/https://www.ilsoftware.it/app/uploads/2024/01/migrazione-dati-on-premises-cloud-cubbit.jpg "Migrazione dati da on-premises al cloud, in sicurezza e compliance alle leggi nazionali")
La migrazione dati da soluzioni on-premises al cloud rappresenta un passo cruciale nell’evoluzione digitale di ogni organizzazione moderna. Questo spostamento consente un accesso più rapido alle informazioni, una maggiore flessibilità operativa e una riduzione dei costi infrastrutturali. Tuttavia, la sicurezza e la conformità normativa rimangono questioni fondamentali quando si valuta un processo di transizione totale o parziale verso il cloud. In questo contesto, è essenziale comprendere come salvare i dati in modo sicuro e in piena conformità con le normative vigenti (disposizioni AgID, ISO 27001 e GDPR).
Il cloud, infatti, è spesso percepito come la risposta giusta alle esigenze di sicurezza, riservatezza, integrità e disponibilità dei dati aziendali. In realtà, le soluzioni cloud non sono affatto tutte uguali ed anzi in molti casi ha senso privilegiare un approccio ibrido che da un lato si appoggi ai servizi disponibili fuori dalla propria infrastruttura aziendale, ma dall’altro continui ad affidarsi anche alle risorse disponibili in ambito locale, on-premises appunto.
Si pensi banalmente alla strategia del backup 3-2-1: essa prevede che almeno una copia dei dati sia conservata fuori dal perimetro della propria organizzazione. In questo senso, il cloud rappresenta la chiave di volta per proteggersi da incidenti e veri e propri disastri che dovessero interessare i dati conservati in locale.
Cubbit: piattaforma S3-compatibile e geo-distribuita
Cubbit è una piattaforma nata in Italia, S3-compatibile e geo-distribuita. Ciò significa che può integrarsi con l’interfaccia di Amazon S3 (Simple Storage Service) e smistare i dati di proprietà degli utenti su nodi geograficamente distribuiti. È questa una caratteristica che fa la differenza rispetto allo schema tradizionale usato dalla stragrande maggioranza dei servizi cloud.
Invece che avere i propri dati concentrati in un unico data center, Cubbit utilizza un approccio multilivello peer-to-peer che prevede la gestione e la conservazione delle informazioni di ciascun utente su più nodi fisicamente separati, tutti dislocati, ad esempio, in Italia:
- Crittografia. I dati sono cifrati AES-256, un algoritmo crittografico di livello militare.
- Divisione. I dati crittografati sono frammentati in N pezzi, ciascuno indistinguibile dall’altro.
- Ridondanza. Gli N pezzi sono moltiplicati in K frammenti tramite l’uso di codici a correzione di errore Reed-Solomon.
- Geo-distribuzione. I dati degli utenti sono geo-distribuiti, scongiurando i problemi dovuti alla memorizzazione delle informazioni in un singolo punto.

Grazie alle tante integrazioni offerte da Cubbit, la piattaforma cloud può dialogare con una vasta schiera di soluzioni a loro volta compatibili S3, compreso lo stesso AWS di Amazon. Questo significa che i dati possono essere copiati e spostati da e verso soluzioni di terze parti, con una soluzione altamente interoperabile che guarda alla massima integrazione e azzera i costi per la movimentazione dei dati stessi.
Com’è fatta l’architettura di Cubbit
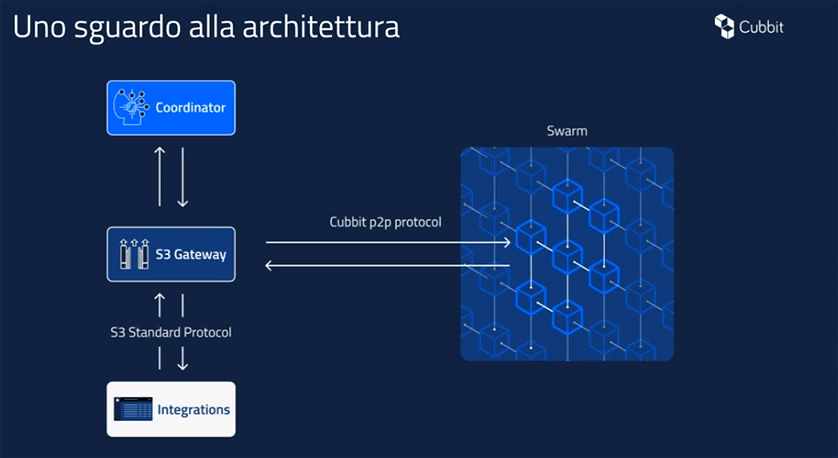
Cubbit chiama swarm l’insieme di nodi che ospitano i dati degli utenti (in Italia ce ne sono ad oggi oltre 2.000): costituiscono la spina dorsale della piattaforma di cloud storage e formano una vera e propria rete peer-to-peer.
