/https://www.ilsoftware.it/app/uploads/2026/01/file-poliglotta-multipiattaforma-windows-linux-browser.jpg "Un unico file da 13 KB funziona su Windows, Linux e browser Web: qual è il trucco geniale")
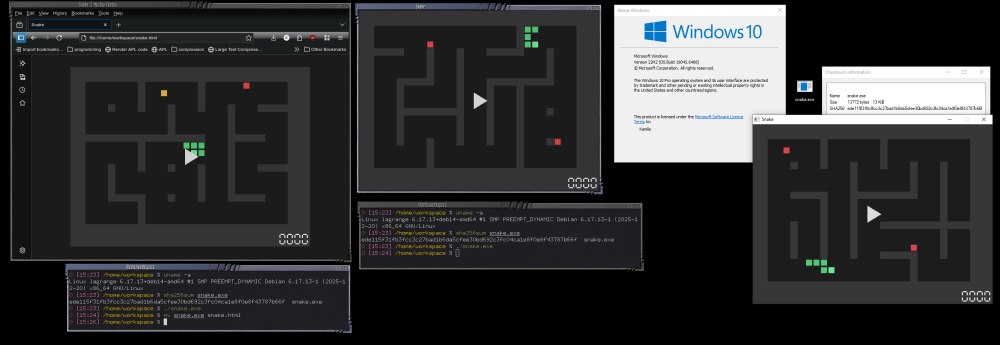
L’idea di comprimere un’applicazione in un singolo file capace di girare su più sistemi operativi non è nuova: progetti come Cosmopolitan, con il suo approccio “compile once, run native”, hanno reso popolare il concetto di binario multipiattaforma. Una sviluppatrice indipendente, Kamila Szewczyk, ha però voluto spostare il baricentro in un modo davvero ingegnoso: non si è limitata a “rendere portabile” un eseguibile, ma ha costruito un file poliglotta interpretato in tre modi diversi — Windows, Linux e browser — selezionando porzioni differenti dello stesso identico file.
Il risultato è un oggetto ibrido che non “contiene un solo programma”, bensì tre implementazioni parallele (C/WinAPI, C/X11, JavaScript/Canvas) impacchettate, unite fra loro e rese selettivamente visibili in base al loader che le incontra. La cosa davvero istruttiva ha a che fare con lo sfruttamento delle regole di parsing dei formati (PE, shell script, HTML) per far convivere più mondi (Windows, Linux, browser Web,…) nella stessa sequenza di byte.
Codice Windows e Linux convivono nello stesso file
Perché un file possa essere eseguito su Windows deve iniziare come un eseguibile PE, cioè con la firma MZ (marcatore iniziale che dice a Windows: “questo file è un eseguibile”) e una struttura minima coerente. Ciò non significa però che ogni byte iniziale sia interpretato o “capito” dal loader. In realtà, il caricatore di Windows usa solo alcune informazioni ben precise: controlla la firma, legge l’offset che punta al vero header PE\0\0 e, da lì in avanti, carica sezioni ed entry point. Tutto ciò che non è coinvolto direttamente in questo processo è di fatto ignorato.
Questa caratteristica crea uno spazio interessante: una zona del file che deve esistere per ragioni strutturali, ma che non ha un significato operativo per Windows. Si chiama DOS stub ed è oggi poco più di un relitto mantenuto per motivi di compatibilità. Finché i campi essenziali restano coerenti, il loader non si cura del contenuto reale di quei byte.
Aggiunta di uno script compatibile con la shell Unix
Invece di trattare quella porzione come semplice overhead, Szewczyk l’ha ripensata come qualcos’altro, sfruttando il fatto che un altro interprete — la shell Unix — la leggerà con regole completamente diverse. Per Windows quei byte sono rumore innocuo; per la shell sono testo, quindi potenzialmente codice valido.
La shell Unix, infatti, non conosce né PE né MZ: legge il file come una sequenza di caratteri e cerca solo costrutti sintatticamente accettabili. Se l’inizio del file è costruito con attenzione, può essere interpretato come uno script. In pratica, la shell è furbescamente istruita a ignorare l’inizio del file (che per Windows è fondamentale) e a lavorare solo su una porzione successiva.
Il risultato è un incastro perfetto di due comportamenti opposti ma compatibili: Windows ignora semanticamente ciò che serve alla shell, mentre la shell ignora semanticamente ciò che serve a Windows. Nessuno dei due ambienti “capisce” l’altro, spiega Szewczyk, e proprio questa ignoranza reciproca rende possibile la coesistenza nello stesso identico flusso di byte.
Linux: uno shell script che “salta” la parte Windows e ricava l’ELF
Come spiegato al precedente paragrafo, Szewczyk ha costruito ad arte un unico file che in apertura contiene l’header PE.
