/https://www.ilsoftware.it/app/uploads/2025/11/meta-sam3-segmentazione-video-immagini.jpg "Meta SAM3 è la prima AI che esegue la segmentazione precisa su immagini e video: lascia a bocca aperta")
La segmentazione delle immagini rappresenta una delle operazioni fondamentali della computer vision: consiste nel suddividere un’immagine o un video in regioni significative, isolando oggetti, persone, superfici o parti specifiche della scena. È il passaggio che permette a un sistema di “capire” non solo cosa appare in un frame, ma dove si trova ogni elemento e quali pixel gli appartengono. Senza segmentazione non potrebbero esistere applicazioni come l’editing selettivo nelle piattaforme creative, la guida autonoma, l’analisi medica automatizzata, il monitoraggio ambientale o l’annotazione di grandi dataset visuali utilizzati per addestrare AI sempre più avanzate.
Con Segment Anything Model 3 (SAM 3), Meta introduce una piattaforma di segmentazione realmente unificata, progettata per operare con un livello di generalizzazione senza precedenti e per supportare applicazioni reali.
Qualche cenno storico sulla segmentazione di immagini e video
Storicamente, la segmentazione è nata in modo rudimentale: algoritmi basati su soglie di colore, bordi o differenze di luminosità permettevano di separare solo gli oggetti più evidenti.
Successivamente si è passati a tecniche basate su clustering, metodi statistici, grafi e modelli probabilistici, in grado di gestire contesti più complessi, ma ancora lontani dalla flessibilità richiesta nel mondo reale. Con l’arrivo del deep learning e delle reti convoluzionali, la segmentazione è diventata molto più precisa, ma sempre legata a set di categorie predefinite. Ogni modello poteva segmentare solo gli oggetti per cui era stato addestrato.
Il vero limite dei sistemi tradizionali era, infatti, la mancanza di generalizzazione: aggiungere nuove classi richiedeva nuovi dataset, nuove annotazioni e un nuovo addestramento. Inoltre, immagini e video erano trattati separatamente: l’interazione dell’utente era minima.
I modelli della serie Meta Segment Anything hanno iniziato a superare questi confini, presentandosi come strumenti in grado di segmentare qualsiasi oggetto, anche senza una categoria nota, tramite semplici clic o regioni selezionate. Con SAM 3, questa evoluzione compie un salto ulteriore: la segmentazione diventa realmente “promptable”, unificata e open-vocabulary, aprendo la strada a un sistema capace di comprendere richieste in linguaggio naturale, esempi visivi e input interattivi con una precisione che si avvicina sempre di più al comportamento umano.
SAM3: un modello davvero “promptable” con testi, esempi, click e tracking
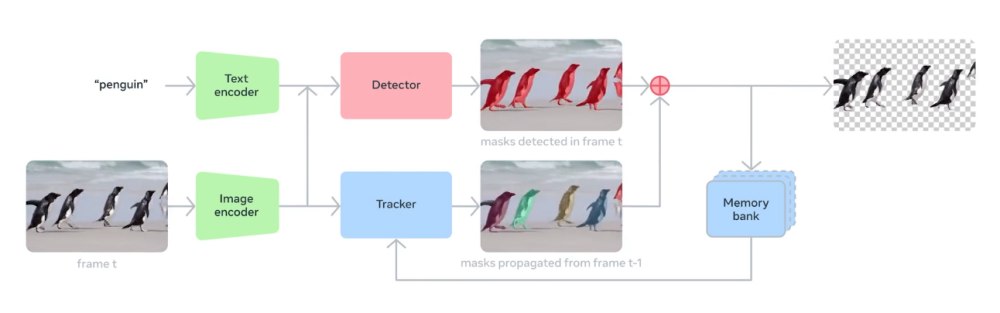
Il nuovo SAM 3 non rappresenta soltanto un’evoluzione incrementale rispetto a SAM 1 e SAM 2: è l’ingresso in una nuova generazione di modelli in cui il testo, le annotazioni visive e l’interazione umana convergono per produrre maschere estremamente accurate su qualunque oggetto, nelle immagini e nelle sequenze video.

L’innovazione principale di SAM 3 è la capacità di rispondere a prompt multimodali. Ad esempio, è possibile istruire il modello usando descrizioni naturali come:
- “tutti i giocatori in maglia rossa”
- “le automobili parcheggiate”
- “le bottiglie di vetro”
A differenza delle soluzioni precedenti, SAM 3 comprende categorie open-vocabulary: significa che il modello non è più limitato a un insieme di classi predefinite.
Prompt attraverso esempi, prompt visivi e interazione iterativa
Con SAM3, è sufficiente disegnare un riquadro attorno a un oggetto: il modello individua automaticamente tutte le istanze simili, replicando un comportamento molto vicino a quello umano.
Il nuovo modello Meta, inoltre, permette di includere delle aree dell’immagine o del video oppure, viceversa, di escluderle. Infine, ogni previsione può essere raffinata, con un processo interattivo utile per applicazioni creative, editor video, annotazione dati e sviluppo di sistemi evoluti di computer vision.
Come provare SAM3 e il framework per sviluppatori e ricercatori
Per provare SAM3, è sufficiente aprire il playground Meta e cliccare sul pulsante Try it. L’applicazione basata su SAM3 permette di caricare contenuti multimediali dal proprio dispositivo o cominciare con le risorse di esempio fornite dall’azienda di Mark Zuckerberg.
Basta cliccare sui riquadri per la creazione di Cutouts e SAM3 vi meraviglierà di tutto ciò che è capace di fare creando automaticamente maschere e offrendo gli strumenti per applicare effetti di ogni genere.
Il bello è che SAM3 è un progetto aperto: il sorgente è disponibile sul repository GitHub e può essere utilizzato da sviluppatori e professionisti. Purtroppo non abbiamo a che fare con un software libero bensì con un oggetto distribuito sotto una licenza “ad hoc”.
I passaggi per l’installazione prevedono l’uso di Python 3.12+, PyTorch 2.7+ con CUDA 12.6, un sistema equipaggiato con una GPU NVIDIA compatibile nonché accesso ai checkpoint via Hugging Face. Sono disponibili componenti per segmentazione su immagini, segmentazione e tracking su video, prompt testuali, visuali e combinati, batch inference, integrazione con agenti multimodali.
/https://www.ilsoftware.it/app/uploads/2026/02/amazonmusic.jpg "Accesso completo a 100 milioni di brani: Amazon Music Unlimited con prova gratuita di 1 mese")
/https://www.ilsoftware.it/app/uploads/2026/02/sostanze-chimiche-tossiche-cuffie-auricolari-2026.jpg "Cuffie e sostanze chimiche: cosa emerge dai test e come scegliere con più criterio")
/https://www.ilsoftware.it/app/uploads/2026/02/ban-PC-asus-acer-germania-HEVC.jpg "HEVC, stop a PC Acer e ASUS in Germania: cosa cambia e perché investire sull'open source")
/https://www.ilsoftware.it/app/uploads/2026/02/frigate-NVR-videosorveglianza-AI.jpg "Frigate porta la videosorveglianza locale AI a un nuovo livello")