/https://www.ilsoftware.it/app/uploads/2024/05/paligemma-VLM-come-funziona-cose.png "Con il VLM PaliGemma, il vostro computer comprende il contenuto delle immagini")
Le applicazioni di visione artificiale o computer vision non sono certo una novità. Con l’avvento di modelli generativi basati sull’intelligenza artificiale sempre più performanti, però, si stanno via via aprendo scenari impensabili fino ad appena qualche tempo fa. PaliGemma è una nuova famiglia di VLM (Vision Language Model) appena presentata da Google. Sono modelli che ricevono in input un’immagine corredata da una richiesta in linguaggio naturale e producono, a loro volta, una risposta in formato testuale.
Cos’è un VLM e come funziona Google PaliGemma
Un VLM è un tipo di modello basato sull’intelligenza artificiale progettato per comprendere e manipolare simultaneamente sia le informazioni visive che linguistiche. È capace di analizzare immagini e testo in modo integrato, consentendo di rispondere a domande sul contenuto delle immagini, generare descrizioni automatiche per le immagini e svolgere una vasta gamma di altre attività che coinvolgono la “comprensione” e l’utilizzo di entrambi i modi di comunicazione.
Strumenti come i VLM trovano ampia applicazione in diversi settori, tra cui assistenza sanitaria, automazione industriale, visione artificiale, robotica e molto altro ancora. Si aprono così estese possibilità di interazione tra le macchine e il mondo circostante, con la possibilità di spingere l’accelerazione sull’innovazione. Cogliendo le nuove opportunità offerte dall’intelligenza artificiale.
PaliGemma emerge come un tool pionieristico nell’ambito dei VLM, offrendo una “comprensione” profonda sia delle immagini che del testo.
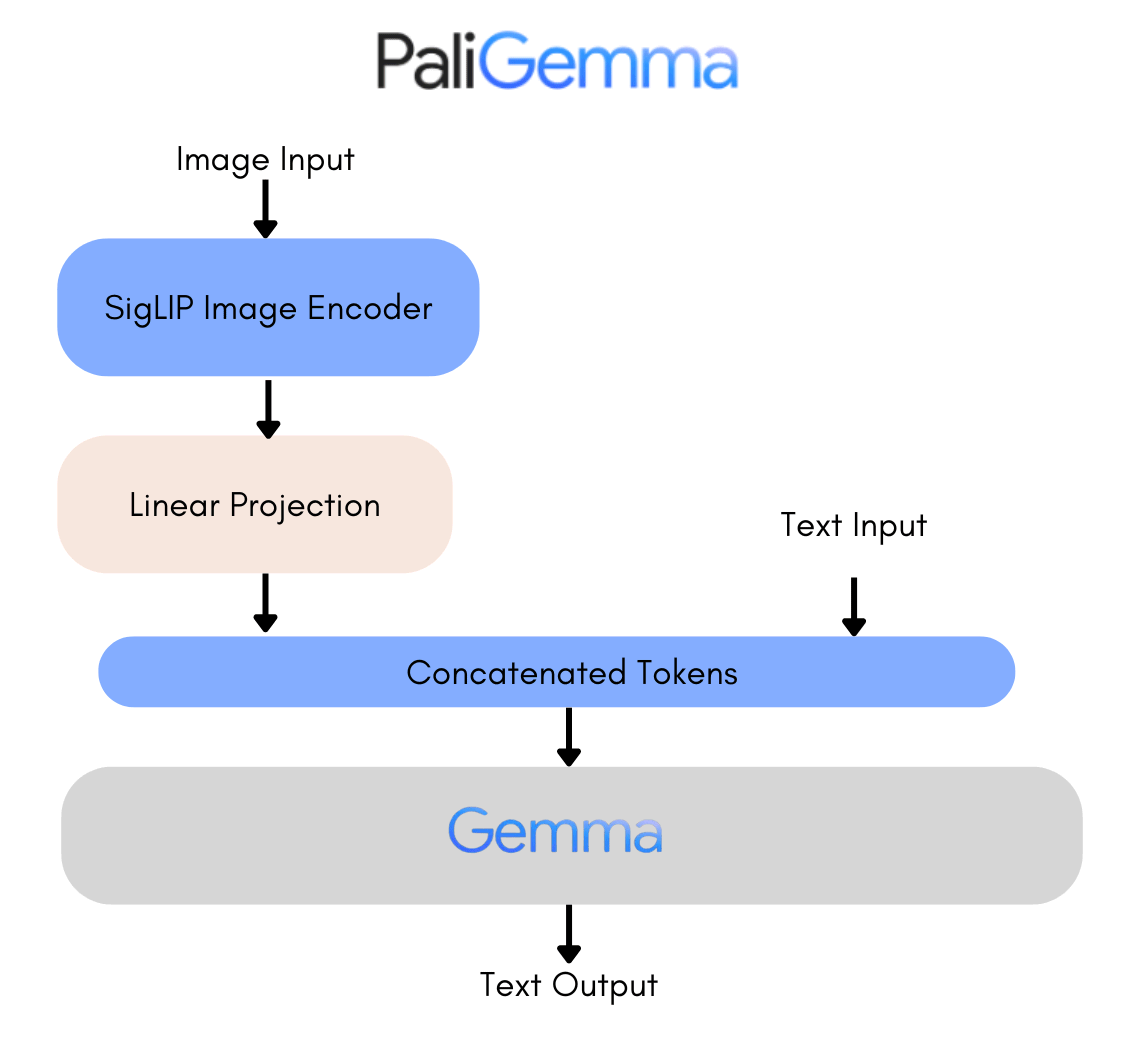
L’architettura di PaliGemma
Uno strumento come PaliGemma rappresenta la convergenza tra elaborazione del linguaggio e visione artificiale nel dominio dell’intelligenza artificiale. Il suo cuore contiene un’architettura sofisticata che ha la capacità di interpretare contemporaneamente sia le immagini che il testo.