Le chiamate S3 provenienti dai dispositivi client e dalle integrazioni alle quali facevamo riferimento in precedenza, sono automaticamente gestite da un Gateway S3 che funge da interfaccia con la swarm attraverso il protocollo peer-to-peer utilizzato da Cubbit.
Ad orchestrare, sovrintendere e monitorare la rete c’è il Coordinator, un’entità formata da un gran numero di microservizi che ricopre il ruolo di controllore su tutto ciò che avviene all’interno della piattaforma. È l’hub centrale responsabile dell’ottimizzazione della rete, del miglioramento della tolleranza ai guasti e del recupero efficiente dei file.
Vantaggi della strategia mista: locale più cloud
La scelta tra una soluzione di archiviazione completamente locale o una strategia mista, che combina archiviazione cloud e locale, può influenzare significativamente la sicurezza e la gestione dei dati di qualsiasi professionista e realtà aziendale.
Mentre il cloud offre sicuramente una maggiore accessibilità, mantenere una copia locale dei dati fornisce un livello aggiuntivo di sicurezza. In caso di interruzioni del servizio cloud o di eventi catastrofici, l’accesso ai dati locali può essere vitale per garantire la continuità operativa.
Con una soluzione mista, è possibile ottimizzare le prestazioni in base alle specifiche esigenze nella gestione dei dati. In un altro articolo abbiamo visto la differenza tra dati freddi e dati caldi: i primi, spesso piuttosto voluminosi ma raramente utilizzati, dovrebbero essere conservati ricorrendo a strumenti (online e offline) capaci di garantire un costo a gigabyte ridotto. Spesso si tratta infatti di informazioni che l’azienda è tenuta a conservare per un certo numero di anni ai fini della conformità legale o fiscale.
Il problema della compliance normativa
Tra le soluzioni disponibili per una strategia mista, Cubbit si distingue per la sua attenzione alla sicurezza e alla sovranità digitale. Cubbit combina la scalabilità e la flessibilità del cloud con la compliance normativa.
Il legislatore europeo sta privilegiando il concetto di sovranità del dato, sostenendo l’utilizzo di soluzioni che consentano di mantenere le informazioni all’interno dei confini degli Stati membri dell’Unione.
Come accennato in precedenza, inoltre, è spesso richiesta la creazione di un backup immutabile, ovvero di un archivio il cui contenuto non possa essere cancellato o modificato da parte di niente e di nessuno. In questo senso le funzionalità Multi-Site Object Lock e Multi-Site Versioning offerte da Cubbit consentono di proteggere i dati aziendali usando un approccio geo-distribuito.
Nel primo caso, il termine Object Lock sta a significare che è possibile creare archivi di dati immutabili sul cloud. Cubbit assicura così la disponibilità, l’integrità dei dati e la conformità con le normative vigenti in materia di data retention. Con Versioning, invece, si fa riferimento al fatto che la piattaforma può conservare più versioni degli stessi file tenendo traccia delle modifiche applicate nel corso del tempo. Diventa in questo modo piuttosto semplice annullare gli effetti di un errore, ad esempio una modifica indesiderata su un file o l’eliminazione di una cartella, e tornare sui propri passi.
Come migrare i dati utilizzando S3
Cubbit ha realizzato un’unica interfaccia per gestire i file memorizzati sulla piattaforma. È accessibile via Web, con qualunque browser, e consente di creare bucket, ovvero i contenitori che ospitano i dati, di attivare object locking e versioning, di caricare e scaricare file, generare URL temporanei, gestire liste di controllo degli accessi (ACL), le identità digitali dei vari utenti e le relative policy.
