/https://www.ilsoftware.it/app/uploads/2024/02/mobilediffusion-generazione-immagini-smartphone.jpg "MobileDiffusion, Google ha il suo modello per generare immagini... dallo smartphone")
Il nuovo campo da gioco sul quale si stanno confrontando le principali realtà che si occupano di modelli generativi e, in generale, di soluzioni basate sull’intelligenza artificiale, ha a che fare con l’ottimizzazione delle prestazioni. Basti pensare a SDXL Turbo, presentato a novembre 2023 da Stability AI, e al nuovo modello PixArt-δ messo a punto da un team di ricercatori accademici in collaborazione con Huawei (gennaio 2024). Google ha deciso di rispondere colpo su colpo presentando MobileDiffusion.
Cos’è MobileDiffusion e come funziona
La generazione rapida di immagini a partire da testi descrittivi (prompt) in linguaggio naturale rappresenta una vera e propria sfida, soprattutto sui dispositivi mobili, per via delle più limitate risorse computazionali delle quali possono beneficiare questi device. Per questo motivo, di solito, le elaborazioni legate alle applicazioni di intelligenza artificiale sono demandate all’infrastruttura disponibile sul cloud.
Gli smartphone, tuttavia, stanno evolvendo rapidamente in termini di potenza grezza ed è sempre più comune l’integrazione di un chip NPU (Neural Processing Unit), un’unità progettata specificamente per eseguire operazioni legate all’intelligenza artificiale e al machine learning. L’architettura della NPU è ottimizzata per le operazioni matematiche coinvolte nei calcoli correlati con l’addestramento e l’utilizzo di reti neurali artificiali.
I tecnici Google presentano MobileDiffusion come un efficiente modello di diffusione latente, progettato appositamente per dispositivi mobili. Utilizza DiffusionGAN per eseguire un campionamento in un solo passaggio durante la fase di inferenza, sfruttando un modello di diffusione preaddestrato insieme a una rete GAN per modellare la fase di denoising. Troppi concetti tutti insieme? Cerchiamo di tradurre il tutto in un linguaggio più comprensibile.

In figura, alcuni esempi di immagini create ricorrendo al nuovo modello Google MobileDiffusion.
Il modello di diffusione latente
Il “latent diffusion model” (LDM) è un modello di apprendimento automatico profondo utilizzato per generare immagini dettagliate. È una variante del modello di diffusione (DM) e si basa sull’addestramento per rimuovere il rumore dalle immagini in modo progressivo. In pratica, il modello prende in carico un’immagine e aggiunge rumore in passi successivi, per poi rimuoverlo gradualmente, ottenendo un’immagine più pulita.
Il termine “latente” si riferisce allo spazio latente (ne abbiamo parlato in altri nostri articoli), che è una rappresentazione compressa dei dati. Questo approccio consente di generare immagini dettagliate e di alta qualità utilizzando l’intelligenza artificiale generativa.
Cosa significa DiffusionGAN
Si chiama DiffusionGAN il modello di apprendimento automatico che unisce due schemi già noti in precedenza: Generative Adversarial Networks (GAN) e modelli di diffusione. Le GAN sono note per generare nuovi dati, come immagini.
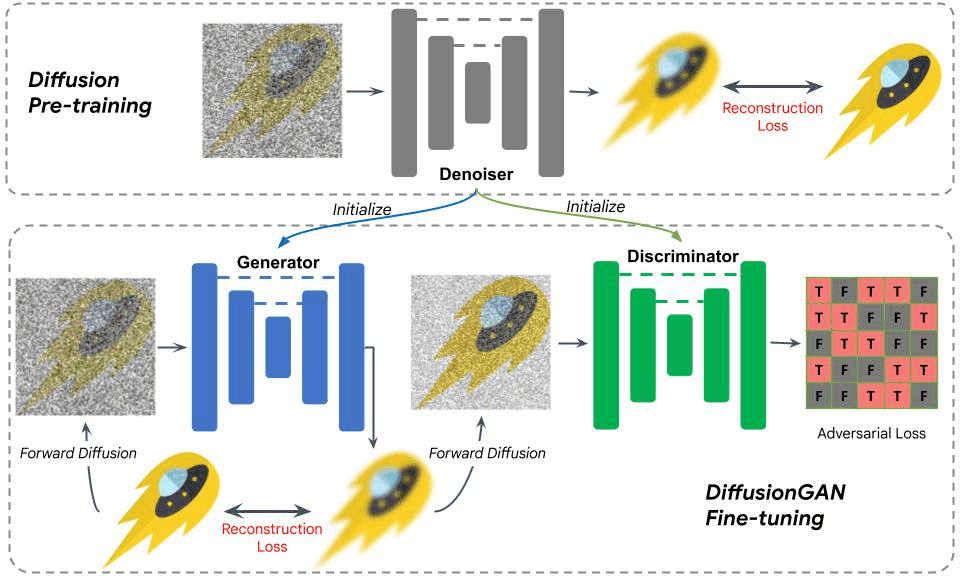
Schema di funzionamento dell’ottimizzazione con DiffusionGAN.
