/https://www.ilsoftware.it/app/uploads/2023/05/img_23268.jpg "Fingerprinting: cos'è e come funziona il riconoscimento degli utenti")
Quando si naviga sul Web la consultazione di un qualunque sito o l’utilizzo di un’applicazione si basa su tante interazioni tra il client (in particolare il browser che si sta usando come Chrome, Edge, Firefox,…) e il server remoto.
Ogni richiesta include l’indirizzo IP pubblico dell’utente (il server remoto deve sapere dove inviare le risposte) ma le informazioni condivise sono molte di più.
Il fingerprinting è un approccio sofisticato che permette di identificare un utente tra miliardi di altre persone. Si tratta di una tecnica evoluta per raccogliere informazioni sui visitatori di un sito Web o su altri utenti online.
Il fingerprinting utilizza diverse informazioni per creare un’impronta digitale del dispositivo utilizzato da ciascun utente per accedere al sito Web, tra cui la versione del browser, sistema operativo, risoluzione dello schermo, lingue abilitate, plugin installati, font disponibili e altre caratteristiche tecniche del dispositivo client. L’ID univoco generato a partire da questi parametri può essere utilizzato per riconoscere uno stesso utente, da una sessione all’altra, senza neppure scomodare l’utilizzo dei cookie.
Le informazioni trasmesse dal browser al sito Web
La compatibilità tra client e server Web non è più un problema al giorno d’oggi ma andando un po’ indietro nel tempo i siti dovevano necessariamente adattare le loro risposte al browser richiedente magari inviando una pagina diversa a Netscape Navigator e un’altra a Internet Explorer.
Nella richiesta che il browser invia al server remoto ci sono informazioni che lo identificano: il programma usato per “navigare” sul Web non solo si qualifica al server remoto ma trasmette informazioni precise sul numero di versione oltre che sul numero di build e sistema operativo utilizzato.
La stringa che viene trasmessa dal browser e che fornisce un quadro piuttosto preciso della configurazione software utilizzata lato client si chiama user agent.
Per leggere qual è il proprio user agent per ciascun browser installato basta visitare Google quindi incollare my user agent nella casella di ricerca.
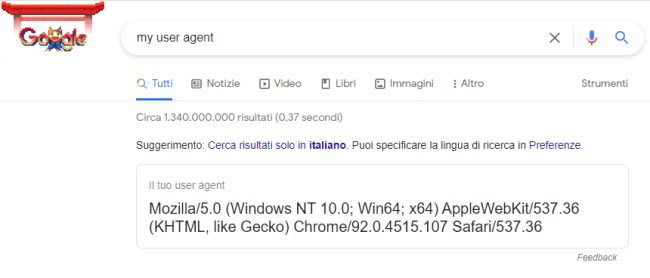
Google intende abbandonare il supporto della stringa user agent con Chrome: è qualcosa che avverrà in futuro e che non metterà certamente fine alla pratica del fingerprinting. Il perché sarà più chiaro nel seguito.
Per assicurarsi che una pagina Web venga correttamente visualizzata, il browser ha bisogno di accedere ai font giusti. Quali font sono disponibili lato client dipende dal sistema operativo e talvolta anche dalle preferenze dell’utente.
Il browser interroga il sistema operativo per ricevere la lista dei font presenti quindi la trasmette al server remoto. Se manca un font essenziale, infatti, il sito potrebbe scegliere di visualizzare una pagina semplificata.
Quando si installa Windows o un altro sistema operativo tutti gli utenti hanno lo stesso insieme di font; con l’installazione di altri programmi spesso vengono aggiunti nuovi font, non rimossi con le procedure di disinstallazione. Sono tanti, inoltre, i servizi che permettono di ottenere caratteri gratis da usare in Windows e nelle applicazioni installate.
Così, dopo un po’, le collezioni di font presenti sul sistema iniziano a divergere e non sono più identiche tra un utente e l’altro.
Canvas è il nome di un’API HTML5 che viene utilizzata per disegnare grafica e animazioni su una pagina web tramite JavaScript.
Utilizzando la tecnica del canvas fingerprinting un server remoto può identificare uno stesso utente partendo dal presupposto che la stessa immagine canvas può essere resa in modo diverso su diversi dispositivi.
Ciò accade per diverse ragioni. A livello di formato dell’immagine i browser web usano vari motori di elaborazione, rendering delle immagini e compressione delle immagini. Così le immagini finali utilizzate nelle pagine Web possono avere checksum diversi anche se identiche in termini di pixel.