Cliccando su API keys, nella colonna di sinistra, si ha la possibilità di generare delle chiavi di accesso univoche (Generate new client API key) utilizzabili per accedere alle risorse memorizzate sulla piattaforma Cubbit, a partire da vari client e integrazioni.
Configurare l’interfaccia a riga di comando AWS per accedere al cloud storage Cubbit
A dimostrazione di come Cubbit sia un prodotto pienamente S3-compatibile, in questo video pubblicato su YouTube si spiega come avviare la migrazione dati da on-premises a cloud utilizzando AWS CLI.
AWS CLI (Command Line Interface) è un software open source che consente di interagire anche con i servizi di storage S3 usando la finestra del terminale. Amazon offre la possibilità di usare comandi di alto livello per dialogare con il servizio cloud S3-compatibile nonché vere e proprie API S3. Indipendentemente dalla scelta, Cubbit supporta entrambe le modalità di interazione con i suoi servizi di cloud storage.
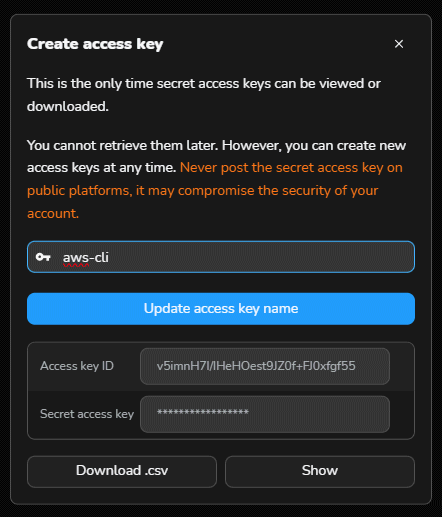
L’Access key ID e la chiave privata (Secret access key) restituite dall’interfaccia Cubbit in fase di creazione, possono essere eventualmente impostate a livello di AWS CLI come variabili d’ambiente. Il client AWS CLI è compatibile con Linux, macOS e Windows (il download è possibile da questa pagina): con i comandi export AWS_ACCESS_KEY_ID= ed export AWS_SECRET_ACCESS_KEY= si possono definire, sui sistemi Linux e macOS, Access key ID e Secret access key da usare per la connessione remota.

La stessa cosa si può fare su Windows da prompt dei comandi o da finestra PowerShell ricorrendo, rispettivamente, ai comandi setx e $Env: e abbinandoli alle variabili d’ambiente AWS_ACCESS_KEY_ID e AWS_SECRET_ACCESS_KEY.
L’impostazione della variabile d’ambiente AWS_ENDPOINT_URL su https://s3.cubbit.eu consente, infine, di indicare ad AWS CLI la volontà di accedere alla piattaforma di cloud storage Cubbit. A questo proposito, verificare di aver installato la versione più aggiornata di AWS CLI perché in quelle più vecchie l’uso della variabile AWS_ENDPOINT_URL non è previsto.
Come dialogare con Cubbit usando AWS CLI
Una volta configurate le chiavi di accesso a Cubbit e l’URL HTTPS del servizio, è possibile impartire il semplice comando aws s3 ls per ottenere la lista dei bucket presenti mentre, se si volessero usare le API S3, la sintassi da utilizzare è la seguente:aws s3api list-buckets.