L’obiettivo è quello di combinare queste due tecniche per generare immagini di alta qualità in modo efficiente e con una buona copertura dei dati. Questa combinazione offre il potenziale per migliorare la qualità e la diversità delle immagini via via generate.
I vantaggi di Google MobileDiffusion
Ricorrendo al nuovo MobileDiffusion, spiega Google, è possibile generare immagini di elevata qualità (risoluzione 512 x 512 pixel) in soli 0,5 secondi sui dispositivi premium (leggasi gli smartphone di fascia più alta dotati di NPU…).
MobileDiffusion ha quindi il vantaggio di essere ultraperformante sui dispositivi mobili grazie all’uso di tre componenti: un codificatore di testo, un UNet di diffusione e un decoder di immagini.
Il codificatore utilizzato per il testo ha il compito di convertire il prompt in una rappresentazione numerica comprensibile per il modello. Nel caso specifico di MobileDiffusion, Google sfrutta un modello chiamato CLIP-ViT/L14 come encoder. È progettato per essere leggero e adatto ai dispositivi mobili, poggiando solamente su 125 milioni di parametri.
UNet è un’architettura di rete neurale utilizzata comunemente per la generazione di immagini. Nel contesto di MobileDiffusion, l’UNet di diffusione svolge un ruolo importante nella generazione delle immagini a partire dalla rappresentazione numerica del testo ottenuta dal codificatore.
Infine, il decoder si occupa di tradurre la rappresentazione numerica ottenuta dall’UNet di diffusione in un’immagine finale. È responsabile della trasformazione della rappresentazione numerica in una forma visualmente comprensibile.
MobileDiffusion presto in arrivo su Android e iOS
Purtroppo, almeno per adesso, MobileDiffusion resta un progetto di ricerca portato avanti da quattro ricercatori Google. L’azienda, tuttavia, non soltanto ha celebrato l’importante pietra miliare posta da MobileDiffusion con un post sul blog ufficiale, ma ha anche messo a confronto le prestazioni del modello con quelle dei principali “concorrenti”.
