/https://www.ilsoftware.it/app/uploads/2026/01/chip-microsoft-maia-200-AI.jpg "Maia 200, il chip AI di Microsoft che ridefinisce l’inferenza su larga scala: cosa significa")
Con l’annuncio del chip AI Maia 200, Microsoft compie un passo decisivo nel trasformare il proprio ruolo da semplice “consumatore” di acceleratori AI a progettista di silicio, capace di competere direttamente con Google, Amazon e – indirettamente – Nvidia sul terreno più critico dell’AI moderna: l’inferenza su larga scala. Non si tratta di un aggiornamento incrementale rispetto a Maia 100, che Redmond presentò già nel 2023, ma di un cambio di passo architetturale che riflette una visione chiara su dove si stia spostando il baricentro economico dell’intelligenza artificiale.
Negli ultimi anni, l’addestramento dei modelli ha monopolizzato l’attenzione, ma oggi è l’inferenza – la generazione dei token, la latenza, il costo per richiesta – a determinare la sostenibilità reale dei servizi AI. Maia 200 nasce esattamente per confrontarsi con questo scenario.
L’inferenza AI non è solo un problema computazionale: perché nasce Maia 200
Uno degli elementi più rilevanti di Maia 200 è il fatto che Microsoft non lo descrive semplicemente come un chip più potente, ma come un sistema di inferenza. La scelta di puntare su FP8 e FP4 nativi non è solo una questione di FLOPS teorici: è il riconoscimento che i modelli LLM moderni, una volta addestrati, possono essere serviti in modo estremamente efficiente se l’intera pipeline è progettata attorno a precisioni ridotte e a flussi di dati altamente prevedibili.
FP8 e FP4 sono formati numerici a bassa precisione che usano meno bit per i calcoli, permettendo maggiore velocità ed efficienza nell’esecuzione dei modelli.
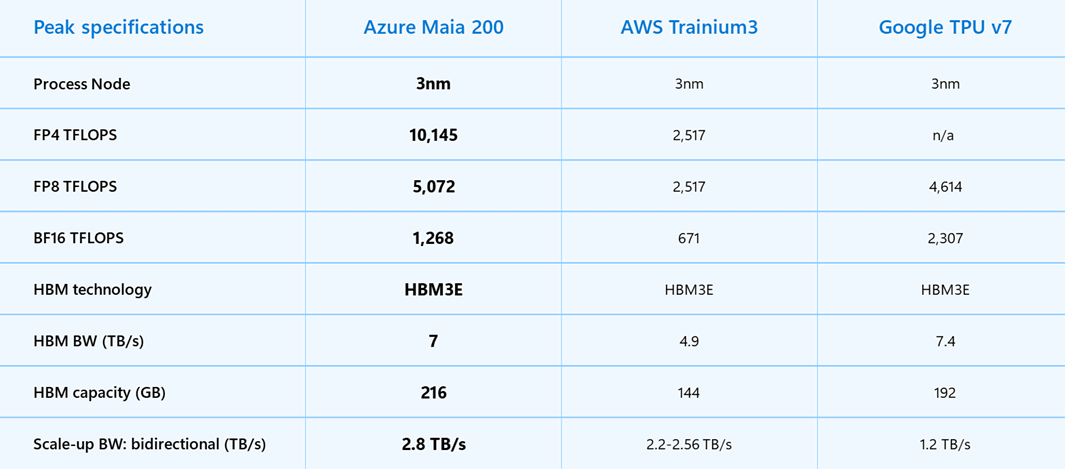
Con oltre 140 miliardi di transistor utilizzati nel nodo a 3 nm di TSMC, Maia 200 supera la soglia psicologica dei 100 miliardi e si colloca in una classe di complessità paragonabile ai più avanzati acceleratori proprietari del mercato. Tuttavia, la potenza di calcolo – oltre 10 petaFLOPS in FP4 e 5 petaFLOPS in FP8 – è solo una parte dell’equazione.
Microsoft ha attaccato frontalmente quello che, nell’inferenza basata su Large Language Models (LLM), è spesso il vero collo di bottiglia: il data feeding. La combinazione di 216 GB di memoria HBM3e a 7 TB/s, 272 MB di SRAM on-chip e motori DMA specializzati indica una progettazione che considera il movimento dei dati come un cittadino di prima classe, non come un effetto collaterale del calcolo.
Reti standard, ambizioni non standard
Una delle scelte più controcorrente di Maia 200 riguarda il networking. In un contesto in cui molti hyperscaler stanno adottando interconnessioni sempre più proprietarie, Microsoft ha optato per una rete di scale-up a due livelli basata su Ethernet standard, arricchita però da un trasporto custom e da schede di rete profondamente integrate.
L’architettura consente a ogni acceleratore di disporre di 2,8 TB/s di banda bidirezionale dedicata, mantenendo operazioni collettive prevedibili su cluster che possono arrivare fino a 6.144 acceleratori. Il risultato non è solo prestazionale, ma economico: riduzione dei costi di infrastruttura, minore consumo energetico e un TCO più controllabile su scala globale.
Microsoft sta cercando di evitare il lock-in tecnologico che oggi caratterizza molte soluzioni di interconnessione AI, puntando invece su un modello più aperto, scalabile e replicabile nei propri data center.
Redmond metterà a disposizione Maia 200 anche su Azure e già oggi ha condiviso la possibilità di iscriversi al programma di accesso al pacchetto di sviluppo (SDK).
GPT-5.2, Copilot e la centralità dell’inferenza “economica”
Il primo grande beneficiario di Maia 200 sarà Microsoft stessa. L’hosting di GPT-5.2, l’evoluzione dei servizi Copilot e l’infrastruttura Microsoft Foundry si baseranno su questo acceleratore, con una promessa esplicita: 30% di performance per dollaro in più rispetto all’hardware attualmente in uso.
Il dato va letto con attenzione. Non significa semplicemente spendere meno, ma rendere economicamente sostenibile l’uso massivo di modelli sempre più grandi, riducendo il costo di ogni token generato. È qui che Maia 200 si fa sentire: non solo abilita modelli più complessi, ma permette di portarli in produzione su scala globale senza che i costi esplodano.
Un aspetto meno evidente, ma estremamente rilevante, è l’uso che il team Microsoft Superintelligence farà di Maia 200 per la generazione di dati sintetici e per il reinforcement learning. L’acceleratore è pensato come elemento chiave di un circolo virtuoso in cui l’inferenza alimenta l’addestramento di nuova generazione.
La capacità di generare rapidamente dati di alta qualità, specifici per dominio e continuamente aggiornati, potrebbe diventare uno dei fattori differenzianti più importanti nello sviluppo dei modelli futuri, soprattutto in un contesto di scarsità di dati reali utilizzabili.
Le immagini pubblicate nell’articolo sono di Microsoft
/https://www.ilsoftware.it/app/uploads/2026/03/vulnerabilita-copilot-excel-sottrazione-dati-riservati.jpg "Bug in Excel trasforma Copilot in un rischio zero click per i dati aziendali")
/https://www.ilsoftware.it/app/uploads/2026/03/gemini-AI-google-workspace.jpg "Gemini entra più a fondo in Workspace: come cambia il modo di scrivere documenti")
/https://www.ilsoftware.it/app/uploads/2026/03/perplexity-personal-computer.jpg "Perplexity prepara il suo Personal Computer: cosa vuole cambiare")
/https://www.ilsoftware.it/app/uploads/2026/03/wp_drafter_497841.jpg "AI e salute: le diagnosi dei chatbot esatte solo nel 34% dei casi")