/https://www.ilsoftware.it/app/uploads/2026/04/attacco-hash-password-sicure.jpg "La verità sulle password: quanto serve davvero per hackerarle con hashcat e GPU moderne")
Quando si affronta il tema della sicurezza delle password, si tende spesso a utilizzare concetti come complessità (varietà di caratteri utilizzati), lunghezza (numero di caratteri) ed entropia (grado di imprevedibilità della password). Tuttavia, questi elementi risultano davvero comprensibili solo quando sono analizzati nel contesto concreto di un attacco informatico reale, in cui è possibile vedere come influenzano la resistenza della password ai tentativi di violazione.
Se una password può essere individuata in 2 secondi anziché in 20 anni, non si tratta di una differenza teorica, ma di un impatto concreto sulla sicurezza: nel primo caso può essere violata quasi immediatamente, mentre nel secondo richiederebbe tempi impraticabili anche con strumenti avanzati.
L’importanza reale della scelta della password: una questione di tempo computazionale
Quando si scegliere una password a protezione dell’accesso a un qualunque servizio, sia online che offline, la sua complessità e la sua lunghezza – come abbiamo visto in apertura – sono cruciali. Una password composta da soli 6 numeri, ad esempio 992266, è debolissima perché il numero di combinazioni possibili è soltanto pari a 106 = 1.000.0000.
Con hardware moderno, il tempo di cracking di queste password numeriche è istantaneo.
Una password come mauro1970 presenta lo stesso problema perché contiene un nome comune di persona e un anno (presumibilmente l’anno di nascita): è questo uno schema frequentissimo per tante password che, purtroppo, gli utenti continuano a scegliere e usare ancora oggi.
Un attaccante in questo caso non proverà tutte le combinazioni possibili: userà un attacco a dizionario basato su wordlist ossia elenchi di parole da provare (le più frequenti usate dagli utenti nelle password) insieme ad alcune regole.
Passiamo alla scelta di una password da 10 caratteri come X9!kLm2#Qp: in questo caso la password non è particolarmente lunga ma è formata da caratteri alfanumerici e simboli. Il set di caratteri (charset) è in questo caso formato da circa 70 caratteri possibili (lettere maiuscole + minuscole + numeri + simboli). Il numero delle possibili combinazioni sale vertiginosamente:
7010 ≈ 2,8 × 1018
In pratica è 2,8 seguito da 17 zeri: per rendere l’idea, è molto più grande del numero di secondi trascorsi dall’inizio della storia umana. Anche con miliardi di tentativi al secondo, ci vorrebbero centinaia di anni per scoprire la password.

Credit infografica: Hive Systems
Quando la potenza incontra la resistenza: cosa ci dicono “12× RTX 5090” e “bcrypt (10)”
Le indicazioni presenti nello specchietto di Hive Systems rappresentano due forze contrapposte che determinano il destino di una password: la capacità dell’attaccante di provare combinazioni in rapida successione (si chiama attacco brute-force) e la capacità del sistema di rallentarlo.
Quando si legge 12× RTX 5090, si sta descrivendo uno scenario in cui l’attaccante dispone di un’infrastruttura estremamente potente, basata su GPU come la NVIDIA GeForce RTX 5090. Non si tratta di un caso limite irrealistico: oggi queste risorse sono accessibili tramite cloud o cluster distribuiti. In questo contesto, il cracking non è più un processo sequenziale ma massivamente parallelo, in cui miliardi di combinazioni possono essere provate ogni secondo.
Ciò significa che lo spazio delle password più comuni viene esplorato quasi istantaneamente, rendendo inefficaci tutte le credenziali basate su schemi (pattern) prevedibili o lunghezze ridotte.
Dall’altra parte troviamo bcrypt (10) che introduce un meccanismo opposto: rallentare deliberatamente ogni tentativo. Il parametro “10” indica un fattore di costo esponenziale, che obbliga il sistema a eseguire un numero elevato di iterazioni per ogni verifica. bcrypt è un algoritmo di hashing: ci torneremo tra poco.
Il punto chiave è che questi due elementi non agiscono separatamente, ma si bilanciano continuamente. L’attaccante aumenta la potenza computazionale per ridurre i tempi; il difensore introduce algoritmi più lenti per aumentarli. In mezzo a questo equilibrio si trova la password: se è corta o prevedibile, verrà comunque trovata; se è lunga e casuale, anche una batteria composta da molte GPU diventa inefficace.
