/https://www.ilsoftware.it/app/uploads/2023/05/img_9261.jpg "Rendere ricercabile un PDF con WatchOCR. Come elaborare decine di documenti simultaneamente")
Un documento acquisito con lo scanner non può essere oggetto di ricerche all’interno del suo contenuto. Lo scanner, infatti, è una periferica in grado di acquisire foto e documenti sotto forma di immagini digitali. I testi, a meno che il driver dello scanner o gli altri componenti della suite di acquisizione delle immagini non lo permettano, non vengono sottoposti al riconoscimento ottico (OCR).
In gran parte delle situazioni, quindi, quando si acquisce un documento con lo scanner si ottiene un’immagine oppure un documento PDF contenente le immagini scannerizzate.
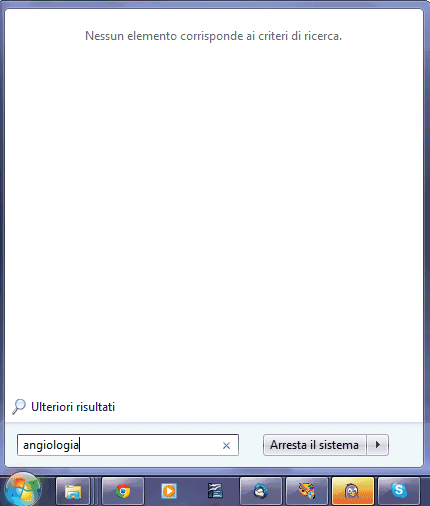
Se si prova ad effettuare una ricerca specificando una o più parole contenute nell’immagine scannerizzata, Adobe Reader, Foxit Reader o qualunque altro software si utilizzi per aprire i documenti in formato PDF, non indicheranno la presenza di alcuna occorrenza.
Si supponga di memorizzare il file PDF contenente le immagini dei documenti scannerizzati in una delle cartelle “monitorate” dalla funzionalità di ricerca integrata in Windows. Digitando uno o più termini presenti nel file PDF all’interno della casella Cerca programmi e file di Windows, anche in questo caso si otterrà il messaggio Nessun elemento corrisponde ai critieri di ricerca.
Per sapere tutto sulla funzionalità di ricerca di Windows 7 vi suggeriamo di consultare l’articolo Cercare file e cartelle: funzionalità di Windows e software alternativi.
Qualora non riusciste ad effettuare ricerche per ciò che riguarda il contenuto dei file in formato PDF, vi suggeriamo di fare riferimento al medesimo articolo. Il problema è infatti molto comune, soprattutto sui sistemi a 64 bit ma è facilmente risolvibile.
C’è un interessantissimo software, WatchOCR, che consente di rendere un PDF ricercabile.
Cosa intendiamo con quest’espressione? Dopo il “trattamento” con WatchOCR, sarà possibile effettuare ricerche in qualunque PDF acquisito da scanner come immagine ed ottenere un documento, tra l’altro, di dimensioni più contenute.
Rendendo un PDF ricercabile, non sarà possibile effettuare ricerche rapide all’interno del suo contenuto utilizzando programmi come Adobe Reader o Foxit Reader, ma anche Windows diverrà automaticamente in grado di indicizzarne il contenuto.
La maggior parte dei software che permettono di rendere ricercabile un PDF sono a pagamento o vengono distribuiti con un set di funzionalità limitato. WatchOCR, viceversa, può essere installato ed utilizzato (viene distribuito sotto licenza GNU GPL) senza alcuna restrizione e senza porre mano al portafogli (gli autori chiedono solamente di effettuare un versamento, qualora lo si volesse, per contribuire allo sviluppo dell’applicazione).
WatchOCR viene distribuito sotto forma di file ISO, prelevabile gratuitamente cliccando qui. Il file ISO può essere masterizzato su supporto CD, inserito in una chiavetta USB avviabile oppure, ancora, avviato da una macchina virtuale (ad esempio con VirtualBox).
