/https://www.ilsoftware.it/app/uploads/2023/05/img_10248.jpg "Convertire un PDF in un PDF ricercabile con l'OCR")
Vi sarà capitato più volte di non riuscire a copiare del testo dai file PDF. Nella maggior parte dei casi ciò non è dovuto all’attivazione, da parte dell’autore del documento, del meccanismo che impedisce operazioni di “copia e incolla”.
Per verificare che non sia stata apposta tale protezione, è sufficiente – da Adobe Reader – aprire il file PDF d’interesse quindi scegliere la voce Proprietà dal menù File. Nella scheda protezione, bisognerà verificare l’indicazione posta accanto a Copia contenuto.
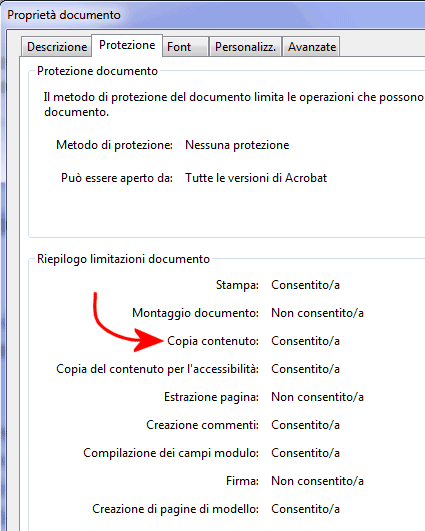
Se la copia del contenuto del PDF risulta consentita, è altamente probabile che si sia di fronte ad un documento PDF composto da una serie di immagini di pagine cartacee acquisite da scanner.
Come fare per convertire un PDF in un PDF ricercabile? Com’è possibile, cioé, fare in modo che si possa utilizzare la funzionalità Modifica, Trova per individuare rapidamente una parola od una frase nel documento?
Per rendere un PDF ricercabile, si dovrà sottoporre il documento ad una scansione ottica dei caratteri ed al loro riconoscimento automatico (OCR).
Il modo migliore per sottoporre ad OCR un PDF e permettere la ricerca di informazioni al suo interno, consiste nell’utilizzare il software Adobe Acrobat che integra una pratica funzionalità per trasformare un PDF in un PDF ricercabile.
Gli utenti di Acrobat possono applicare le semplici istruzioni pubblicate anche dalla stessa Adobe:
Chi non fosse in possesso di una regolare licenza di Adobe Acrobat può risolvere utilizzando uno strumento alternativo? La risposta è affermativa. Gli utenti di Windows troveranno in PDF-XChange Viewer una soluzione più che eccellente.
Sottoporre ad OCR i documenti PDF e trasformarli in PDF “ricercabili” con PDF-XChange Viewer
Tornando in ambiente Windows, come ulteriore alternativa, è possibile utilizzare PDF-XChange Viewer, un’applicazione che integra uno strumento OCR attivabile su qualunque tipo di file PDF. Il software è “proprietario” ed utilizza un motore OCR non disponibile in Rete ma è comuque abilissimo nel trasformare i file PDF in PDF ricercabili.
Anzi, il file PDF che si ottiene dopo l’elaborazione con PDF-XChange non è per nulla “pesante”.
Per provare subito PDF-XChange Viewer è sufficiente cliccare qui procedendo poi con l’installazione del programma.
In fase di setup, si potrebbe essere interessati a disattivare l’aggiornamento automatico e gli addin per i vari browser web:
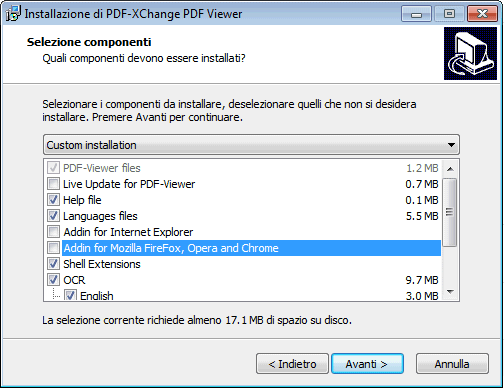
Suggeriamo di disattivare la casella Set PDF-XChange Viewer as default viewer for PDF files.