Perché il password cracking moderno è dominato dalle GPU
Nel password cracking la differenza tra CPU e GPU non riguarda semplicemente la velocità, ma il modo in cui il lavoro è suddiviso e gestito.
Una CPU tradizionale dispone di pochi core molto potenti, progettati per gestire operazioni complesse, ramificazioni e carichi eterogenei; una GPU come la NVIDIA GeForce RTX 5090, invece, è composta da migliaia di core più semplici, ottimizzati per eseguire la stessa istruzione su enormi quantità di dati in parallelo.
Il cracking delle password si adatta perfettamente a questo modello perché ogni tentativo è indipendente: mentre una CPU può testare poche decine di migliaia di password al secondo distribuendo il lavoro su pochi thread, una GPU può lanciare decine di migliaia di thread simultanei.
Questo porta a ordini di grandezza completamente diversi: da migliaia di tentativi al secondo a milioni o miliardi. Tuttavia, questo vantaggio dipende dal tipo di algoritmo usato (ne parliamo più avanti): funzioni veloci come SHA sono ideali per il parallelismo massivo, mentre algoritmi progettati per essere lenti e “memory-hard”, come bcrypt, riducono drasticamente l’efficienza delle GPU proprio perché introducono dipendenze e costi computazionali che limitano il parallelismo.
Le GPU dominano nell’ambito del cracking delle password (non soltanto quindi nel gaming e nell’AI per addestramento e inferenza) non perché siano genericamente più potenti, ma perché il problema stesso – testare milioni di password indipendenti – è perfettamente compatibile con la loro architettura parallela.
Hashing delle password: cosa succede davvero “sotto il cofano”
Quando un sistema salva una password, non la memorizza quasi mai in chiaro ovvero così com’è. Utilizza invece un algoritmo di hashing che trasforma la password in una sua rappresentazione alfanumerica (hash). Un hash è progettato per essere:
- Deterministico: stessa input = stesso output.
- Non invertibile: dall’hash non è possibile risalire alla password.
- Sensibile: anche una piccola variazione cambia tutto
Gli algoritmi crittografici sono costruzioni matematiche progettate per resistere ad attacchi. La loro sicurezza non è garantita per definizione: è il risultato di anni di analisi pubblica, tentativi di rottura e validazione empirica. Un algoritmo è considerato affidabile finché non esiste un metodo pratico per violarne le proprietà fondamentali. Quando questo accade, l’algoritmo è progressivamente accantonato.
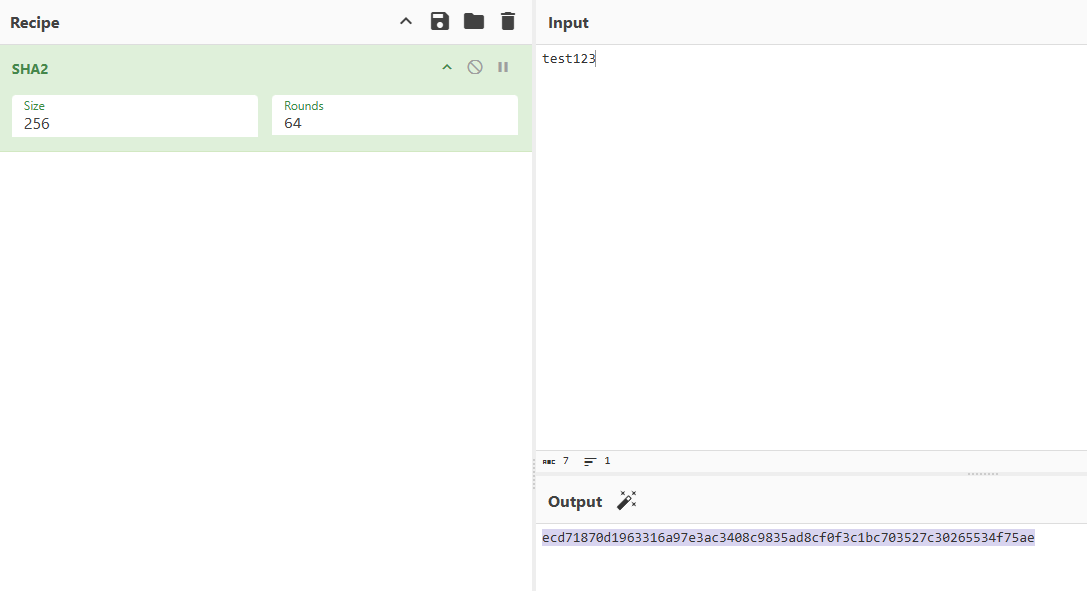
Nell’esempio in figura (l’interfaccia è quella dell’ottimo CyberChef) l’hash della stringa test123 (che ovviamente è una password terribile, anche perché sempre presente nei dizionari/wordlist) calcolato usando l’algoritmo di hashing SHA-256 della famiglia SHA-2 (256 perché l’output ovvero l’hash è formato da 256 bit ovvero 64 byte ossia 64 caratteri).