I server che si occupano di erogare ciascun sito Web possono inoltre interrogare e ricevere imponenti quantità di informazioni sulle impostazioni e la configurazione di ciascun dispositivo client.
Tale enorme mole di informazioni può essere condensata formando un unico valore alfanumerico che identifica univocamente uno stesso dispositivo client: si tratta di un’impronta digitale del sistema in uso tanto che questo meccanismo è stato appunto battezzato fingerprinting, come anticipato nell’introduzione.
I parametri sulla configurazione del browser e del sistema operativo che possono essere richiesti da un server remoto sono talmente tanti da rendere bassa o addirittura nulla la probabilità che due client in tutto il mondo abbiamo la stessa impronta digitale.
Ogni pagina Web è composta da codici HTML e JavaScript che possono richiamare non soltanto risorse erogate dallo stesso server ma anche da altri server remoti, gestiti da soggetti completamente diversi tra loro.
Visitando il sito X, quindi, soggetti A, B, C, D, E e così via, completamente svincolati da X per tipologia e struttura aziendale, giurisdizione, modalità di business sono nelle condizioni di raccogliere informazioni dai client degli utenti collegati con il sito X.
E ciò semplicemente perché il sito X contiene codice fornito dai soggetti A, B, C, D, E…
Troppa attenzione sui cookie, poca sulle tecniche di fingerprinting
Il legislatore europeo ha posto grande enfasi sugli adempimenti in capo agli editori di siti Web che sono tenuti ad acquisire il consenso degli utenti prima di impiantare cookie di tracciamento propri o di terze parti.
I cookie esistono praticamente da quando esistono i browser. Lo scopo di un cookie è quello di permettere a un sito Web di ricordare qualcosa sull’utente o sul suo dispositivo senza mantenere tali informazioni in un database lato server.
Ogni cookie è infatti un semplice file di testo che “vive” sul dispositivo client dell’utente, non sul server remoto. Ciascun sito può salvare delle informazioni nel cookie: dati che permettono di riconoscere subito l’utente nel corso delle visite successive senza che debba di nuovo autenticarsi, quale pagina si stava leggendo durante la consultazione di un documento online durante la precedenza sessione di lavoro, una lista di oggetti acquistati e tanto altro ancora.
Visitando lo stesso sito in una sessione successiva, questo può leggere il proprio cookie (ma non quelli altri siti) e utilizzare le informazioni ivi registrate.
In un altro articolo abbiamo spiegato brevemente cos’è la sessione nella “navigazione” sul Web.
È ovvio che se il codice dei soggetti A, B, C, D, E è pubblicato sul sito X, su Y, Z, W e su centinaia di altri, A, B, C, D, E possono creare un unico cookie e sapere, ad esempio, quali siti ha visitato un utente, quando, quali pagine ha consultato, quali argomenti hanno raccolto maggiore interesse e così via.
Inserendo nel cookie un identificativo univoco, soggetti come A, B, C, D, E possono tracciare un utente – o meglio tutte le visite effettuate dallo stesso dispositivo – creando una sorta di identikit su interessi e preferenze.
Le tecniche di tracciamento degli utenti basate sui cookie implicano la creazione di un elemento lato client tanto che dal 2009 si iniziò a parlare dell’aggiunta dell’header “Dot Not Track” con Firefox, nel 2011, che fu il browser ad abbracciarne l’utilizzo.
A ogni richiesta inviata ai server remoti era possibile (lo è ancora oggi) inviare il messaggio “Do Not Track” esortando l’altra parte a non porre in campo alcun meccanismo di tracciamento.
Il meccanismo non ha avuto successo perché i siti erano e sono liberi di ignorare l’header “Do Not Track“.
Le Autorità europee hanno quindi prescritto ai gestori di siti Web l’esposizione di un’adeguata informativa al momento della prima visita per chiarificare i trattamenti di dati che vengono posti in essere. Gli editori devono astenersi dal generare lato client qualunque cookie tracciante se non dopo aver raccolto il consenso di ciascun utente.
Il fatto è che mentre i cookie possono essere eliminati, ad esempio anche configurando il browser perché li elimini alla fine di ogni sessione di navigazione, il fingerprinting è una modalità di tracciamento molto più subdola che si sottrae al controllo degli utenti.
