/https://www.ilsoftware.it/app/uploads/2024/04/chatgpt-locale-con-QNAP-NVIDIA-chatrtx.jpg "Eseguire un chatbot come ChatGPT in locale su NAS QNAP")
Retrieval Augmented Generation (RAG) è un modello di intelligenza artificiale che combina due approcci principali: il recupero di informazioni e la generazione di testo. Questo approccio è utilizzato principalmente per estrarre informazioni di valore dai dati aziendali. I Large Language Model (LLM) “generalisti”, infatti, non hanno visibilità sui dati delle singole realtà d’impresa: aziende di qualunque dimensione ma anche piccoli studi professionali. Le loro conoscenze sono infatti “limitate” alle sorgenti di dati pubblicamente accessibili. In questo articolo vediamo come eseguire ChatGPT in locale e personalizzarne il funzionamento grazie a un NAS QNAP.
I server NAS a marchio QNAP sono tra i dispositivi più diffusi, in ambito business, per la memorizzazione, la gestione e il ripristino dei dati. Come abbiamo raccontato in altri nostri articoli, i dispositivi di storage QNAP sono diventati veri e propri computer, capaci di garantire prestazioni elevate. Abbiamo anche fatto degli esempi concreti di dispositivi evoluti utilizzabili ad esempio nel settore manufatturiero.
I NAS QNAP offrono un ricco catalogo di applicazioni da installare direttamente sui dispositivi e sono ampiamente personalizzabili, con la possibilità di sbloccare le funzionalità più adatte per la propria azienda.
ChatGPT in locale su NAS QNAP: che bella idea!
QNAP supporta l’utilizzo di GPU in molti dei suoi sistemi NAS. Allo stesso modo, l’azienda taiwanese offre la possibilità di installare e utilizzare una nutrita schiera di app che a loro volta possono trarre vantaggio dall’uso delle GPU. Virtualization Station, in particolare, è un hypervisor per i NAS QNAP che consente agli utenti di creare e gestire macchine virtuali. Questa soluzione mette a disposizione un ampio set di funzionalità, compreso il cosiddetto GPU passthrough, ossia la possibilità di interagire direttamente con la sezione video.

I colleghi di StorageReview hanno utilizzato una scheda dedicata NVIDIA RTX A4000 a slot singolo, installandola in un NAS all-flash QNAP TS-h1290FX. È comunque possibile utilizzare altri modelli di NAS QNAP accertandosi di verificare il supporto per Virtualization Station nonché per la scheda grafica PCIe che si desidera installare.
La scheda video dedicata è utilizzabile per eseguire una sorta di chatbot simile a ChatGPT in locale, massimizzando le performance delle attività di inferenza legate all’intelligenza artificiale.
Il primo passo, dopo l’installazione della scheda grafica all’interno dello chassis del NAS QNAP consiste nella creazione di una macchina virtuale con Virtualization Station. La procedura è quella standard: basta predisporre una macchina Windows con 64 GB di memoria e 8 CPU (attivando il CPU passthrough). Ricordiamo che, ad esempio, il NAS TS-h1290FX è perfettamente in grado di sostenere questa configurazione, in quanto basato su processore AMD EPYC 7302P (16 core, 32 thread) e 256 GB di memoria RAM. Nelle opzioni di avvio delle macchina virtuale, si può impostare UEFI come tipologia del BIOS.
Dopo il primo avvio della macchina virtuale (il sistema operativo è installabile a partire da un’immagine ISO ufficiale di Windows), si può abilitare la funzionalità di Desktop remoto. Questo passaggio permette di semplificare notevolmente l’amministrazione del sistema.
Abilitazione del GPU passthrough
GPU passthrough è una tecnica utilizzata nelle macchine virtuali per consentire loro di accedere direttamente alla GPU del sistema host anziché utilizzare una GPU virtuale emulata. La macchina virtuale può così sfruttare appieno la potenza della GPU fisica del sistema host, consentendo carichi di lavoro ad alte prestazioni. Con il GPU passthrough, l’uso della scheda video è assegnato alla macchina virtuale, permettendo di ottenere prestazioni quasi native all’interno dell’ambiente virtuale.
Dopo aver temporaneamente spento la macchina virtuale creata sul NAS QNAP, si può selezionarla in Virtualization Station quindi accedere alla schermata per la modifica della configurazione.
Nella sezione PCIe, si può scegliere di usare la scheda video precedentemente installata all’interno dello chassis. Riavviando la macchina virtuale, si deve procedere con l’installazione dei driver per la scheda grafica.
Accedendo al Task Manager di Windows (CTRL+MAIUSC+ESC), con un clic su Più dettagli quindi su Prestazioni, la GPU deve risultare correttamente riconosciuta e funzionante.