Potete anche calcolare rapidamente l’hash di qualunque stringa digitando quanto segue in una finestra PowerShell di Windows:
$password = Read-Host -Prompt "Inserisci la password" -AsSecureString; $hash = [System.BitConverter]::ToString((New-Object System.Security.Cryptography.SHA256Managed).ComputeHash([System.Text.Encoding]::UTF8.GetBytes(([System.Runtime.InteropServices.Marshal]::PtrToStringAuto([System.Runtime.InteropServices.Marshal]::SecureStringToBSTR($password)))))) -replace '-', ''; Write-Host "L'hash SHA-256 della password è: $hash"
Un problema non banale e che, ancora oggi, nel 2026, ci sono siti Web che non conservano le password degli utenti sotto forma di hash o usano algoritmi obsoleti (come MD5), facilmente aggredibili.
Se un hash è sicuro come fanno gli aggressori a risalire alle password degli utenti?
Un hash non si può invertire, ma questo non significa che le password siano al sicuro. Gli attaccanti non “rompono” l’hash nel senso matematico del termine: aggirano il problema usando potenza computazionale, statistica e comportamento umano.
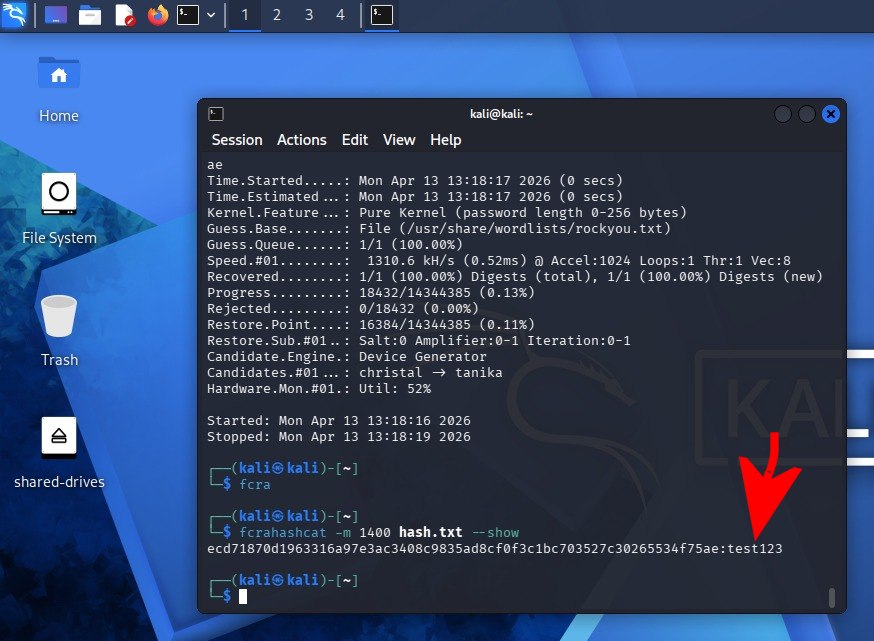
Spesso succede che gli aggressori riescano a violare sistemi altrui e raccolgano lunghi elenchi di password sotto forma di hash. Se un utente avesse scelto test123 come password, l’aggressore sa già che l’hash ecd71870d1963316a97e3ac3408c9835ad8cf0f3c1bc703527c30265534f75ae corrisponde proprio a quella password quindi può immediatamente risalare alla password in chiaro pur conoscendo solo l’hash.