Ad installazione ultimata (ci si accerti di optare per la versione Free, completamente gratuita per usi in ambienti domestici e commerciali), bisognerà prelevare l’European language pack che include anche la lingua italiana (download).
L’installazione dei file per il riconoscimento di tasti redatti in lingua italiana si concretizza semplicemente facendo doppio clic sul file eseguibile contenuto all’interno dell’archivio OCRAdditionalLangsEU.zip.
PDF-XChange è un software che può diventare un’applicazione “portabile”: dopo aver installato il programma e caricato i file per il riconoscimento ottico dei caratteri in italiano (OCR), basterà portare con sé e copiare altrove il contenuto della cartella d’installazione (tipicamente, %program files%\Tracker Software\PDF Viewer).
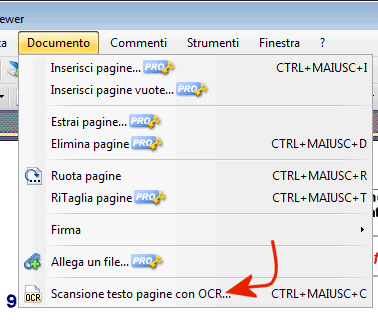
Dopo aver avviato PDF-XChange, si dovrà cliccare sul menù File, Apri per individuare il documento PDF da convertire quindi selezionare Scansione testo pagine con OCR dal menù Documento:
Dalla finestra seguente, bisognerà selezionare Italian nel caso di testi in italiano (Linguaggio principale) ed eventualmente scegliere l’accuratezza Alta per ottenere risultati migliori.
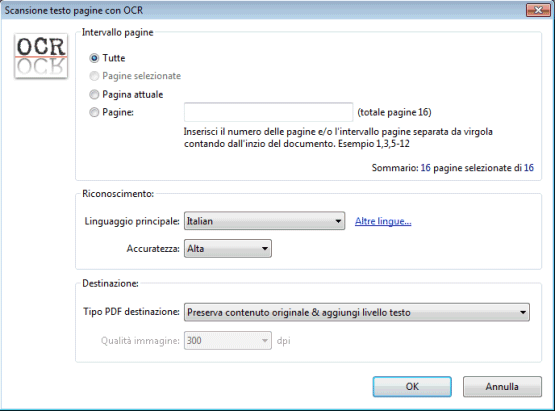
Non appena PDF-XChange teminerà l’operazione di riconoscimento dei caratteri (OCR), bisognerà fare clic sul menù File, Salva con nome e memorizzare il file PDF con un nome diverso da quello originale.
Aprendo il PDF elaborato con PDF-XChange con Adobe Reader o qualunque altro gestore di file PDF, ci si accorgerà immediatamente che il testo sarà interamente selezionabile, si potranno effettuare operazioni di “copia e incolla” e si potranno effettuare ricerche per qualunque termine o frase contenuti nel PDF.
Adobe Reader non trova alcuna parola nel documento convertito con PDF-XChange Viewer
Se si prova ad effettuare un “copia e incolla” a partire da un documento convertito con PDF-XChange e sottoposto ad OCR utilizzando Adobe Reader ci si accorgerà che tutto funziona perfettamente.
Qualora Adobe Reader sembrasse però non consentire le ricerche di termini presenti nei documenti convertiti con PDF-XChange, e visualizzasse il messaggio Reader ha completato la ricerca all’interno del documento. Non è stata trovata alcuna corrispondenza, si potrà risolvere aprendo la cartella C:\Users\NOMEUTENTE\AppData\LocalLow\Adobe\Acrobat\11.0\Search quindi cancellando integralmente tutto il suo contenuto (possono essere presenti numerosi file con estensione .idx).
Il problema deriva del fatto che Adobe Reader, di default, indicizza i file PDF più utilizzati e memorizza una sorta di database nella cartella sopra citata. Se un file convertito con PDF-XChange, ha ID identico al documento PDF “di partenza”, è probabile che il programma venga tratto in inganno.
