/https://www.ilsoftware.it/app/uploads/2023/05/img_24386.jpg "URL: cos'è, come funziona e quali sono i pericoli")
Per consultare una qualunque pagina Web digitiamo nella barra degli indirizzi del browser un URL o comunque clicchiamo su link che vi fa riferimento: gli URL sono infatti presenti a decine all’interno del sorgente HTML. Ma cos’è un URL, com’è fatto e come funziona?
Cos’è un URL
Un URL (Uniform Resource Locator) è una sequenza di caratteri che identificano in modo univoco una risorsa su una rete di computer, quindi non necessariamente su Internet. Gli URL possono infatti essere utilizzati all’interno della rete locale per accedere a risorse disponibili in LAN.
La struttura di un URL è composta di diverse parti e può essere schematizzata nel seguente modo tenendo presente che molte delle informazioni rappresentate tra parentesi quadre sono opzionali:
Gli URL più comuni con i quali si ha a che fare tutti i giorni sono quelli che cominciano per HTTPS o HTTP: si tratta dei protocolli di livello applicativo usati per trasferire le informazioni che compongono le pagine Web. Per quanto riguarda le differenze tra HTTPS e HTTP in questo articolo ci limitiamo a dire che nel primo caso i dati scambiati tra server Web remoto e client dell’utente (browser) viaggiano in forma crittografata e non sono quindi leggibili né modificabili da parte di soggetti terzi non autorizzati.
Cliccando sulla barra degli indirizzi del browser si può verificare che nella maggior parte dei casi si ha a che fare con URL HTTPS: la cosa è confermata dalla presenza di un lucchetto.
Partendo da sinistra e continuando verso destra seguono altre informazioni: nel caso degli indirizzi Web (HTTP/HTTPS) il nome a dominio del sito oppure un indirizzo IP pubblico (raggiungibile pubblicamente attraverso la rete Internet) o privato (accessibile solo in rete locale).
Cercate ad esempio software su Google: la pagina dei risultati dell’interrogazione viene richiamata con un URL specifico.
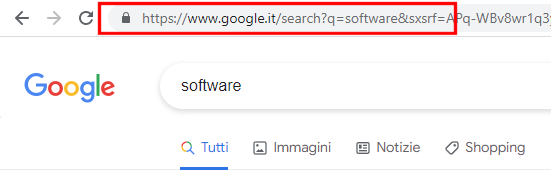
Guardate cosa c’è nella barra degli indirizzi: si comincia con il riferimento al protocollo (https://) poi c’è il nome a dominio www.google.it.
Segue il percorso search e infine, dopo il simbolo del punto interrogativo la cosiddetta querystring ovvero l’interrogazione che è stata passata alla pagina di ricerca insieme con una serie di parametri aggiuntivi (seguono separati dal simbolo &).
Si tratta esattamente dello schema di URL visto in precedenza: nel caso dei protocolli che rispondono sulle cosiddette well-known ports non c’è bisogno di specificare il numero della porta perché, ad esempio, HTTPS usa di default la porta TCP 443 mentre HTTP la TCP 80.
A stretto rigore lo schema pubblicato da IETF che vede tra gli autori anche la firma di Tim-Berners Lee, padre del World Wide Web, parla di URI (Uniform Resource Identifier) e non di URL.
URI è infatti un concetto più generale: un URI permette di identificare una risorsa fisica o logica; un URL è un sottoinsieme degli URI.
Principali differenze tra URI e URL
Dicevamo che gli URL rappresentano un sottoinsieme degli URI: essi specificano in quale luogo esiste una specifica risorsa e come è raggiungibile; gli URI identificano la risorsa.
L’obiettivo principale di un URL è quello di stabilire dove si trova una risorsa raccogliendo le istruzioni per raggiungerla. Un URL è utilizzato per il networking mentre gli URI hanno valenza più generale.
Basti pensare che il sistema operativo stesso utilizza URI che non sono adoperati in rete. Si pensi alla polemica ingeneratasi a seguito del reindirizzamento delle risorse facenti riferimento all’URI microsoft-edge:// verso browser diversi da Microsoft Edge.
Di fatto, quindi, qualcosa come google.com può essere considerato come un URI perché è semplicemente il nome di una risorsa mentre https://google.com/ è un URL perché indica non solo il nome della risorsa ma anche le modalità per raggiungerla (uso del protocollo HTTPS sulla porta predefinita 443).
Al posto di HTTPS potremmo trovare il riferimento ad altri protocolli come FTP, SSH, SMB e così via.