Per le password più complesse, si effettua un calcolo degli hash di milioni o miliardi di password in modo tra trovare la corrispondenza esatta con l’hash precedentemente sottratto.
È questo il costo computazionale a cui facevamo riferimento in precedenza: se l’algoritmo di hashing è veloce, come accade con hash generici pensati per integrità o firma e non per la protezione delle password, la verifica può essere eseguita milioni o miliardi di volte al secondo con GPU, rendendo devastanti gli attacchi offline dopo un data breach.
Un sistema sicuro salva le password così:
hash = hash(password + salt)
Il salt migliora molto la situazione perché impedisce di riutilizzare risultati precomputati e costringe l’attaccante a lavorare su ogni hash individualmente, ma non elimina il problema di fondo: se la password scelta è debole o prevedibile, può comunque essere trovata testando candidati uno per uno. Per questo la sicurezza reale non dipende solo dal fatto che l’hash sia crittograficamente robusto, ma dal fatto che il sistema usi funzioni lente e costose da calcolare, come bcrypt o Argon2, e soprattutto dal fatto che l’utente scelga una password abbastanza lunga e imprevedibile da rendere impraticabile la ricerca.
Rischi del riutilizzo delle password
Il riutilizzo delle password introduce una grave vulnerabilità lato utente perché collega tra loro sistemi che dovrebbero essere indipendenti, trasformando una singola potenziale compromissione in un effetto a catena.
Immaginiamo un servizio del fornitore X sul quale l’utente si sia iscritto con una certa password. Supponiamo che lo stesso utente abbia usato la medesima password per registrarsi sui servizi Y, Z, W, A, B, C.
Se il servizio X, Y, Z o qualsiasi altro citato venisse in qualche modo violato e si verificasse una sottrazione dei dati, compresi gli hash delle password degli utenti, una volta che alcune di queste password fossero recuperate tramite tecniche di cracking (dictionary, rule-based o brute force), non è necessario ripetere l’attacco su altri sistemi: le credenziali sono riutilizzate direttamente in attacchi automatizzati chiamati (credential stuffing).
In altre parole, se un aggressore riuscisse a risalire alla password usata dall’utente sul servizio X, potrebbe utilizzarla per accedere a qualunque altro servizio con le medesime credenziali.
