/https://www.ilsoftware.it/app/uploads/2026/04/fingerprinting-browser-firefox-tor-identificatore-univoco.jpg "Firefox ha un identificatore stabile anche su Tor: il rischio privacy")
Fingerprinting significa identificare un utente senza usare cookie, sfruttando caratteristiche tecniche del browser e del dispositivo. Non è una tecnica nuova, ma è diventata sempre più sofisticata perché aggira i meccanismi classici di protezione. In pratica, un sito raccoglie informazioni come risoluzione, font, API disponibili, comportamento JavaScript e le combina per creare una impronta digitale unica.
Gli sviluppatori di Fingerprint.com lavorano proprio su tecniche di identificazione dei browser: il loro lavoro consiste nel trovare segnali nascosti che permettano di distinguere un’istanza del browser da un’altra. Provate la dimostrazione: se visitate la pagina nella modalità di navigazione normale, attivando la modalità in incognito o una VPN, l’identificativo (che vi riconosce in maniera univoca) non cambia mai.
Firefox: identificatore nascosto dentro IndexedDB
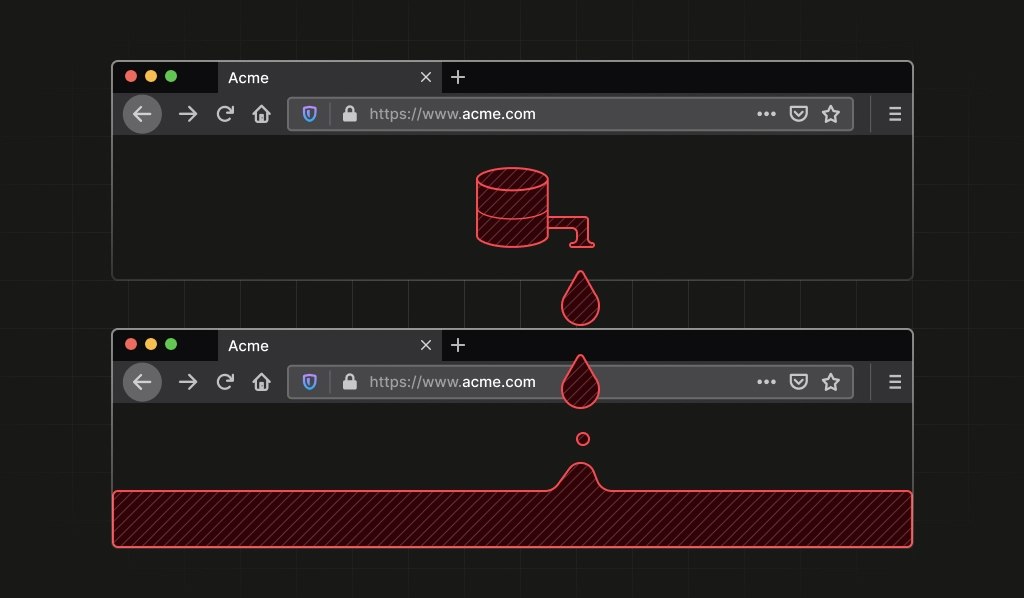
I ricercatori di Fingerprint.com hanno annunciato ad aprile 2026 di aver individuato un “segnale nascosto” in Mozilla Firefox che consente ai siti Web di identificare tutte le sessioni Tor private di ciascun utente. Un comportamento interno del browser, pur non essendo progettato per identificare l’utente, produce un risultato deterministico e quindi riutilizzabile come fingerprint.
Sfruttando l’API IndexedDB, un sito può creare una serie di database locali e osservare l’ordine con cui il browser restituisce tali informazioni. Quell’ordine non è casuale: dipende da strutture dati interne a Firefox e rimane stabile per tutta la durata del processo del browser.
Il risultato è un identificatore implicito. Due siti completamente diversi, senza condividere alcun dato tra loro, possono ottenere la stessa sequenza e quindi dedurre di trovarsi di fronte alla stessa istanza del browser (e di conseguenza, con buona probabilità, allo stesso utente).
Questo aspetto è particolarmente critico nel caso di Tor Browser. Anche se Tor Browser, programma sviluppato per garantire anonimato agli utenti, utilizza circuiti di rete differenti e cancella cookie e cronologia tra una sessione e l’altra, il browser stesso continua a esporre lo stesso segnale tramite IndexedDB a siti diversi.
Nella modalità di navigazione privata (CTRL+P) di Firefox , l’identificatore univoco può persistere anche dopo la chiusura di tutte le finestre private, purché il processo di Firefox rimanga in esecuzione. In Tor Browser, l’identificatore persiste anche attivando la funzione Nuova identità, progettata per essere un ripristino completo che cancella cookie e cronologia del browser e utilizza nuovi circuiti Tor.
La funzione Nuova identità di Tor è descritta come pensata per gli utenti che “vogliono impedire che la loro successiva attività di navigazione sia collegabile a ciò che stavano facendo prima“. La vulnerabilità individuata vanifica di fatto le garanzie di isolamento su cui gli utenti fanno affidamento.
Il ruolo di Tor Browser (e sì, è basato su Firefox)
Tor Browser è una versione modificata di Firefox ESR (Extended Support Release): questo significa che eredita gran parte del codice di Firefox (incluso IndexedDB) pur applicando molteplici modifiche mirate alla privacy e all’anonimato.