Cosa contiene un URL e a quali risorse fa riferimento
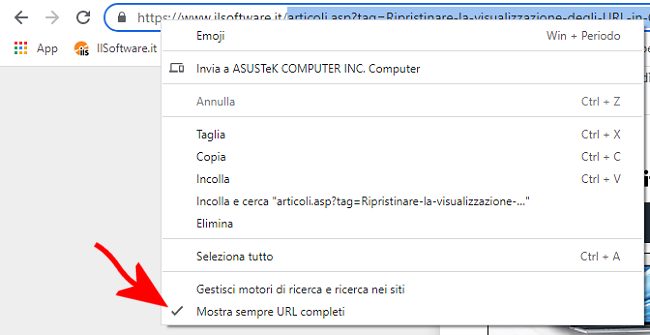
Come è strutturato un URL l’abbiamo già detto per sommi capi: è importante sottolineare che i moderni browser Web (ad esempio Google Chrome) per impostazione predefinita tendono a nascondere una parte dell’URL. Ad esempio il riferimento al protocollo (HTTPS) e il www iniziale (terzo livello utilizzato nella maggior parte dei casi) vengono nascosti.
Abbiamo visto come ripristinare la visualizzazione classica degli URL in Chrome: basta cliccare con il tasto destro sulla barra degli indirizzi e selezionare la voce Mostra sempre URL completi.
Come abbiamo anticipato in precedenza un URL può puntare sia a una risorsa locale che remota. Supponiamo di avere collegato in rete locale un dispositivo che ospita un server Web che risponde sulla porta 80 (HTTP) o 443 (HTTPS): può essere una videocamera, un dispositivo per l’Internet delle Cose, la centrale dell’allarme, una stampante di rete, uno switch o semplicemente il router.
Dopo il riferimento al protocollo, proseguendo verso destra si avrà un indirizzo IP privato.
I gruppi di indirizzi IP utilizzabili all’interno delle reti locali sono stati definiti dalla IANA (Internet Assigned Numbers Authority. Ecco quelli più utilizzati per le LAN:
- 10.0.0.0 – 10.255.255.255 (complessivamente 16.777.216 indirizzi, blocco da 24 bit: 224)
- 172.16.0.0 – 172.31.255.255 (1.048.576 indirizzi, blocco da 20 bit: 220)
- 192.168.0.0 – 192.168.255.255 (65.536 indirizzi, blocco da 16 bit; 216)
Nelle configurazioni più diffuse si usano le classi 192.168.1.1-192.168.1.255 e 192.168.0.1-192.168.0.255 con il router (gateway) che ha IP privato statico 192.168.1.1 o 192.168.0.1. Un URL del tipo http://192.168.1.1 o http://192.168.0.1 generalmente consente di accedere al pannello di amministrazione Web del router.
Gli URL possono però essere utilizzati per indirizzare verso IP pubblici oppure indirizzi mnemonici come google.com o www.google.com. La risoluzione dei nomi a dominio ovvero l’operazione che consente di recuperare l’indirizzo IP pubblico a partire da un indirizzo mnemonico spetta ai server DNS.
Molto spesso i servizi forniti da specifici dispositivi, soprattutto all’interno della rete locale, non sono raggiungibili sulle porte standard bensì su porte specifiche. Recuperando lo schema presentato in apertura, quindi, dopo il nome della porta e l’host (ovvero il nome a dominio o l’indirizzo IP pubblico/privato) si specifica il numero della porta facendolo precedere dal simbolo dei due punti (:).
Esempio:
In questo caso l’URL permette di collegarsi al dispositivo locale con l’indirizzo IP privato 192.168.1.100. La connessione avviene sulla porta 10554 utilizzando il protocollo HTTP (quindi senza crittografia).
URL: quali i possibili pericoli
I criminali informatici, ad esempio coloro che avviano campagne phishing inviando email e messaggi truffaldini attraverso i vari canali (anche attraverso i software di messaggistica e le piattaforme social), confezionano URL malevoli che fanno riferimento a risorse pericolose.
Di solito si tratta di pagine Web che imitano siti legittimi oppure inducono gli utenti a scaricare ed eseguire malware.
Spesso i criminali informatici utilizzano URL come accounts.google.domainxyz.com cercando di trarre in inganno l’utente: si gioca sulla presenza del riferimento ad accounts.google quando il nome a dominio di secondo livello, ovvero quello principale, è posizionato più a destra e in questo caso è domainxyz.com.