Ci sono strumenti come THC Hydra e script custom (integrati in distribuzioni come Kali Linux) che provano in parallelo le stesse combinazioni email/password su decine o centinaia di servizi (webmail, e-commerce, cloud, social,…), sfruttando proprio il fatto che molti utenti utilizzano le stesse credenziali ovunque.
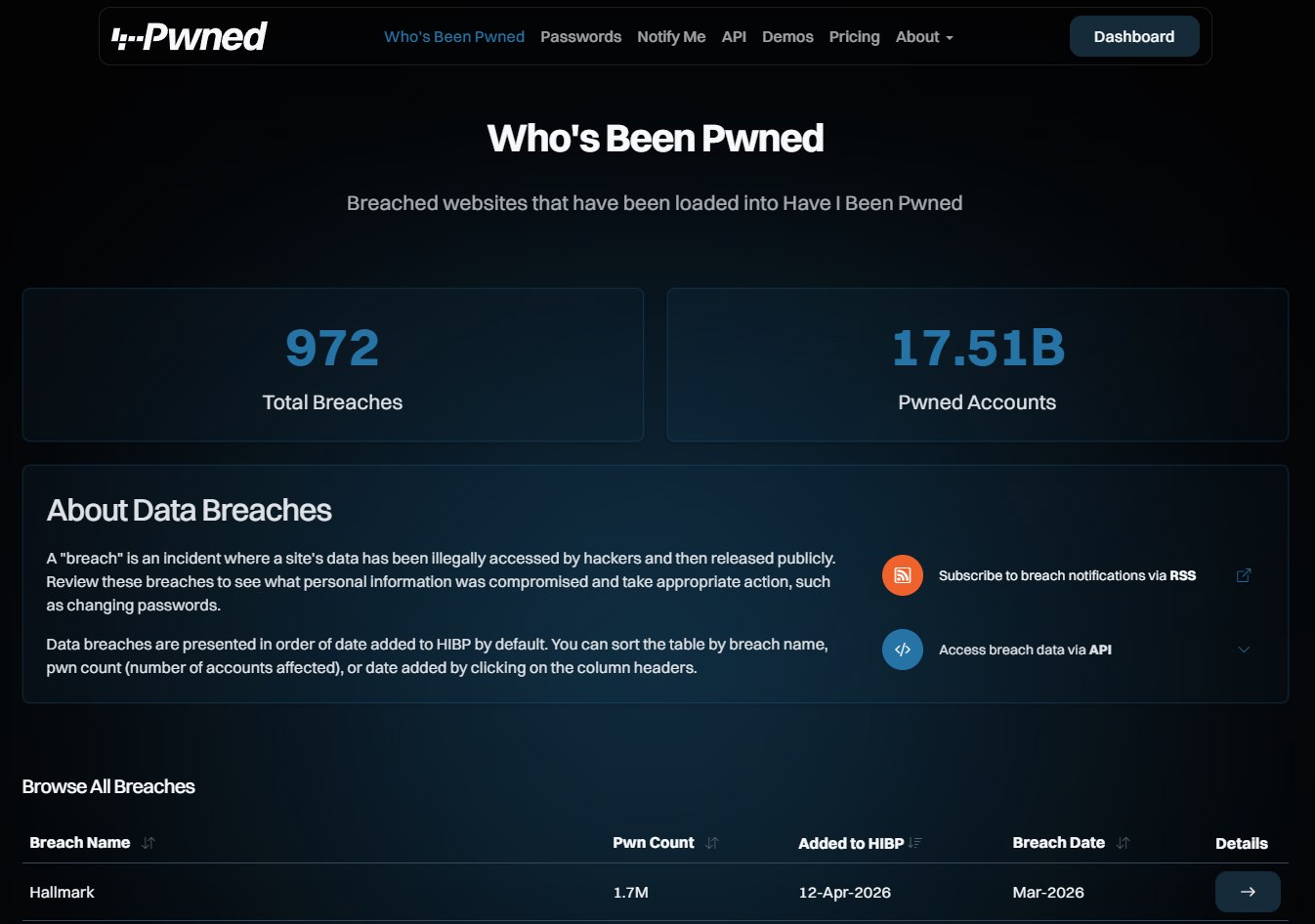
E non pensiate che la sottrazione di username e password siano incidenti informatici rari. Scorrete la lista pubblicata su Have I Been Pwned per avere un’idea del fenomeno.
Esempi pratici su Kali Linux: come avvengono davvero gli attacchi
Quando si usa Kali Linux, la prima cosa da capire è che non si parte mai da zero. Gli attacchi funzionano perché esistono già dati pronti: wordlist e hash.
Su Kali si possono trovare ad esempio dei dataset reali nella cartella ls /usr/share/wordlists/. Tra le risorse più famose c’è rockyou.txt, di default in formato compresso (sudo gunzip /usr/share/wordlists/rockyou.txt.gz), che contiene una enorma lista di password comuni. Quando un attaccante usa questa wordlist, sta testando password già usate da milioni di persone.
Se si crea un file hash.txt con la lista degli hash delle password (supponiamo SHA-256), il comando seguente permette di lanciare un attacco basato sul dizionario:
hashcat -m 1400 -a 0 hash.txt /usr/share/wordlists/rockyou.txt
Aggiungendo --potfile-disable si evita che analisi precedenti influiscano sul risultato. Il parametro -a 0 indica la volontà di eseguire un attacco a dizionario. Per accedere al responso, con le password in chiaro, basta digitare quanto segue:
hashcat -m 1400 hash.txt --show
Brute force puro: quando non ci sono wordlist
È ovvio che una password con caratteri alfanumerici “random” non può essere presente in una wordlist come rockyou.txt, quindi l’attaccante può passare al brute force puro, cioè provare sistematicamente tutte le combinazioni possibili.
Con Hashcat questo si realizza con le maschere. Esempio:
hashcat -m 1400 -a 3 hash.txt ?a?a?a?a?a?a
In questo caso -a 3 indica modalità brute force e ?a rappresenta qualsiasi carattere (lettere, numeri, simboli). Il tool proverà sequenze del tipo: aaaaaa, aaaaab, aaaaac, e così via fino a esaurire tutte le combinazioni.
Dal punto di vista tecnico, questo tipo di attacco non sfrutta pattern umani ma esplora l’intero spazio delle password. Il limite diventa quindi puramente matematico: ogni carattere aggiunto moltiplica il numero di combinazioni. È per questo che password corte vengono trovate rapidamente, mentre password lunghe e casuali diventano impraticabili anche con hardware potente.