Perché il fingerprinting è diverso dai cookie ed è molto più potente
Rispetto all’uso dei cookie le tecniche di fingerprinting sono completamente diverse: nulla viene creato sul dispositivo client, nemmeno un semplice file di testo. Il fingerprinting si limita infatti a sfruttare le normali funzioni del browser che abbiamo citato in apertura.
Nel momento in cui scriviamo la pratica del fingerprinting è legale sebbene il Regolamento dell’Unione europea (GDPR) imponga alle aziende di raccogliere il consenso dell’utente esattamente come avviene nel caso dei cookie.
Mentre però se nel caso dei cookie è facile stanare chi non si comporta correttamente (basta ad esempio accedere agli Strumenti per gli sviluppatori del browser e verificare quali cookie vengono eventualmente erogati alla prima visita) la pratica del fingerprinting può passare ampiamente inosservata.
Le tecniche utilizzate abitualmente come l’utilizzo della modalità di navigazione in incognito (non consente di modificare l’indirizzo IP ma permette di evitare l’accesso a cookie precedentemente memorizzati sul sistema), di un client VPN, la cancellazione di cookie e cronologia non consentono di prevenire il fingerprinting.
Il sito Device Info mostra quali e quante informazioni i server remoti possono richiedere a ciascun browser per generare un identificativo univoco del client.
Combinando tutti i dati raccolti, un server remoto può riconoscere lo stesso utente (o meglio, il suo dispositivo) indipendentemente dal fatto che venga attivata una VPN, abilitata la navigazione in incognito, cancellata la cronologia, chiuso e riaperto il browser.
Alcuni browser, come Firefox, hanno iniziato da qualche tempo a integrare strumenti anti fingerprinting ma già nel 2018 ricerche indipendenti dimostravano come si tratti di soluzioni poco efficaci nel proteggere gli utenti contro il fingerprinting.
Il concetto di entropia è una misura di quanto un dato incida nel processo che definisce l’identità di un individuo.
Nel caso dei browser Web l’entropia suggerisce quanto ciascuna informazione utilizzata durante il processo di fingerprinting contribuisca a rendere identificabile o meno un utente. Maggiore è il valore dell’entropia, minore la possibilità di essere identificati univocamente.
Ovvio che se ad esempio si installano font poco comuni o si aggiungono estensioni l’entropia scende drasticamente e il fingerprinting risulta ancora più efficace.
Un test per verificare come funziona il fingerprinting
Electronic Frontier Foundation (EFF) pubblica e aggiorna un test chiamato Cover Your Tracks che permette di verificare quanto siano univoche le informazioni rivelate a terzi dal browser in uso (quindi effettivamente utilizzabili per il fingerprinting e per la generazione di un ID unico).
Ci preme però guardare dall’altra parte della “barricata”: FingerprintJS è una soluzione che viene proposta ai gestori di siti Web interessati a usare la tecnica del fingerprinting per prevenire frodi e attività inammissibili sulla base delle normative vigenti, delle condizioni di licenza e/o dei termini del servizio.
FingerprintJS consente di capire se un utente “sta barando” presentandosi ad esempio come se fosse un nuovo soggetto quando invece sta utilizzando una VPN, la modalità in incognito o altre tecniche di “mascheramento”.
Visitate questa pagina quindi annotate quanto mostrato in corrispondenza di Your ID.
Provate quindi ad aprire una finestra di navigazione in incognito e visitate lo stesso indirizzo: incredibilmente la stringa identificativa mostrata accanto a Your ID sarà la stessa.
Si tratta della conferma che il servizio è riuscito a identificare univocamente lo stesso client a dispetto dell’uso della navigazione in incognito e servendosi dei soli dati restituiti dal browser.
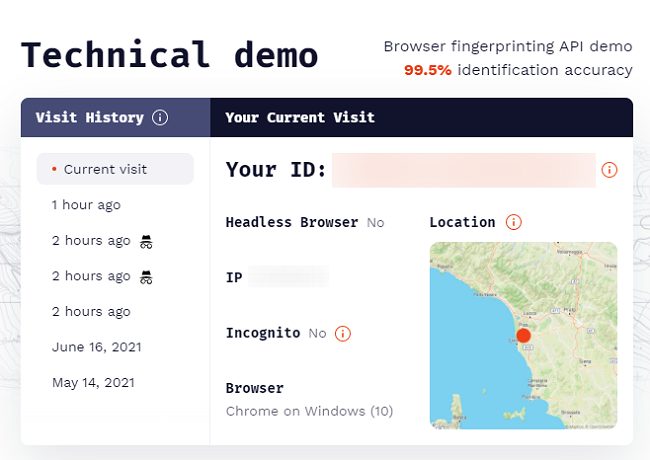
Provate adesso a collegarvi con un server VPN quindi aprite anche una finestra di navigazione in incognito: sempre senza usare alcun cookie e a dispetto della modifica dell’indirizzo IP pubblico, FingerprintJS riuscirà di nuovo a identificare univocamente lo stesso utente.