I PT, Mix e FT Checkpoint sono categorie di modelli all’interno della famiglia PaliGemma: ognuno di essi è progettato per scopi specifici e ha caratteristiche distintive. I PT Checkpoint, ad esempio, sono preaddestrati su un vasto insieme di dati, generalmente di natura generale e diversificata. Sono concepiti come punto di partenza per ulteriori addestramenti specifici su compiti più mirati.
I checkpoint PT sono flessibili e possono essere adattati a una vasta gamma di compiti tramite il processo di fine-tuning, in cui il modello è ulteriormente addestrato su dati specifici per compiti come il sottotitolaggio delle immagini, la risposta alle domande visive, il riconoscimento degli oggetti e così via.
I Mix Checkpoint sono addestrati su un’ampia gamma di dati e compiti, rendendoli più versatili e adatti per applicazioni di ricerca e sperimentazione. Risultano particolarmente adatti per l’uso generale e l’interazione con prompt di testo libero, consentendo agli utenti di esplorare le capacità del modello su una varietà di compiti senza dover eseguire un fine-tuning preliminare.
Accedendo all’uso degli FT Checkpoint, si beneficia di modelli precedentemente sottoposti a un processo di fine-tuning avanzato, svolto su compiti specifici. Sono ottimizzati per garantire prestazioni elevate con i benchmark accademici. Per questo motivo, sono destinati principalmente a scopi di ricerca e applicazioni in campo universitario.
Per maggiori informazioni, è possibile fare riferimento alla presentazione pubblicata in questo articolo apparso sul blog di Hugging Face.
Le capacità del modello
Abbiamo già detto che PaliGemma permette di affrontare una vasta gamma di compiti diversi, a seconda delle istruzioni fornite dall’utente. Quando si utilizza un modello PaliGemma, è possibile configurare il tipo di compito che si desidera eseguire. Si possono così svolgere attività di rilevamento e di segmentazione.