Brute force su file ZIP
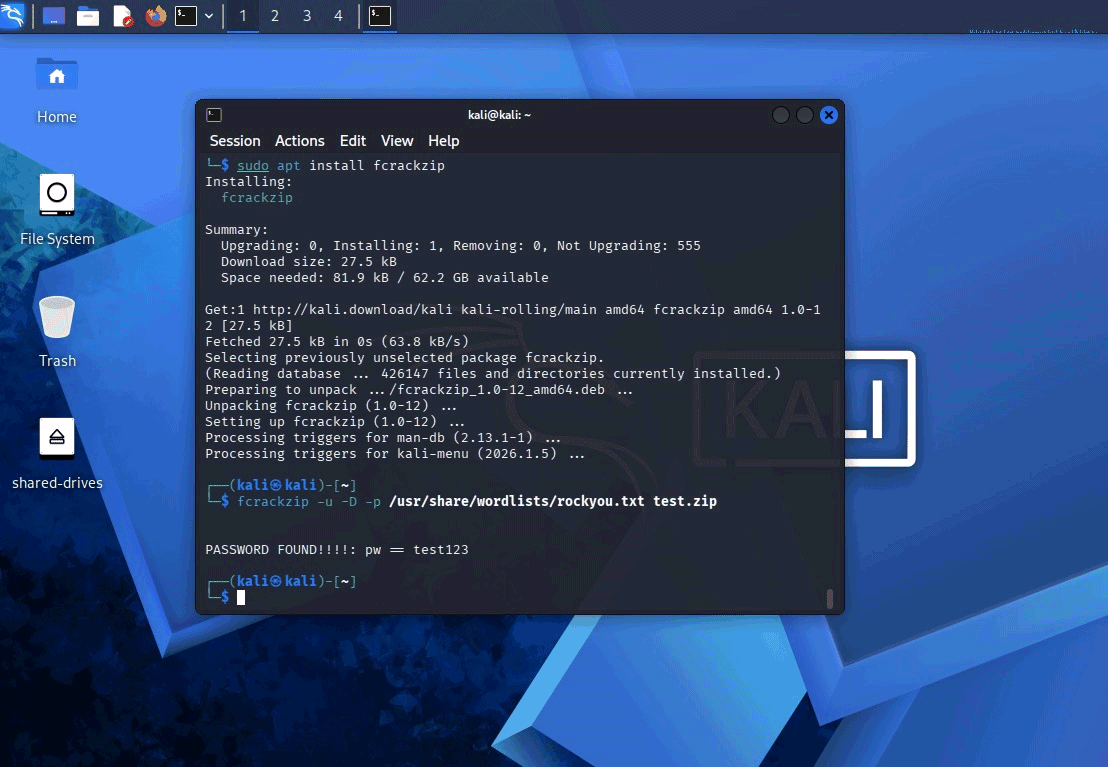
Un caso molto efficace per dimostrare il brute force puro è quello dei file compressi protetti da password. Creiamo un archivio di test:
zip --password test123 test.zip filesegreto.txt
L’attacco a dizionario basato sul file rockyou.txt può essere così eseguito:
fcrackzip -u -D -p /usr/share/wordlists/rockyou.txt test.zip
Tuttavia, se la password non fosse presente nella wordlist, si può passare al brute force:
fcrackzip -b -c a1 -l 1-6 test.zip
Dove -b attiva il brute force; -c a1 usa lettere e numeri; -l 1-6 definisce lunghezza minima e massima. Lo strumento prova tutte le combinazioni possibili nell’intervallo specificato.
Password manager: cosa sono e perché usarli
Un password manager è un software che genera, conserva e compila credenziali uniche per ogni servizio dentro un archivio protetto, di solito cifrato e sbloccato con una master password oppure con un fattore locale come biometria o PIN.
Il vantaggio tecnico principale non è la “comodità”, ma la possibilità di uscire dalla logica umana delle password prevedibili e riutilizzate.