Avevamo già parlato dei possibili utilizzi (legittimi) dei domini personalizzati.
In un altro articolo abbiamo visto come verificare se un link è sicuro prima di aprirlo.
Come regola generale va tenuto presente che la stringa nell’URL più a destra nel nome a dominio (la parte che segue il riferimento al protocollo) è il dominio di secondo livello che restituisce l’informazione principale: se si legge google.com significa che l’URL punta su una risorsa effettivamente ospitata sui server di Google; se si legge microsoft.com la risorsa si trova su server Microsoft. Se si leggesse un nome a dominio sconosciuto, tutto ciò che si trova a sinistra non deve essere preso in considerazione.
Si prenda come esempio l’email riprodotta in figura: “Ehi, ti ricordi questa foto“?
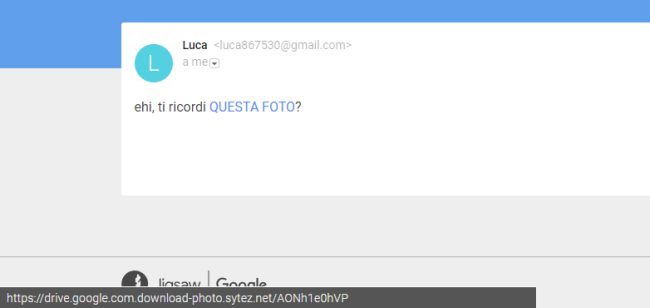
Non si dovrebbe mai fare troppo affidamento sul nome e sull’indirizzo email specificati come mittente perché la loro falsificazione è cosa banale (email spoofing).
Spostando il puntatore del mouse su link e analizzando ciò che compare nella barra di stato del browser, si vede che il browser punta a un URL del tipo drive.google.com.download-photo.sytez.net.
La parte iniziale dell’URL è creata appositamente per ingannare l’utente: non si tratta di un URL Google perché il nome a dominio di secondo livello è sytez.net.
Anche quella che segue è un’email palesemente truffaldina perché spostando il puntatore del mouse sul pulsante Cambia password il nome a dominio di secondo livello che si legge nella barra di stato è ml-security.org.
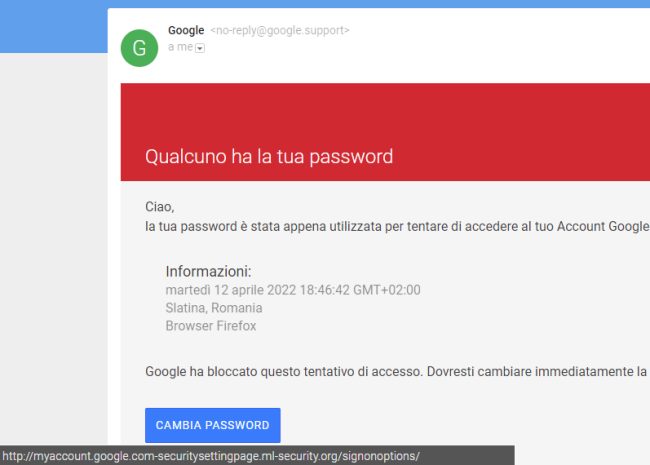
Tralasciamo il fatto che si tratta di un URL HTTP e Google non utilizza “da secoli” indirizzi che non prevedono l’utilizzo della cifratura e di un certificato digitale (HTTPS).
Fate moltissima attenzione, inoltre, ai servizi di accorciamento degli URL come bit.ly, tinyurl.com e così via. Con un semplice trucco, senza cliccare su link, è possibile risalire al reale URL di destinazione: si può usare il sito Check Short URL oppure le indicazioni riportate nell’articolo citato.
/https://www.ilsoftware.it/app/uploads/2025/07/motw-windows-salvataggio-pagine-web-pericoloso.jpg "Basta salvare una pagina Web per infettare il PC Windows (senza avvisi)")
/https://www.ilsoftware.it/app/uploads/2025/06/Chrome_Android_Bar_Blog_Header_V.width-1000.format-webp1.jpg "Chrome su Android: finalmente Google ha ascoltato gli utenti")
/https://www.ilsoftware.it/app/uploads/2025/03/ILSOFTWARE-2-2.jpg "Firefox 140: tutte le novità dell'aggiornamento di giugno 2025")
/https://www.ilsoftware.it/app/uploads/2025/06/Gemini_google-chrome.jpg "Chrome addio su questi smartphone Android: quando non si potrà più usare")