Basato sulla distribuzione Linux Knoppix, WatchOCR include software quali ExactImage e Cuneiform per elaborare automaticamente le immagini contenute nei file PDF e per sottoporle al riconoscimento ottico dei caratteri (OCR).
L’utente non dovrà cimentarsi né con la configurazione di ExactImage né con quella di Cuneiform: WatchOCR è immediatamente operativo.
WatchOCR si propone anzi come una sorta di “piattaforma server” che provvede ad elaborare e rendere ricercabili i PDF non appena questi vengono ad essa sottoposti.
La piattaforma WatchOCR va avviata utilizzando il file ISO, a partire da un CD ROM, una chiavetta USB di boot oppure una macchina virtuale. Si tratta di una “distribuzione live” perché non necessita di scrivere alcunché sul disco fisso.
Invio di singoli file PDF od elaborazione automatica di più documenti
Per avviare WatchOCR, basta riavviare il personal computer lasciando inserito nel lettore il CD precedentemente masterizzato oppure connessa alla porta USB la chiavetta resa avviabile (ad esempio utilizzando YUMI; vedere questi nostri articoli).
Suggeriamo comunque di utilizzare WatchOCR (vedere il riquadro successivo) da una macchina virtuale Linux creata con VirtualBox: è secondo noi il modo migliore e più pratico per utilizzare comodamente la piattaforma per rendere ricercabili i PDF.
Dopo aver avviato WatchOCR, sarà possibile inviare un singolo documento PDF da rendere ricercabile oppure caricare tutti quelli che si desidera vengano elaborati nella directory di rete \\WatchOCRServer\WatchOCR\scanin.
Uno dei modi migliori per utilizzare WatchOCR, secondo noi, è avviare la piattaforma per trasformare un PDF in un documento ricercabile da una macchina virtuale Linux. Allo scopo è possibile utilizzare un software quale VirtualBox.
Si avrà così a disposizione un computer virtuale che, ogni volta avviato, attiverà le funzionalità di creazione dei PDF ricercabili all’interno dell’intera rete locale: ogni client della LAN, infatti, potrà richiedere la conversione di qualunque documento PDF.
Dopo aver installato VirtualBox, suggeriamo di creare una nuova macchina virtuale WatchOCR scegliendo Linux dal menù a tendina Tipo e Linux 2.6 dal menù Versione:
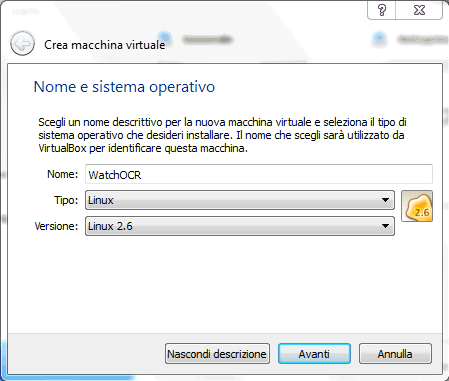
Alla macchina virtuale suggeriamo di associare 512 MB di RAM mentre è più che sufficiente un hard disk virtuale da 8 GB.
Una volta creata la nuova macchina virtuale, si dovrà selezionare dalla finestra principale di VirtualBox, cliccare sul pulsante Impostazioni nella barra degli strumenti, fare clic su Archiviazione, sul piccolo pulsante evidenziato in figura, quindi specificare la ISO di WatchOCR:
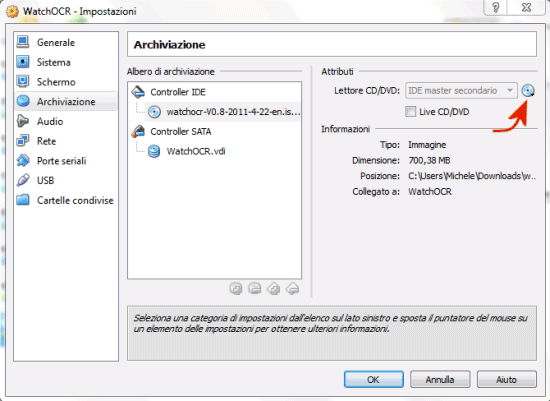
Nella sezione Rete, bisognerà scegliere Connessa a quindi Scheda con bridge in modo tale che la macchina virtuale VirtualBox appaia, “agli occhi” degli altri client connessi in rete locale, come un computer “fisico”.