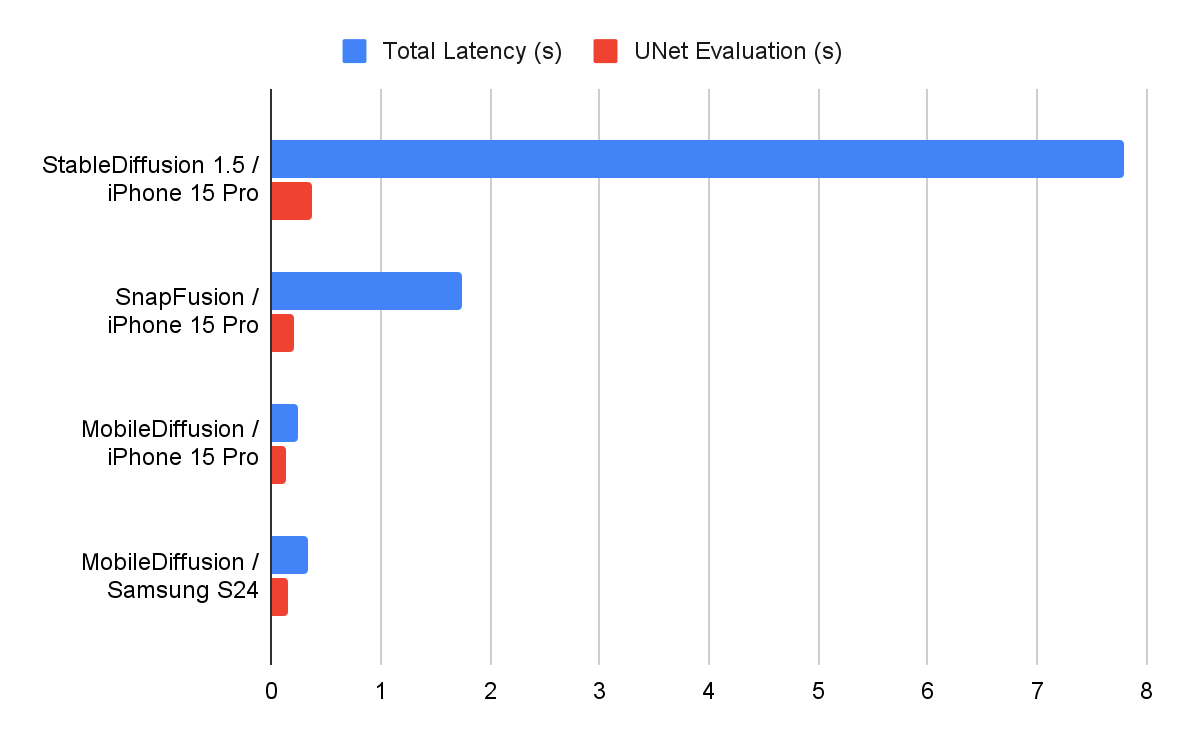
Interessante la comparativa tra MobileDiffusion utilizzato su smartphone Samsung Galaxy S24 e iPhone 15 Pro con le performance registrate da StableDiffusion e SnapFusion sul top di gamma Apple.
In conclusione, Google lascia intendere che MobileDiffusion sarà protagonista delle soluzioni destinate ai dispositivi mobili proposte dall’azienda di Mountain View e incentrate sull’intelligenza artificiale. È infatti una soluzione “amichevole” per coloro che utilizzano i moderni smartphone. Sarà inoltre dispiegata ponendo la massima attenzione sul rispetto degli aspetti etici e delle responsabilità in capo alle soluzioni IA di Google.
Generazione delle immagini as-you-type
Inutile dire che la decisa spinta sull’acceleratore delle performance, permetterà di realizzare app in grado di generare una serie di immagini in tempo reale. Una possibilità che apre le porte all’applicazione di modifiche arbitrarie su immagini preesistenti o su risorse prodotte dallo stesso modello generativo.
Si prenda l’esempio di applicazione presentato da Google: come si vede, l’utente chiede a MobileDiffusion di generare l’immagine di un’autovettura. Semplicemente modificando il prompt, si può cambiare lo scenario, lo sfondo, i colori, lo stile dell’immagine e qualunque altra caratteristica. Con la possibilità di accedere istantaneamente al risultato visivo.

Nell’esempio che segue, si parte dalla classica immagine di un gatto per far indossare poi al felino una tuta da astronauta, posizionarlo in una navicella spaziale e, infine, aggiungere alcune descrizioni più articolate che vanno a incidere direttamente sul contesto.