L’attività di rilevamento è un’operazione fondamentale nell’ambito della visione artificiale che consiste nell’identificare la presenza e la posizione degli oggetti di interesse in un’immagine. Il processo di segmentazione delle entità si riferisce a una tecnica utilizzata nell’ambito della visione artificiale per identificare e separare gli oggetti distinti all’interno di un’immagine. È particolarmente utile quando si desidera ottenere una comprensione dettagliata delle varie entità presenti in un’immagine e isolare specifici oggetti per ulteriori analisi ed elaborazioni.
PaliGemma eccelle nella generazione di didascalie descrittive per le immagini, fornendo contesto e informazioni preziose. Come già evidenziato in precedenza, unendo la “comprensione” delle immagini con la “comprensione” del testo, il modello può rispondere efficacemente alle domande sul contenuto delle immagini.
Oltre alle già citate abilità di segmentazione, infine, PaliGemma può lavorare anche sul contenuto dei documenti sfruttando il riconoscimento ottico dei caratteri (OCR).
Come usare PaliGemma e sbloccare le abilità di visione artificiale su qualunque dispositivo
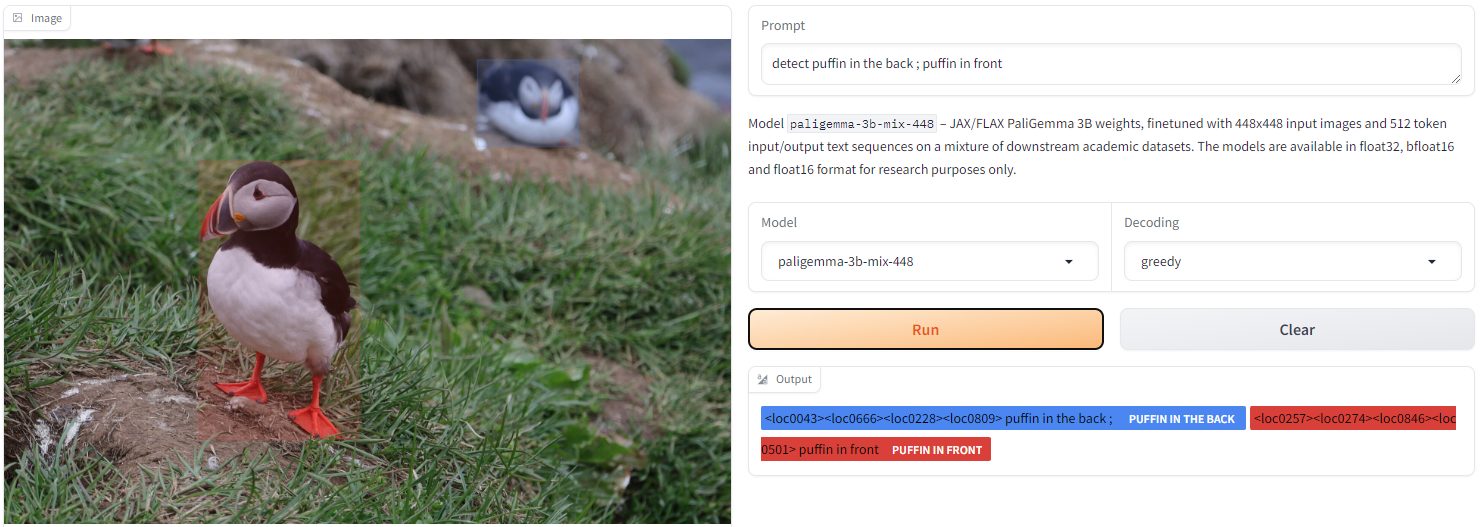
Provare PaliGemma in modo semplice e veloce è possibile visitando la demo su Hugging Face. L’applicazione dimostrativa riceve in input immagini selezionabili direttamente sul dispositivo dell’utente. In alternativa, però, si può fare riferimento agli esempi nella parte inferiore della pagina. Accanto a ciascuno di essi c’è anche il prompt utilizzato dagli autori di PaliGamma per svolgere, per esempio, attività di rilevamento e segmentazione.