A questo punto si potrà avviare la macchina virtuale di WatchOCR.
Dopo la fase di boot della distribuzione Linux, ci si troverà dinanzi alla seguente schermata:
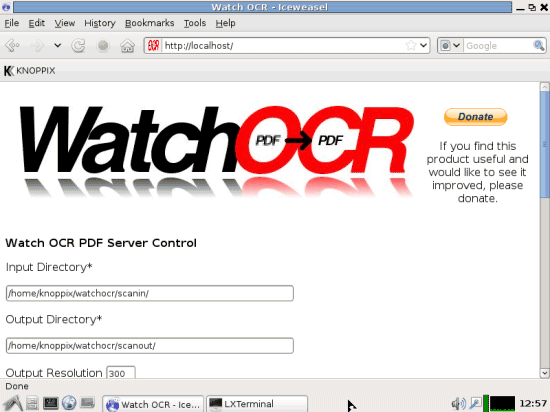
La pagina di configurazione visualizzata da parte del browser Iceweasel consente di impostare il funzionamento di WatchOCR ed è accessibile da qualunque client connesso in rete locale (basta digitare l’URL http://watchocrserver nella barra degli indirizzi di qualunque browser web).
Utilizzare WatchOCR per rendere ricercabili decine di documenti PDF
Solitamente, le impostazioni di default di WatchOCR vanno più che bene. Potrebbe essere interessante, qualora lo si ritenesse opportuno, modificare la risoluzione di output per i file PDF prodotti dal programma (campo Output resolution).
Tra le possibilità avanzate, WatchOCR consente di ruotare automaticamente le pagine componenti i file PDF ed eventualmente ripulire il contenuto del documento da imperfezioni ed elementi superflui.
Suggeriamo di lasciare sempre abilitata la casella Preserve originals: essa consente di fare in modo che i file PDF di partenza “dati in pasto” a WatchOCR non vengano mai modificati o cancellati (essi saranno conservati nella cartella preserve).
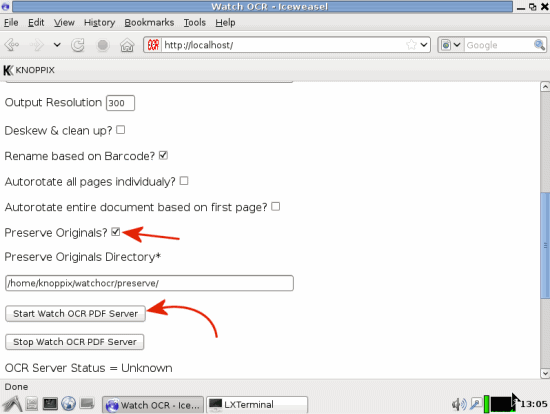
Per iniziare a lavorare con WatchOCR basterà quindi fare clic sul pulsante Start Watch OCR PDF Server.
A questo punto, collegandosi con l’indirizzo http://watchocrserver/upload.html da qualunque browser web, si potrà inviare a WatchOCR il documento PDF da rendere ricercabile.

Per procedere, basta cliccare sul pulsante Sfoglia, selezionare il file PDF dal disco fisso locale o da qualunque altra unità (rimovibile o di rete), quindi cliccare su Upload.

Dopo alcuni secondi, facendo clic sul link View Completed Files, si dovrebbe visualizzare un link al file PDF appena sottoposto ad elaborazione.

Cliccando sul nome del file PDF, si dovrebbe visualizzare la versione del documento già divenuta ricercabile (basterà avviare una ricerca di una parola per accorgersene immediatamente).
