/https://www.ilsoftware.it/app/uploads/2025/05/ollama-supporto-modelli-multimodali-AI.jpg "Ollama supporta i modelli AI multimodali: legge immagini, video ed estrae informazioni")
Un software come Ollama è spesso definito “runner” perché, nella sua implementazione tecnica, funge da esecutore di un ampio ventaglio di modelli linguistici o Large Language Models (LLM). Ollama è responsabile dell’esecuzione pratica del modello AI, gestendo le richieste e le risposte in modo fluido e continuo. Con l’introduzione del nuovo motore multimodale, Ollama segna un punto di svolta nella gestione e nell’esecuzione locale dei modelli generativi avanzati.
Con il nuovo aggiornamento, Ollama – che abbiamo imparato a installare e usare – consente il supporto nativo a modelli multimodali, aprendo le porte a capacità di comprensione e ragionamento su immagini e, in prospettiva, anche su audio, video e altre modalità. L’infrastruttura è progettata per garantire modularità, efficienza e coerenza con le specifiche di addestramento dei modelli più avanzati oggi disponibili.
Ollama, un motore progettato per il futuro della multimodalità nelle applicazioni di intelligenza artificiale
Fino a oggi, Ollama si è distinto per la facilità d’uso e la portabilità dei modelli, affidandosi principalmente al progetto open source llama.cpp. Con il crescente rilascio di modelli multimodali da parte di giganti come Meta, Google, Alibaba e Mistral, era necessario un approccio nuovo, scalabile e più aderente alla complessità delle architetture moderne.
Così, il nuovo motore alla base del funzionamento di Ollama introduce il supporto per encoder visivi e decoder testuali integrati in ogni modello. Inoltre, la gestione dei dati e la differenziazione tra immagini e testo è svolta all’interno di ogni modello, evitando soluzioni generiche che potrebbero causare errori o conflitti tra modelli diversi.
Ollama introduce ottimizzazioni avanzate per gestire il meccanismo di “attenzione” del modello, ad esempio il modo con cui dà priorità alle informazioni (attenzione causale), come tiene conto della posizione dei dati e come divide i dati in blocchi per gestire meglio la memoria.
Le immagini sono memorizzate temporaneamente in cache per velocizzare le risposte successive; la gestione della memoria è dinamica, cioè si adatta al computer in uso per ottenere le migliori prestazioni.

Modelli supportati: visione, ragionamento e interazione multimodale
In questa prima fase, iniziata a metà maggio 2025, Ollama include il supporto per il seguenti modelli multimodali:
- Meta LLaMA 4 Scout – modello Mixture-of-Experts con 109 miliardi di parametri, progettato per comprensione avanzata di immagini e ragionamento su contesti visivi.
- Google Gemma 3 – abilitato per domande su sequenze di immagini, correlazione semantica e attenzione su finestre scorrevoli.
- Qwen 2.5 VL – modello per OCR, traduzione automatica di testi, comprensione e contestualizzazione semantica.
- Mistral Small 3.1 – focalizzato su performance multimodale ottimizzata per hardware localizzato.
In pratica, avvalendosi di Ollama e di LLaMA 4 Scout è ora possibile interagire direttamente con le immagini per ottenere una serie di informazioni. Ad esempio, descrizioni dettagliate del contenuto visivo, analisi geografica e domande local-based (i.e. distanza tra luoghi), consigli di viaggio e valutazioni contestuali.
Con Gemma 3, invece, l’utente può analizzare più immagini simultaneamente, determinando relazioni comuni tra elementi visivi (esempio: “Quale animale appare in tutte le immagini?”) e anche porre domande su interazioni impossibili nel mondo reale (“Chi vincerebbe un incontro di boxe tra un alpaca e una balena?”).
Con Qwen 2.5 VL si entra invece nel campo dell’OCR avanzato e della localizzazione semantica del testo in documenti complessi.
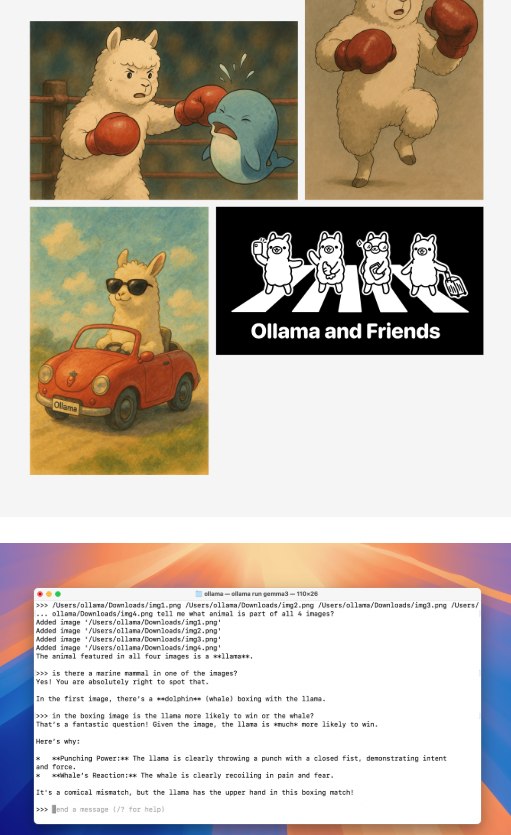
Come usare i modelli multimodali con Ollama
Usare i modelli multimodali con Ollama è semplice, proprio grazie al nuovo motore che supporta nativamente immagini e testo.
Supponendo di voler utilizzare LLaMA 4 Scout, basta digitare quanto segue in corrispondenza della riga di comando (dopo aver installato Ollama sul proprio sistema):
ollama run llama4:scout
Dopo l’avvenuto caricamento, si può indicare il percorso di un’immagine e porre una domanda, ad esempio “Che cosa vedi in quest’immagine?”. Il modello analizzerà il contenuto visivo e risponderà usando il linguaggio naturale.
Maggiori informazioni sono reperibili in questo post di presentazione delle nuove funzionalità di Ollama.
/https://www.ilsoftware.it/app/uploads/2026/03/revisione-codice-kernel-linux-sashiko-google.jpg "Con Sashiko, Google porta l’AI nella revisione del kernel Linux")
/https://www.ilsoftware.it/app/uploads/2025/02/gemini-code-assist-sviluppo-codice-vs-code-2.jpg "Google migliora Gemini introducendo delle nuove schede")
/https://www.ilsoftware.it/app/uploads/2026/03/windows-11-copilot-meno-protagonista.jpg "Microsoft frena su Copilot in Windows 11: cambia la strategia AI")
/https://www.ilsoftware.it/app/uploads/2024/01/intelligenza-artificiale-applicazioni-ollama-librerie.jpg "Fi Intelligence: un nuovo chatbot AI per monitorare la salute dei cani")