Non è strettamente necessario usare l’inglese per interfacciarsi con PaliGemma ma “prefissi magici” come detect e segment si rivelano cruciali, ad esempio, per rilevare oggetti e ottenere una risposta contenente il posizionamento di ciascuno di essi.
Come si vede, PaliGemma si trova a suo agio con domande un po’ più articolate. Sottoponendogli un’immagine come quella in figura e chiedendo “chi è raffigurato nel murales“, il modello di Google risponde subito “David Bowie“, senza alcuna incertezza.
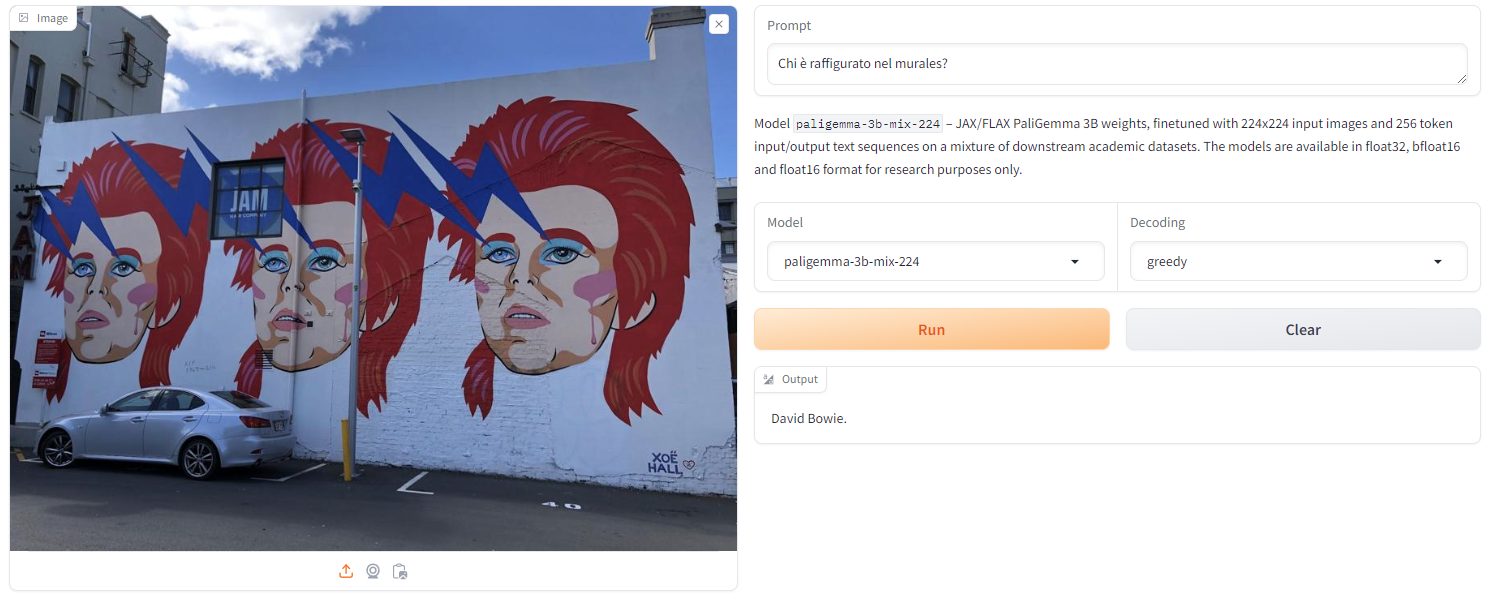
Attraverso i menu a tendina Model e Decoding, si possono scegliere diverse voci. Le opzioni “paligemma-3b-mix-224” e “paligemma-3b-mix-448” si riferiscono ai modelli PaliGemma preaddestrati su un mix di compiti e dimensioni specifiche di immagine. Il primo è ottimizzato per l’elaborazione di immagini di dimensioni più contenute ed è progettato per essere più leggero in termini di requisiti di memoria. L’altro, invece, offre il supporto per risoluzioni maggiori e può rivelersi più adatto per tutte quelle applicazioni che richiedono l’esame di dettagli più fini.