Cancellando il contenuto della cartella Search la funzionalità “Trova” di Adobe Reader (menù Modifica, Trova o CTRL+F) tornerà a funzionare perfettamente.
Download: ilsoftware.it
Compatibile con: Windows XP, Windows Vista, Windows 7 (32 e 64 bit)
Dopo aver installato il programma è indispensabile caricare questo pacchetto. È indispensabile per l’OCR dei testi in italiano.
Licenza: Freeware (consentiti sia usi personali che commerciali)
Tesseract OCR, Google e Google Drive
Dopo aver fatto rinascere, nel 2006, il progetto Tesseract OCR (Google fa rinascere Tesseract OCR), Google lo integrò via a via sui suoi servizi online (leggasi Drive; Google Docs: le migliorie applicate alla funzionalità OCR e Google Drive su Android: scansione di documenti e OCR).
Il problema è che, secondo noi, lo strumento OCR offerto gratuitamente da Google non è ancora abbastanza maturo. Inoltre, seppur venga permesso l’upload di documenti PDF su Google Drive, spuntando la casella Converti testo da file PDF o file di immagine al formato di Google Documenti, ogni pagina del documento originale viene intervallata con una nuova pagina contenente il testo riconosciuto che, tra l’altro, non ricalca neppure la formattazione generale.
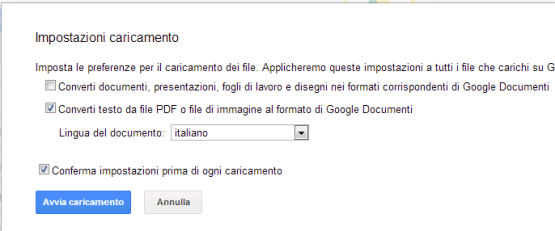
Al momento della stesura del presente articolo, quindi, Google Drive non permette di trasformare un PDF in un PDF ricercabile effettuando un riconoscimento dei caratteri ed inserendo un nuovo livello nel documento di origine.
Riconoscimento dei caratteri basato su Linux
In passato avevamo presentato WatchOCR, uno strumento – proposto come una vera e propria distribuzione Linux – che consente di allestire un server capace di ricevere in ingresso i documenti PDF da sottoporre ad OCR e di produrre automaticamente i corrispondenti file PDF “ricercabili”.
Vi invitiamo a leggere il nostro articolo Rendere ricercabile un PDF con WatchOCR. Come elaborare decine di documenti simultaneamente per sapere tutto sul funzionamento di WatchOCR.
Il problema di WatchOCR è che si tratta di una soluzione che sfrutta una vecchia versione del motore OCR Tesseract. Tale strumento, purtroppo, non si adatta benissimo ai testi in lingua italiana.
Appena possibile cercheremo un modo per rendere possibile l’utilizzo di WatchOCR con la più recente release di Tesseract OCR.
Intanto, abbiamo voluto provare un meccanismo che sfrutta, in ambiente Linux, Tesseract OCR insieme con alcuni programmi avviabili da riga di comando.
Ci siamo imbattuti in pdfocr, uno script sviluppato dal programmatore Geza Kovacs (presentato in questa discussione) che si prefigge come obiettivo proprio quello di trasformare un PDF in un PDF ricercabile.
Abbiamo provato lo script (che poggia sul linguaggio di scripting Ruby) sulla distribuzione Linux Mint.
