/https://www.ilsoftware.it/app/uploads/2026/03/unsloth-studio-inferenza-training-AI-locale.jpg "Unsloth Studio: addestrare modelli AI in locale ora è davvero possibile")
La gestione locale dei modelli AI ha attraversato una trasformazione turbolenta negli ultimi due anni, passando da workflow frammentati e fortemente tecnici a interfacce sempre più accessibili. L’emergere di strumenti open source dedicati al fine-tuning e all’inferenza su hardware consumer ha reso praticabile un approccio che fino a poco tempo fa richiedeva cluster GPU dedicati. Unsloth Studio è una nuova interfaccia Web che unifica addestramento, esecuzione e distribuzione dei modelli AI in un ambiente locale controllato, riducendo drasticamente la complessità operativa.
Il progetto nasce come evoluzione diretta del framework Unsloth, già noto per l’ottimizzazione dei LLM (Large Language Models) con un uso estremamente efficiente della memoria.
Le metriche dichiarate indicano un’accelerazione significativa con la definizione di una soglia tecnica capace di rendere l’addestramento locale dei modelli accessibile anche con hardware di fascia media.
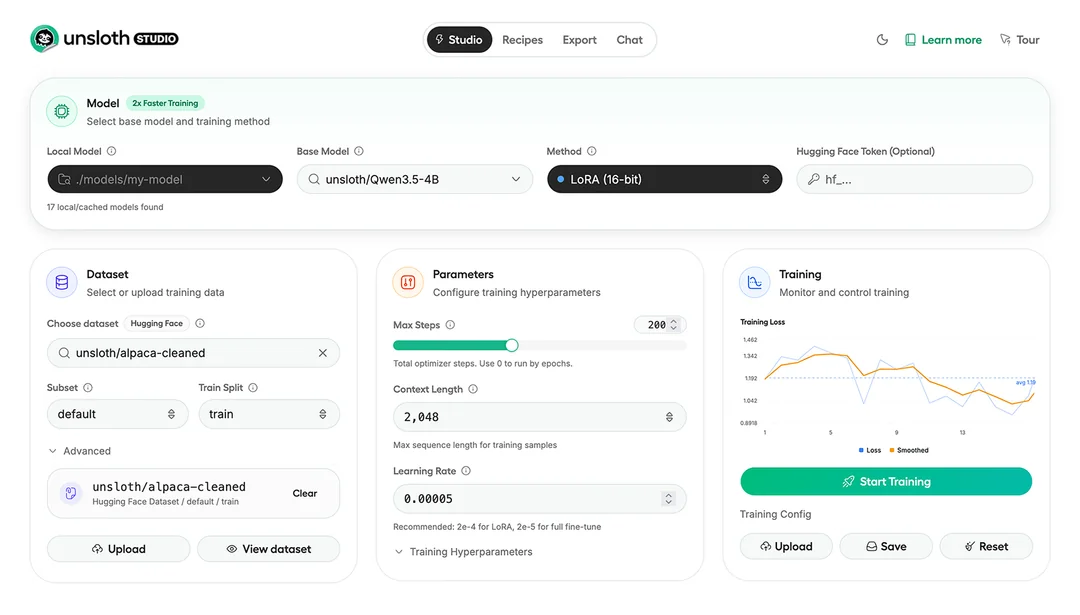
Architettura e componenti di Unsloth Studio
Unsloth Studio si presenta come una Web UI no-code progettata per operare sopra un backend locale che gestisce l’intero ciclo di vita del modello AI. L’interfaccia consente di orchestrare tre fasi principali: caricamento del modello base, addestramento o fine-tuning e successiva esportazione.
Il motore sottostante sfrutta ottimizzazioni matematiche proprietarie implementate direttamente nei kernel GPU. Invece di affidarsi esclusivamente a librerie standard, il framework introduce calcoli ottimizzati che riducono il numero di operazioni e migliorano la gestione della memoria, con un impatto diretto sui tempi di addestramento.
La compatibilità si estende a una vasta gamma di modelli open, tra cui Llama 1, 2 e 3, Gemma, Mistral e Qwen, con supporto sia per formati a 16 bit sia per varianti quantizzate a 4 bit. Questa flessibilità consente di adattare il carico computazionale al dispositivo disponibile, mantenendo un buon equilibrio tra accuratezza e consumo di risorse.