Dal punto di vista della sicurezza, il password manager riduce due problemi importanti. Il primo è il riutilizzo delle credenziali: se ogni account ha una password diversa, una violazione su un servizio non si propaga automaticamente agli altri account. Il secondo è la debolezza statistica delle password scelte a mano: gli utenti tendono a riutilizzare parole note, anni, nomi, variazioni minime e schemi ricorrenti; un password manager, invece, può generare stringhe casuali ad alta entropia che escono dai pattern sfruttati da dizionari, regole e credential stuffing.
Tecnicamente, un buon password manager non “rende sicure” password deboli: sposta il modello di difesa dalla memoria umana alla crittografia applicata al vault (il contenitore crittografato che le contiene).
La superficie di rischio, nel caso dei password manager, si concentra soprattutto su tre punti: robustezza della master password, protezione del dispositivo su cui il vault è sbloccato e presenza di un secondo fattore per l’account del gestore stesso.
Password manager: quali usare davvero e perché evitare quelli integrati nei browser
Molti browser (Chrome, Edge, Firefox) offrono un sistema integrato per salvare password. Tuttavia, dal punto di vista della sicurezza, presentano limiti evidenti: tool come NirSoft WebBrowserPassView dimostrano concretamente il problema: possono estrarre le password salvate nei browser in modo relativamente semplice, soprattutto se l’utente è già autenticato a livello di sistema operativo.
I password manager più affidabili condividono alcune caratteristiche tecniche fondamentali:
- cifratura end-to-end (il provider non vede i dati);
- derivazione della chiave robusta (PBKDF2, Argon2, ecc.);
- supporto multi-dispositivo sicuro;
- audit di sicurezza e codice verificabile (open source o audit indipendenti).
Nel panorama open source esistono diverse soluzioni valide, ma alcune si distinguono per architettura, sicurezza crittografica e modello di utilizzo. Le più rilevanti oggi sono:
- Bitwarden. Soluzione moderna con cifratura end-to-end e modello zero-knowledge, utilizzabile anche in self-hosting; rappresenta lo standard de facto per chi vuole sincronizzazione multi-dispositivo senza rinunciare alla trasparenza.
- KeePassXC. Approccio completamente locale: il vault è un file cifrato (
.kdbx) sotto il controllo dell’utente, senza server intermedi, ideale per chi privilegia isolamento e controllo totale. - Proton Pass. Soluzione recente orientata alla privacy, con cifratura end-to-end e integrazione di alias email e passkey.
- KeeWeb. Alternativa Web/desktop compatibile KeePass (da cui è derivato KeePassXC), che lavora localmente nel browser senza inviare dati al server.
Per realizzare un password manager self-hosted in totale autonomia è possibile usare Vaultwarden, implementazione completamente aperta di Bitwarden interoperabile con quest’ultima.
Autenticazione a due fattori (2FA) o più fattori (MFA)
L’autenticazione a due fattori (2FA) aggiunge al login con nome utente e password un secondo elemento indipendente rispetto alla password: non basta più conoscere il segreto, bisogna anche dimostrare il possesso di un dispositivo oppure una caratteristica biometrica.
CISA (Cybersecurity and Infrastructure Security Agency) definisce MFA (Multi-Factor Authentication) come un controllo che richiede una combinazione di due o più authenticators appartenenti a categorie diverse, come “qualcosa che sai”, “qualcosa che hai” o “qualcosa che sei”.
Dal punto di vista tecnico, 2FA è decisiva perché interrompe il percorso più comune degli attacchi basati su password: furto di credenziali, cracking offline, phishing o riutilizzo di password compromesse.
Se un attaccante ottiene la password ma non possiede il secondo fattore, il login fallisce quindi l’autenticazione (anche con username e password corretti non può andare a buon fine).
Esistono “secondi fattori” migliori di altri
Non tutti i secondi fattori offrono però la stessa resistenza: CISA insiste sul fatto che qualsiasi MFA è meglio di nessuna MFA, ma distingue chiaramente le soluzioni resistenti al phishing da quelle più deboli, e raccomanda metodi come FIDO/chiavi di sicurezza o autenticazione basata su chiavi crittografiche rispetto a soluzioni più facili da intercettare o aggirare.
Qui sta il punto tecnico più importante: il 2FA non elimina il problema delle password, ma cambia radicalmente la probabilità di compromissione.