Come eseguire NVIDIA ChatRTX sul NAS QNAP
ChatRTX è un’applicazione sviluppata da NVIDIA che consente agli utenti di personalizzare un Large Language Model (LLM) di tipo GPT (Generative pre-trained transformer), esattamente come quello che OpenAI utilizza per governare il funzionamento di ChatGPT. La principale differenza rispetto a ChatGPT standard, è che ChatRTX può essere connesso ai propri contenuti ovvero accedere alla base di conoscenza (knowledge base) di ogni singola azienda.
Le abilità RAG che caratterizzano uno strumento come ChatRTX, aprono la strada alla possibilità di elaborare documenti aziendali, note, contenuti multimediali, immagini e molto altro ancora. Il vantaggio è quello di avere a disposizione un LLM locale che opera esclusivamente entro i confini del NAS QNAP, senza mai condividere alcun dato sul cloud.
Inoltre, ChatRTX si integra perfettamente con il funzionamento del NAS: non è necessario spostare i dati per sfruttare il modello e il processo è semplice ed economico come inserire una GPU di fascia media nel dispositivo per lo storage a marchio QNAP.
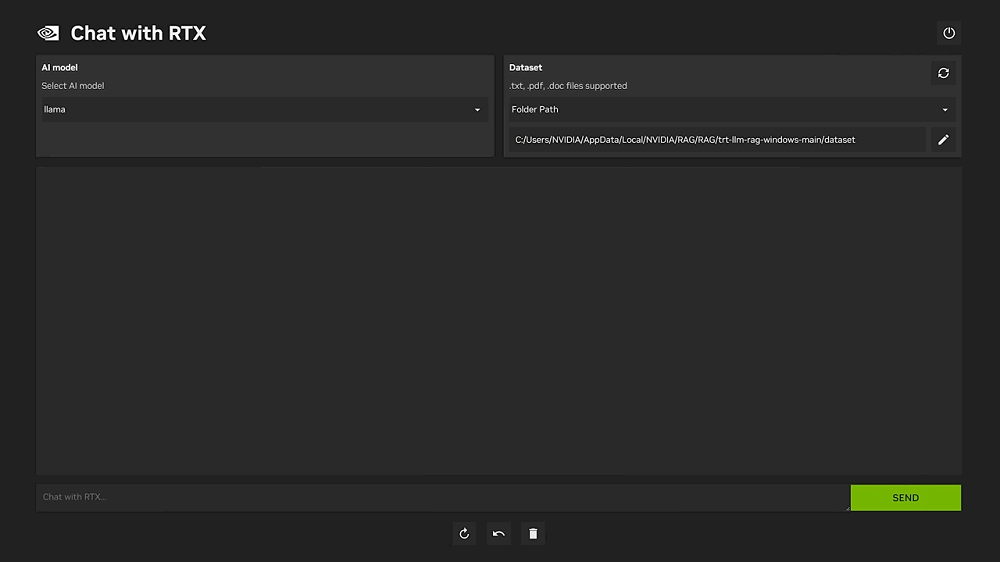
Configurare ChatRTX in pochi semplici passaggi
Dopo aver scaricato e installato NVIDIA ChatRTX nella macchina virtuale creata sul NAS QNAP (il download, avviabile cliccando su Scarica ora, prevede il prelievo di circa 36 GB di dati), si deve premere la combinazione di tasti Windows+R, quindi digitare quanto segue: %localappdata%\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\ui.
Aprendo lo script Python user_interface.py, si deve aggiungere la direttiva share=True, (non dimenticare la virgola) immediatamente al di sotto della riga show_api=False, quindi salvare il file. In questo modo ChatRTX potrà accedere anche alla rete locale.
Avviando Chat con RTX dal menu Start di Windows, l’applicazione mostra una schermata a sfondo nero che mostra un URL pubblico e un indirizzo locale (di tipo localhost). Digitandolo nella barra degli indirizzi del browser Web, è possibile iniziare a colloquiare con il modello generativo.
ChatRTX supporta vari formati di file, tra cui testo puro, PDF, DOC/DOCX e XML. Basta aprire dall’applicazione la cartella contenente i file dell’azienda per caricarli nel catalogo in pochi secondi. In altre parole, puntando alle cartelle contenenti i propri file, il modello generativo inizierà a prenderli in considerazione per ampliare (in locale) la sua conoscenza e personalizzare le risposte (fare riferimento al campo Folder path).
L’immagine in apertura è tratta dalla pagina NVIDIA ChatRTX, il tuo chatbot personalizzato.
/https://www.ilsoftware.it/app/uploads/2024/05/UALink-intelligenza-artificiale-data-center.jpg "Amazon svela quanta acqua consumano davvero i suoi data center")
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-modelli-generativi-business-intelligence-ammagamma.jpg "Xiaomi lancia MiMo Code: agente AI per task di codifica lunga durata")
/https://www.ilsoftware.it/app/uploads/2025/05/anthropic-claude-system-prompt.jpg "Claude Fable 5: Anthropic cambia le regole e scatena polemiche")
/https://www.ilsoftware.it/app/uploads/2026/06/responsabilita-contenuti-google-ai-overview.jpg "Google responsabile degli errori di AI Overview nelle ricerche web: la svolta tedesca")