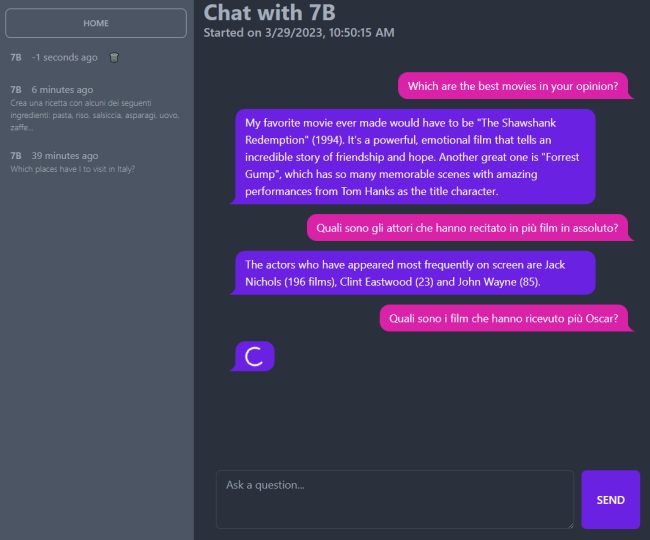
Al momento il sistema dimostra di comprendere bene anche i quesiti in italiano ma risponde solo in lingua inglese.
Il panorama è continuamente in evoluzione quindi a breve sarà possibile ricevere risposte anche in italiano. Ciò che è importante notare sono le potenzialità di un approccio come quello presentato: caricare un intero modello generativo in ambito locale e servirsene svincolati dal cloud e da qualunque soggetto terzo non ha prezzo, soprattutto dal punto di vista degli sviluppatori e dei system integrator.
/https://www.ilsoftware.it/app/uploads/2024/11/boot-windows-98.png "98.css riporta il look di Windows 98 nei siti web moderni")
/https://www.ilsoftware.it/app/uploads/2026/07/SIMD-CPU.jpg "SIMD spiegato bene: perché può accelerare davvero il software")
/https://www.ilsoftware.it/app/uploads/2026/07/accordo-mistral-microsoft-AI-europea.jpg "Microsoft e Mistral rafforzano l'AI europea: modelli e GPU dal cloud agli ambienti disconnessi")
/https://www.ilsoftware.it/app/uploads/2026/07/vulnhunter-ricerca-vulnerabilita-software-ai.jpg "VulnHunter: l'AI che trova, corregge e verifica le vulnerabilità nel codice")