Un codice via SMS o una notifica push migliorano la sicurezza, ma non sono certo invulnerabili a diverse tipologie di attacco, tra cui il phishing. Posto che gli SMS sono facilmente intercettabili e falsificabili altrettanto semplicemente, se l’utente inserisce il codice di conferma ricevuto in una pagina phishing l’attaccante può immediatamente usarlo sul sito reale impersonificando l’identità altrui.
Nell’articolo su phishing e bypass di 2FA abbiamo visto come gli aggressori riescano a compromettere gli account anche quando la 2FA è abilitata, inducendo in errore gli utenti e, usando l’ingegneria sociale, ad autorizzare i loro accessi.
L’avvento delle passkey: cosa sono e come sostituiscono le password
Le passkey sono credenziali pensate per l’autenticazione passwordless: invece di basarsi su un segreto condiviso che l’utente deve ricordare e che il server deve verificare, usano una coppia di chiavi crittografiche, una privata sul dispositivo dell’utente e una pubblica registrata dal servizio.
Durante la registrazione, l’utente autorizza la creazione della passkey con un meccanismo locale del dispositivo, come impronta digitale, riconoscimento del volto o PIN; la chiave privata resta sotto il controllo del dispositivo o del gestore di credenziali, mentre il servizio remoto conserva solo la chiave pubblica. In fase di login non viene trasmessa alcuna password: il server invia una sfida (“challenge“), il dispositivo la firma con la chiave privata e il server verifica la firma con la chiave pubblica.
Questo modello cambia tutto rispetto alle password. Non esiste più un segreto condiviso da digitare, rubare, riutilizzare o sottoporre a brute force offline dopo un data breach.
Le passkey sono inoltre progettate per essere phishing-resistant, perché la credenziale è legata al nome di dominio corretto: una pagina contraffatta non ottiene una risposta valida come accade invece con una password digitata manualmente.
Dal punto di vista operativo, le passkey non sono per forza “legate a un solo dispositivo” nel senso rigido del termine: possono essere sincronizzate in modo sicuro fra i dispositivi dell’utente attraverso i credential manager, oppure essere device-bound, cioè vincolate a uno specifico hardware.
L’adozione delle passkey sta crescendo rapidamente anche se è importante che gli utenti ne conoscano il funzionamento generale.
Conclusioni
L’analisi mostra chiaramente che la sicurezza delle password non è un concetto astratto, ma una questione di tempo computazionale e comportamento umano. Gli algoritmi crittografici moderni, se utilizzati correttamente, sono solidi dal punto di vista matematico; tuttavia, nella pratica, gli attacchi non mirano a “rompere” gli algoritmi, bensì a sfruttare la prevedibilità delle password e la disponibilità di enormi risorse computazionali.
È qui che entrano in gioco i meccanismi di difesa moderni. L’autenticazione a più fattori (2FA/MFA) aggiunge un livello di sicurezza indipendente dalla password, riducendo drasticamente l’efficacia di attacchi basati su credenziali compromesse. Tuttavia, come visto, non tutte le implementazioni sono equivalenti: alcune di esse possono essere aggirate tramite phishing o attacchi in tempo reale.
L’evoluzione più significativa è rappresentata dalle passkey, che eliminano completamente il concetto di password condivisa, sostituendola con un modello crittografico basato su chiavi asimmetriche e vincolato al dominio di ciascun servizio. Questo approccio riduce drasticamente la superficie di attacco, rendendo inefficaci sia il phishing sia il brute force tradizionale.
Rammentiamo, infine, che le informazioni e gli esempi tecnici riportati in questo articolo hanno finalità esclusivamente didattiche e divulgative. Tutte le attività descritte devono essere eseguite solo su sistemi propri o su ambienti di laboratorio autorizzati.
/https://www.ilsoftware.it/app/uploads/2026/03/passkey-anti-phishing-windows-microsoft-entra.jpg "Microsoft porta accessi anti-phishing su Windows con le passkey")
/https://www.ilsoftware.it/app/uploads/2026/03/passkey-login-windows-11-bitwarden.jpg "Windows 11: login con passkey Bitwarden, addio password sul PC")
/https://www.ilsoftware.it/app/uploads/2024/01/condividere-password-in-sicurezza.jpg "Test rivela che ChatGPT e Llama creano credenziali vulnerabili")
/https://www.ilsoftware.it/app/uploads/2026/02/password-manager-non-sicuri.jpg "Password manager sotto esame: rischi nel modello zero-knowledge")