Aprendo la finestra del terminale e digitando i comandi seguenti, si potrà installare sul sistema Linux tutto il necessario per il corretto funzionamento dello script:
sudo add-apt-repository ppa:gezakovacs/pdfocr
sudo apt-get update
sudo apt-get install pdfocr
Lo script pdfocr dovrebbe essere automaticamente installato nella directory /usr/bin/. Per verificarlo, basta impartire – dalla riga di comando – l’istruzione che segue:
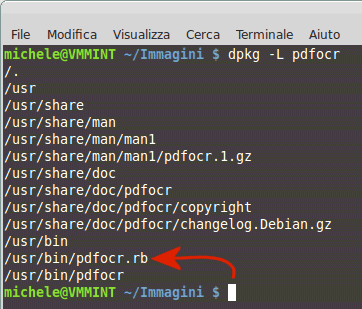
A questo punto, si digiti quanto segue:
sudo mv /usr/bin/pdfocr.rb /usr/bin/pdfocr.ori
sudo wget http://www.techportal.it/dl/pdfocr.txt
sudo mv ./pdfocr.txt /usr/bin/pdfocr.rb
sudo chmod +x /usr/bin/pdfocr.rb
I comandi appena presentati consentono di sostituire lo script Ruby originale con uno da noi modificato a partire dal codice di Geza Kovacs. Durante i nostri test abbiamo notato che lo script di Kovacs, pur funzionando in maniera impeccabile, evidenziava la stringa scorretta non appena si provava ad effettuare una ricerca sul PDF già elaborato dallo script. In altre parole, le frasi cercate non venivano mostrate nelle posizioni corrette.
Abbiamo quindi provato ad intervenire utilizzando un espediente che sembra condurre a risultati migliori.
Per trasformare un PDF in un PDF ricercabile basterà copiare, sul file system Linux, il documento da elaborare, portarsi nella cartella ove questo è stato memorizzato e digitare:
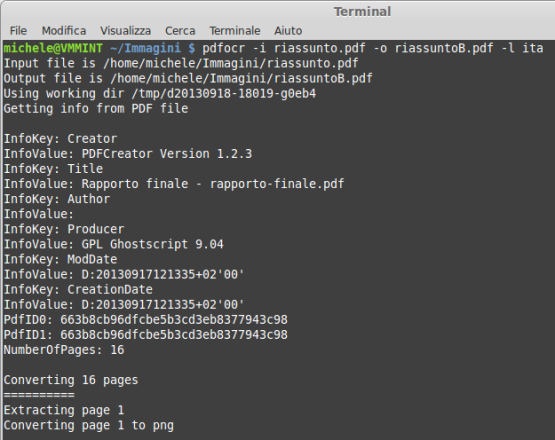
Di default pdfocr utilizza il motore Tesseract OCR.
Aggiungendo lo switch -c o -p è comunque possibile provare ad effettuare il riconoscimento dei caratteri utilizzando, rispettivamente, i motori Cuneiform e Ocropus.
Qualora uno o più pacchetti non fossero installati, si potranno digitare, sempre dalla finestra del terminale, i seguenti comandi:
sudo apt-get install tesseract-ocr-ita
sudo apt-get install tesseract-ocr
sudo apt-get install cuneiform
Il meccanismo basato su pdfocr è ben lungi dall’essere perfetto: esso offre comunque la possibilità di convertire un PDF in un PDF ricercabile in modo tale da individuare rapidamente le informazioni cercate all’interno del documento.
Per effettuare delle prove, suggeriamo di installare Linux Mint od un’altra distribuzione derivata da Ubuntu in una macchina virtuale (creata ad esempio con Virtualbox). Per copiare i file PDF da e verso un sistema Windows, basterà seguire le indicazioni pubblicate nell’articolo Accedere alle partizioni Linux da Windows: condivisione delle cartelle e file system.
/https://www.ilsoftware.it/app/uploads/2025/06/fedora-supporto-i686.jpg "Dietrofront su Linux: Fedora prosegue con il supporto per le CPU i686 a 32 bit")
/https://www.ilsoftware.it/app/uploads/2025/06/smartphone-linux-android.jpg "Sapevate che l'80% degli smartphone usa Linux?")
/https://www.ilsoftware.it/app/uploads/2025/06/successo-canonical-ubuntu-open-source.jpg "Ubuntu fa il botto: Canonical supera i 290 milioni di dollari e prepara il futuro dell’open source")
/https://www.ilsoftware.it/app/uploads/2025/06/cena-bill-gates-linus-torvalds.jpg "Bill Gates e Linus Torvalds insieme per la prima volta: momento storico per Windows e Linux")