La parte interpretata dalla shell Unix è progettata per non eseguire il file così com’è, ma per usarlo come sorgente di dati. Lo script legge il proprio contenuto ($0) e sa già quali porzioni ignorare e quali invece estrarre. L’inizio del file è scartato perché contiene il PE destinato a Windows; subito dopo c’è un blocco compresso che, una volta isolato, rappresenta un vero ELF64.
ELF64 è il formato standard degli eseguibili a 64 bit su Linux e sistemi Unix-like. ELF sta per Executable and Linkable Format e definisce come un programma binario deve essere organizzato: header, sezioni, segmenti, simboli e punto di ingresso. Nel caso di Linux, ELF64 svolge lo stesso ruolo che il formato PE ricopre per Windows: è il contenitore che il loader del sistema operativo riconosce e carica in memoria per avviare un programma.
Quello che fa la shell è quindi molto semplice: ritaglia una finestra di byte, la decomprime (ad esempio con LZMA), scrive il risultato in una posizione temporanea, lo marca come eseguibile, lo avvia e poi cancella tutto. È un auto-extractor minimale, scritto in poche righe.
Browser: tutto ciò che precede <html> è spazzatura
Per rendere il file compatibile anche con i browser Web, Szewczyk è partita da un dato empirico: i browser, quando ricevono un documento che contiene HTML, tendono a ignorare byte e testo prima del tag di apertura. Se nel file, a un certo offset, compare un <html>, la parte precedente diventa un preambolo inutile, seppur tollerato.
Da lì in poi, CSS e layout possono persino mascherare gli effetti collaterali del “garbage” iniziale (margini, padding, rendering di elementi non desiderati). Quanto contenuto nel tag <html> è alla fine ciò che il browser considera davvero.
Il gioco Snake diventa multipiattaforma e sta in soli 13 KB
Per dimostrare l’efficacia del suo lavoro, Szewczyk ha sviluppato una versione multipiattaforma del celeberrimo gioco Snake: il codice che la sviluppatrice ha pubblicato permette di comprendere il comportamento del file poliglotta su Windows, Linux e browser.
Non solo. A metà pagina è presente il link al file snake.com che permette di avviare il gioco sulle tre piattaforme citate, sfruttando proprio i principi descritti sommariamente in precedenza. Inutile dire che alcuni motori antimalware bollano il file come insicuro: si tratta di falsi positivi. Ciò è semplicemente dovuto alla struttura anomala del file.
In chiusura, va detto che come esercizio tecnico creare un file poliglotta è qualcosa di davvero brillante: aiuta a comprendere il funzionamento di PE, ELF, shell semantics e parsing HTML. Come modello da usare in produzione, quasi sempre è una cattiva idea: manutenzione difficile, debug complesso e soprattutto un profilo di rischio reputazionale e operativo enorme. Il motivo? Lo spieghiamo al paragrafo successivo.
Ambiguità strutturale: perché un binario poliglotta è un rischio operativo
Come rilevato in precedenza, un approccio come quello descritto è un caso studio prezioso perché mostra quanto la sicurezza dipenda non solo dal codice, ma anche dai confini tra “cosa è valido” e “cosa viene ignorato” dai vari sistemi. Tuttavia, un file poliglotta manda in crisi le assunzioni di base su cui si reggono sviluppo, sicurezza e operazioni.
Dal punto di vista reputazionale, distribuire un file che può essere interpretato come eseguibile Windows, script Linux e pagina Web contemporaneamente assomiglia molto a tecniche tipiche del malware. Anche se l’intento è legittimo, strumenti di sicurezza, analisti e team di compliance lo vedranno come qualcosa di deliberatamente ambiguo. Il rischio è di finire segnalati, bloccati o associati a pratiche opache, con un impatto diretto sulla fiducia di utenti, clienti e partner.
Sul piano operativo, il debug diventa enormemente più complesso: ogni aggiornamento diventa fragile tanto che una modifica fatta per una piattaforma può rompere silenziosamente le altre.
C’è poi l’aspetto security e compliance. Molte pipeline CI/CD, sistemi di scansione e policy aziendali si basano sulla classificazione del tipo di file. Un oggetto software che sfugge a una categorizzazione chiara rischia di essere bloccato a valle, o peggio, di superare controlli non progettati per gestire questi tipi di file.
/https://www.ilsoftware.it/app/uploads/2026/03/novita-windows-12-2026.jpg "Windows 12 cambia tutto: AI integrata, nuovi requisiti hardware e lancio previsto nel 2026")
/https://www.ilsoftware.it/app/uploads/2026/03/blocco-login-windows-11-spazio-disco-esaurito.jpg "Windows 11 bloccato: quando il disco pieno impedisce il login")
/https://www.ilsoftware.it/app/uploads/2026/03/connessione-rete-internet-windows-11-non-funziona.jpg "Windows 11 25H2 e 24H2 continuano a “cancellare Internet”: esiste un solo modo per risolvere")
/https://www.ilsoftware.it/app/uploads/2026/03/condivisione-audio-windows-11-bluetooth.jpg "Windows 11 potenzia l’audio wireless: LE Audio e volumi separati")