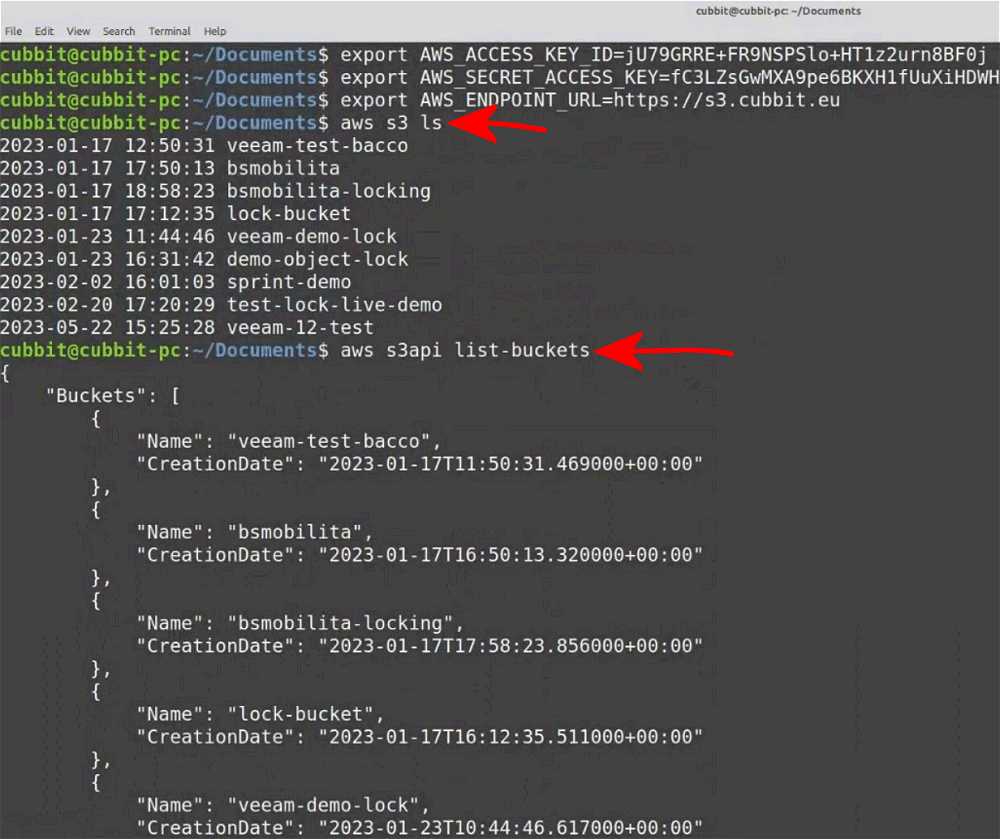
Nel primo caso, ls consente di passare a Cubbit l’analogo comando Linux che restituisce tutto il contenuto di una cartella; nel secondo, con le API S3 si ottiene come output un oggetto JSON più complesso sul quale è possibile lanciare delle interrogazioni (per la sintassi da usare, si può fare riferimento alla guida di JMESPath).
Utilizzando appositi comandi, è inoltre possibile creare nuovi bucket e, ad esempio, copiare i dati da sistemi locali al cloud di Cubbit e viceversa. L’istruzione sfruttabile per avviare un’attività di upload è simile alla seguente: aws s3 cp nomerisorsa s3://nome-bucket/ dove cp è il comando “copia” di Linux. Con AWS CLI si può anche configurare una sincronizzazione bidirezionale tra Cubbit e i sistemi locali dell’azienda.
Gli amministratore di rete possono quindi creare degli script personalizzati per copiare o sincronizzare i dati da e verso Cubbit, ad esempio rispettando una specifica pianificazione.
Come provare subito il cloud storage di Cubbit
Per approfondire, è possibile iniziare una prova gratuita di Cubbit: la piattaforma italiana offre a tutti gli interessati 1 Terabyte di spazio gratis per 15 giorni, senza obbligo di acquisto e senza la necessità di inserire alcuna carta di credito. In questo modo è possibile verificare le potenzialità della piattaforma e rendersi conto di come sia facile integrarla all’interno della propria infrastruttura.
/https://www.ilsoftware.it/app/uploads/2026/06/ragazza-guarda-smartphone-in-modo-attento.jpg "Cloud storage a vita: il servizio svizzero pCloud offre il 50% di sconto")
/https://www.ilsoftware.it/app/uploads/2026/07/trusted-launch-windows-server.jpg "Windows Server protegge le VM Hyper-V prima dell'avvio con Trusted Launch")
/https://www.ilsoftware.it/app/uploads/2024/02/vulnerabilita-android-dispositivi-a-rischio.jpg "Google ora conteggerà i dati di backup di Android nel limite di spazio di archiviazione")
/https://www.ilsoftware.it/app/uploads/2026/06/container-linux-windows-wslc.jpg "Microsoft presenta WSL Containers: cosa cambia per Linux su Windows")