In alternativa, per rendere modificabili più file PDF, basterà accedere – da qualunque macchina collegata in rete locale – al percorso \\WatchOCRServer\WatchOCR e copiare i file da elaborare nella sottodirectory scanin:
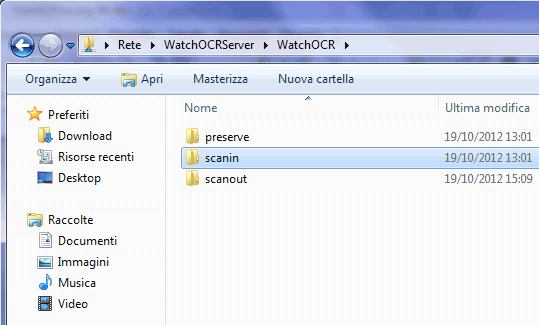
Via a via che WatchOCR creerà PDF ricercabili, il file di origine sarà spostato nella cartella preserve mentre i file già elaborati verranno posti nella directory scanout.
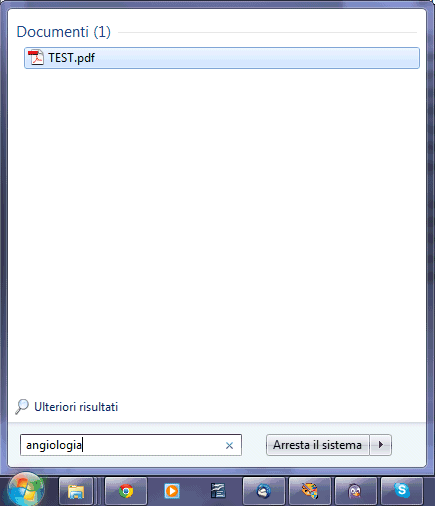
Copiando nella cartella Documenti di Windows i file PDF generati da WatchOCR (attingendo al contenuto della directory scanout), anche Windows si accorgerà che essi contengono testo ricercabile. Digitando lo stesso termine che avevamo inserito prima nella casella Cerca programmi e file di Windows 7, adesso il sistema operativo mostra il documento PDF precedentemente sottoposto a WatchOCR:
Ecco cosa accade cercando un termine presente nel PDF reso ricercabile (abbiamo oscurato, in grigio, per motivi di privacy le informazioni sensibili):
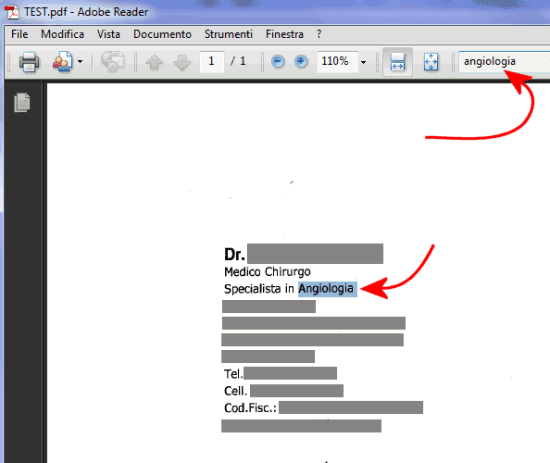
Da notare anche la dimensione dei documenti PDF che, dopo l’elaborazione con WatchOCR, risultano generalmente meno pesanti in termini di spazio occupato su disco e quindi più facilmente gestibili per l’invio come allegati a messaggi di posta elettronica.
/https://www.ilsoftware.it/app/uploads/2025/07/menu-start-windows-11-categorie-file-json.jpg "Windows 11: arrivano gli sfondi desktop dinamici basati sull'AI")
/https://www.ilsoftware.it/app/uploads/2025/07/windows-11-redirectionguard.jpg "Windows 11 nasconde una protezione segreta contro i link NTFS: cos’è RedirectionGuard")
/https://www.ilsoftware.it/app/uploads/2025/07/7zip-compressione-parallelizzazione-cpu-moderne.jpg "7-Zip 25.00 sblocca oltre 64 thread: compressione parallela ultraveloce")
/https://www.ilsoftware.it/app/uploads/2025/07/vulnerabilita-driver-windows.jpg "I driver Windows più vulnerabili: viaggio tra le falle Ring 0")