Non si limita a nascondere l’IP pubblico reale tramite onion routing: lavora anche sul contrasto al fingerprinting. Tor Browser, infatti, standardizza i parametri del browser, limita le API esposte e uniforma il comportamento tra utenti. L’obiettivo è chiaro: rendere tutti gli utenti indistinguibili l’uno dall’altro.
Tor promette una proprietà fondamentale: unlinkability, cioè la difficoltà di collegare due sessioni tra loro, ma il bug scoperto da Fingerprint.com identificatore che resta stabile per tutto il processo, non è legato ai siti e sopravvive al reset della sessione.
Non significa che Tor sia “rotto”, bensì che una singola falla applicativa può ridurre l’efficacia del modello di anonimato, cosa già nota nella letteratura su Tor: molte compromissioni derivano proprio da comportamenti o vulnerabilità del software client, non dalla rete stessa.
I dettagli tecnici che portano al fingerprinting
Quando un sito crea un database IndexedDB, nel caso di Firefox il nome scelto dallo sviluppatore non è sempre utilizzato direttamente come riferimento interno: il nome logico è associato a un identificatore generato, tipicamente un UUID. Questa associazione è memorizzata in una struttura globale, una hash map, condivisa tra tutti i siti.
Al momento in cui funzione indexedDB.databases() è invocata, Firefox raccoglie i riferimenti ai database esistenti e li inserisce in una struttura dati di tipo hash set. Qui si inserisce il dettaglio cruciale: non viene applicato alcun ordinamento esplicito prima di restituire i risultati.
L’iterazione su una hash set non segue l’ordine di inserimento, né un criterio leggibile come quello alfabetico. Dipende invece dalla distribuzione interna degli elementi, che a sua volta deriva dalla funzione di hashing e dai valori utilizzati come chiavi, cioè gli UUID generati in precedenza.
Il risultato è una sequenza che appare casuale, ma che in realtà è deterministica: a parità di stato interno della struttura, l’ordine restituito resta sempre lo stesso.
Se un sito crea un insieme noto di database, ad esempio con nomi fissi, e poi osserva l’ordine con cui sono restituiti, ottiene una permutazione specifica. Quella permutazione dipende da tre fattori: gli UUID assegnati, il comportamento della funzione di hashing e lo stato della struttura dati.
Il punto è che questi elementi non cambiano durante la vita del processo: di conseguenza, anche la permutazione resta stabile. Due siti diversi, eseguendo la stessa sequenza di operazioni, ottengono lo stesso risultato senza bisogno di condividere dati tra loro.
Il ruolo dell’entropia
La capacità di identificazione dipende dall’entropia, cioè dalla quantità di informazione che la sequenza può rappresentare. Se un sito gestisce N database distinti, il numero totale di modi in cui questi possono essere ordinati è pari a N fattoriale (N!, cioè il prodotto di tutti i numeri interi da 1 a N), con entropia teorica di log2(N!) (Claude Shannon, entropia nella teoria dell’informazione). Ad esempio, con 16 elementi si ottiene uno spazio teorico di circa 44 bit, un valore che indica quante informazioni sono necessarie per rappresentare tutte le possibili combinazioni.
Va detto però che non tutte le permutazioni sono necessariamente raggiungibili: la distribuzione dipende dall’implementazione della hash set e dalla funzione di hashing. Tuttavia, anche una frazione di quello spazio è più che sufficiente per distinguere un numero elevato di istanze dei browser in scenari reali.
In altre parole, non serve la perfezione assoluta: basta che il segnale sia abbastanza vario e stabile da evitare collisioni frequenti.
La correzione introdotta da Mozilla
Mozilla ha risolto il problema nelle versioni Firefox 150 e ESR 140.10.0, intervenendo direttamente sulla logica di restituzione dei dati. L’approccio scelto è semplice: applicare un ordinamento canonico, tipicamente lessicografico, prima di restituire i risultati.
La scelta adottata elimina completamente l’entropia derivante dall’ordine interno senza compromettere l’utilità dell’API IndexedDB. Un’alternativa sarebbe stata la randomizzazione, ma avrebbe introdotto complessità e comportamenti meno prevedibili per gli sviluppatori.
La correzione è tracciata come bug 2024220 nel sistema Mozilla e si applica anche ai browser derivati, quindi anche a Tor Browser, a condizione che integrino la patch.
/https://www.ilsoftware.it/app/uploads/2026/07/chrome-velocizza-scorrimento-pagine-browser-android.jpg "Chrome su Android dimezza gli scatti durante lo scorrimento: come ci riesce")
/https://www.ilsoftware.it/app/uploads/2023/09/Firefox-Generico.jpg "Firefox 153 sfida NVIDIA su Linux: arriva Vulkan Video")
/https://www.ilsoftware.it/app/uploads/2026/07/kagi-orion-browser-motore-webkit.jpg "Orion 1.1 sfida Chrome: il browser senza pubblicità punta sugli utenti")
/https://www.ilsoftware.it/app/uploads/2026/07/firefox-dentro-chrome-webassembly.jpg "Firefox gira dentro Chrome: Gecko diventa un'app WebAssembly")