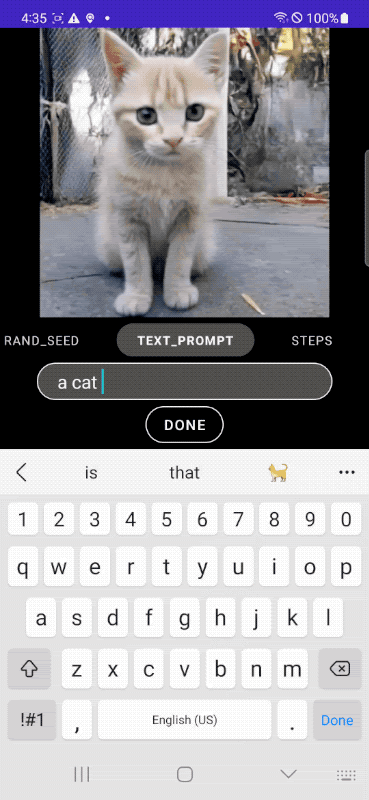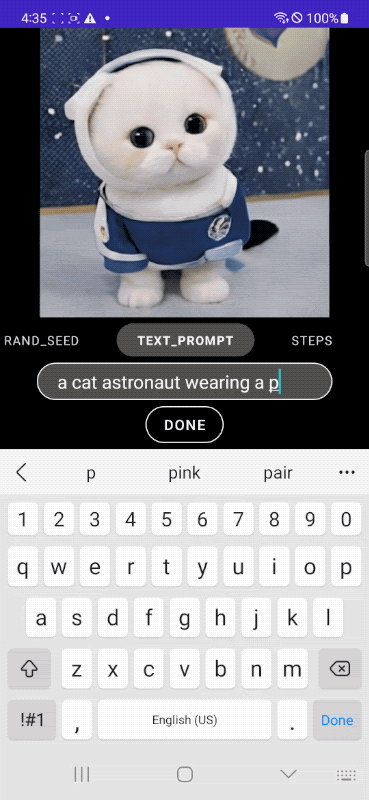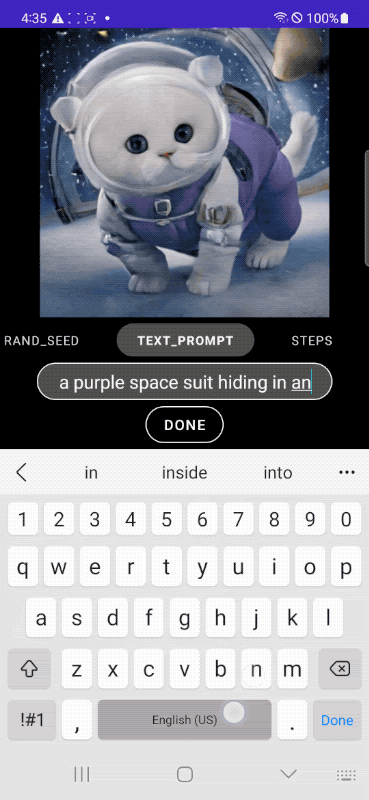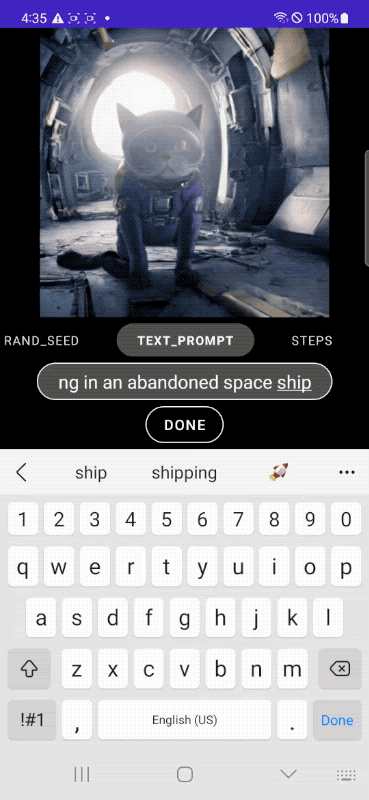
Le immagini pubblicate nell’articolo sono di Google e sono tratte dal post “MobileDiffusion: Rapid text-to-image generation on-device“.
Credit immagine in apertura: iStock.com – da-kuk
/https://www.ilsoftware.it/app/uploads/2024/11/openai-operator-agent-interagisce-PC.jpg "OpenAI aggiorna GPT-Live: come cambia la modalità vocale di ChatGPT")
/https://www.ilsoftware.it/app/uploads/2024/02/phind-motore-ricerca-intelligenza-artificiale-browser.jpg "Rowboat, l'AI alternativa a Claude Desktop che memorizza email e riunioni")
/https://www.ilsoftware.it/app/uploads/2024/08/AI-Intelligenza-artificiale.png "Meta ha rilasciato Muse Image, modello AI per creare animazioni GIF")
/https://www.ilsoftware.it/app/uploads/2024/05/plugin-openvino-intelligenza-artificiale-generativa-GIMP.jpg "LongCat-2.0 sfida NVIDIA: il maxi modello AI cinese può rivoluzionare il settore?")