Scenari d’uso e limiti operativi
L’integrazione di training e inferenza in un’unica interfaccia apre a diversi scenari applicativi. È possibile costruire modelli specializzati per analisi legale, supporto clienti o classificazione semantica, utilizzando dataset proprietari senza dipendere da servizi cloud esterni. La possibilità di mantenere i dati in locale rappresenta un vantaggio significativo in termini di privacy e conformità.
Non mancano tuttavia alcune limitazioni tecniche. Le prestazioni reali dipendono fortemente dalla configurazione hardware, in particolare dalla disponibilità di VRAM e dalla velocità della memoria.
L’uso di una quantizzazione molto spinta, cioè la riduzione drastica della precisione numerica con cui il modello rappresenta i dati, può causare una perdita di qualità nelle risposte; allo stesso tempo, l’addestramento di modelli di grandi dimensioni continua a richiedere risorse hardware elevate.
Va considerata anche la maturità del progetto, attualmente in fase beta. Alcune funzionalità avanzate, come il supporto completo multi-GPU o l’inferenza ad alte prestazioni, risultano ancora in evoluzione.
Nonostante ciò, la direzione intrapresa evidenzia una chiara tendenza verso strumenti sempre più autonomi e completi per la gestione locale dei modelli linguistici.
Fine-tuning avanzato e tecniche di ottimizzazione
Uno degli elementi centrali di Unsloth Studio riguarda l’integrazione nativa di tecniche di fine-tuning avanzate (l’adattamento del modello a nuovi dati o compiti specifici).
Il sistema supporta approcci come Supervised Fine-Tuning, Reinforcement Learning e ottimizzazione tramite preferenze, consentendo di adattare il comportamento del modello a contesti specifici.
Un aspetto particolarmente rilevante è l’uso di LoRA e QLoRA, tecniche che consentono di modificare solo una piccola parte dei parametri (i “pesi”, cioè i valori numerici che determinano il comportamento del modello) tramite matrici a bassa dimensionalità, ovvero strutture matematiche più compatte che richiedono meno risorse. In pratica, questo metodo riduce in modo significativo il consumo di memoria, rendendo possibile il fine-tuning anche su sistemi dotati di pochi gigabyte di VRAM, la memoria dedicata della scheda grafica.
Il sistema consente inoltre di eseguire le attività di addestramento anche in ambienti limitati come Google Colab o Kaggle, con requisiti minimi che possono scendere fino a circa 3 GB di VRAM, rendendo possibile la sperimentazione anche senza infrastrutture dedicate.
Unsloth Studio non si limita alla fase di training. L’ambiente include strumenti per eseguire modelli localmente, sfruttando backend compatibili come llama.cpp. Il comportamento della piattaforma apre all’utilizzo di modelli quantizzati in formato GGUF e di eseguire inferenza anche su CPU o sistemi ibridi con offloading tra RAM e GPU.
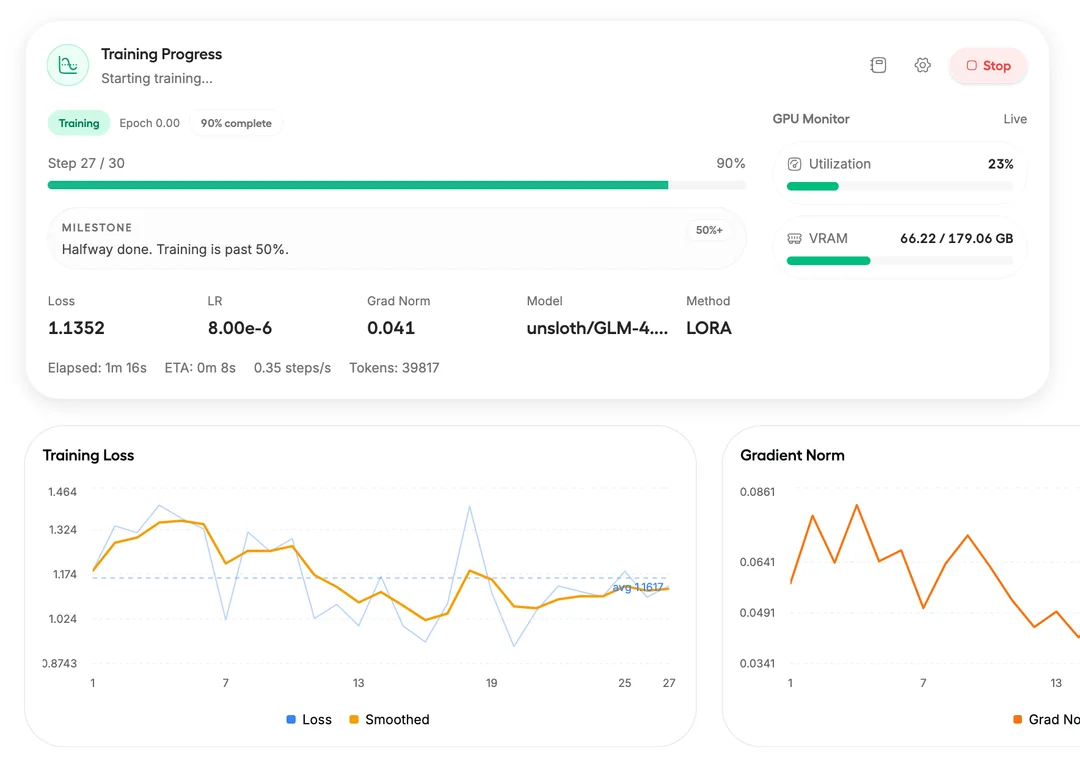