Quanto alle opzioni di decodifica – greedy, nucleus(0.1), nucleus(0.3), temperature(0.5) – queste riguardano il processo di generazione del testo da parte del modello. La scelta greedy indica che il modello selezionerà sempre la parola più probabile come token successivo durante la generazione del testo. È una strategia di decodifica semplice che però può portare a risultati meno diversificati. Ne parliamo nell’articolo su come funzionano gli LLM nel caso della greedy selection.
Viceversa, il nucleus sampling, noto anche come top-p sampling, seleziona i token attingendo all’insieme che supera un valore soglia predeterminato. Questo approccio consente una maggiore diversità nei risultati rispetto al greedy sampling. Infine, una temperature più elevata porta a introdurre maggiore creatività nel funzionamento del modello e un grado più elevato di aleatorietà nella generazione dell’output finale.
PaliGemma utilizzabile anche nelle proprie applicazioni: come fare con il codice Python
Utilizzando le istruzioni pubblicate al paragrafo How to run Inference, è possibile sfruttare i modelli PaliGemma all’interno delle proprie applicazioni servendosi ad esempio di semplice codice Python. Nello specifico, la classe PaliGemmaForConditionalGeneration permette di interagire con i modelli e ottenere risposte inviando l’immagine e il prompt da elaborare.
Di seguito un esempio di codice Python che si server del modello PaliGemma per generare testo a partire da prompt testuali e immagini. Prima di procedere, è necessario assicurarsi di aver installato le librerie necessarie, come transformers e torch.
import torch
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests# Carica il modello e il processore
model_id = “google/paligemma-3b-mix-224″
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)# Funzione per generare testo a partire da un prompt e un’immagine
def generate_text(prompt, image_url, max_tokens=50):
# Carica e pre-processa l’immagine
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = processor(prompt=prompt, images=image, return_tensors=”pt”)# Genera il testo
output = model.generate(**inputs, max_length=max_tokens)# Decodifica il testo
generated_text = processor.decode(output[0], skip_special_tokens=True)return generated_text
# Prompt e URL dell’immagine di esempio
prompt = “Descrivi quanto raffigurato in questa immagine”
image_url = “https://example.com/your-image.jpg”# Genera il testo a partire dal prompt e dall’immagine
generated_text = generate_text(prompt, image_url)# Visualizza il testo generato
print(“Testo generato:”, generated_text)
Al posto dell’URL indicato, va ovviamente specificato l’indirizzo dell’immagine che si desidera sottoporre ad elaborazione. Il codice Python provvede a caricare da Hugging Face il modello PaliGemma preaddestrato e genererà testo a partire dal prompt specificato e dall’immagine fornita.
/https://www.ilsoftware.it/app/uploads/2026/06/CAD-3D-AI-CADAM.jpg "CADAM: descrivi un oggetto e l'AI crea subito il modello CAD pronto per la stampa 3D")
/https://www.ilsoftware.it/app/uploads/2026/06/vulnerabilita-microsoft-copilot-sottrazione-dati-personali.jpg "Falla critica in Microsoft Copilot esponeva codici di autenticazione e dati aziendali")
/https://www.ilsoftware.it/app/uploads/2025/01/chatgpt-impatto-ambientale-consumo-acqua.jpg "Crollo utenti per ChatGPT? Gemini e Claude riducono il divario")
/https://www.ilsoftware.it/app/uploads/2026/06/chatgpt-claude-costi-modelli-AI.jpg "ChatGPT Pro da 200 dollari può costare a OpenAI molto più del previsto")