Come iniziare con Unsloth Studio in ambiente locale
Per iniziare con Unsloth Studio è sufficiente predisporre un ambiente Python aggiornato (consigliato Python 3.10 o superiore) e installare le dipendenze principali, tra cui PyTorch con supporto CUDA se si dispone di GPU NVIDIA compatibile.
Dopo aver clonato il repository ufficiale, l’avvio dell’interfaccia avviene tramite script locale che espone la Web UI su una porta dedicata, generalmente accessibile da browser all’indirizzo localhost.
La configurazione iniziale richiede il caricamento di un modello base compatibile – ad esempio varianti di Llama o Mistral – e la selezione del dataset per il fine-tuning, che può essere fornito in formato JSON o Hugging Face Dataset.
Parametri come la dimensione del batch (il numero di esempi elaborati insieme), il learning rate (la velocità con cui il modello aggiorna i propri pesi durante l’addestramento) e il numero di epoch (quante volte l’intero dataset viene processato) possono essere modificati direttamente dall’interfaccia Web. Inoltre, le impostazioni di quantizzazione consentono di ottimizzare l’uso della memoria in base alle risorse hardware effettivamente disponibili.
Per accedere alle istruzioni dettagliate, agli esempi di configurazione e ai dettagli sulle modalità di esecuzione, suggeriamo di fare riferimento al repository ufficiale disponibile su GitHub. Sono disponibili le istruzioni di installazione per MacOS, Linux, Windows (anche tramite WSL, Windows Subsystem for Linux).
Un passo verso l’autonomia operativa dei modelli AI
Unsloth Studio rappresenta un’evoluzione concreta nel modo in cui sviluppatori e team tecnici interagiscono con i modelli linguistici. L’unificazione delle operazioni riduce il numero di strumenti necessari e semplifica attività che tradizionalmente richiedevano competenze avanzate in machine learning e infrastrutture.
L’approccio locale, combinato con ottimizzazioni profonde a livello computazionale, consente di ridurre costi e dipendenze esterne.
Con l’espansione del supporto hardware e il miglioramento delle tecniche di quantizzazione, strumenti come Unsloth Studio potrebbero diventare una componente stabile nei flussi di lavoro legati allo sviluppo AI, soprattutto in contesti dove controllo dei dati e la flessibilità operativa risultano prioritari.
/https://www.ilsoftware.it/app/uploads/2026/03/wp_drafter_498250.jpg "Creator Fast Track: Meta punta sui creator per rilanciare Facebook")
/https://www.ilsoftware.it/app/uploads/2026/03/lobby-sistemi-verifica-eta-online.jpg "Meta e verifica età online: accuse di lobbying miliardario dietro la tecnologia")
/https://www.ilsoftware.it/app/uploads/2025/01/1-40.jpg "Meta: addio alla crittografia-end-to-end dei messaggi su Instagram")
/https://www.ilsoftware.it/app/uploads/2026/03/wp_drafter_497837.jpg "TikTok integra Apple Music: sarà possibile ascoltare in streaming brani completi")