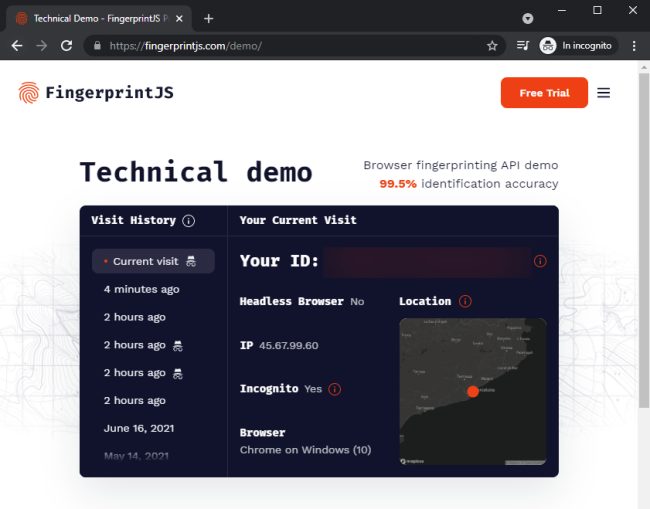
Una parziale soluzione consiste nell’utilizzo di Tor Browser appositamente pensato per preservare privacy e anonimato degli utenti.
Nella guida su Tor Browser abbiamo spiegato nel dettaglio il funzionamento del programma.
C’è però un’importante area grigia della quale riteniamo sia opportuno parlare.
Provate a installare l’ultima versione di Tor Browser e a visitare la pagina di verifica di FingerprintJS vista in precedenza. L’ID sarà diverso rispetto a quello visualizzato dal browser Web preferito ma aprendo una nuova scheda in Tor Browser e visitando di nuovo FingerprintJS verrà mostrata sempre la stessa stringa in corrispondenza di Your ID.
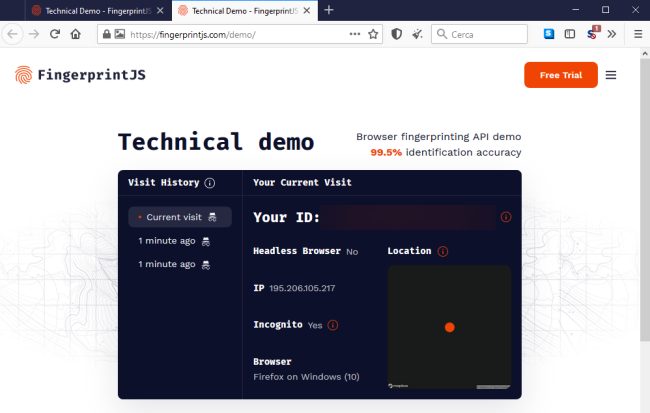
La stessa stringa identificativa viene insomma comunque mostrata anche passando da onion router completamente differenti.
Cosa significa tutto questo? Che FingerprintJS in configurazione “Sicuro” è in grado di riconoscere lo stesso utente che sta utilizzando Tor Browser e che visita più siti in diverse schede contemporaneamente aperte.
La buona notizia nel caso di Tor Browser è che chiudendo e riaprendo il browser l’utente non viene più riconosciuto.
Firefox integra un’impostazione chiamata resistFingerprinting (inizialmente fornita da The Tor Project) che lo rende più resistente al fingerprinting.
Quando attivata Firefox tenta di mascherare determinate proprietà rilasciate del browser rendendole uniformi per tutti gli utenti.
È possibile abilitarla digitando about:config nella barra degli indirizzi, scrivendo privacy.resistFingerprinting nella casella Cerca nome preferenza e cliccando due volte sullo stesso parametro in modo da impostarlo a true.
FingerprintJS viene presentato come progetto open source utilizzabile da parte di tutti gli interessati.
La versione open source, però, non riconosce ad esempio lo stesso utente che apre più schede con Tor Browser (mostra ID diversi) ma è perfettamente in grado di generare lo stesso identificativo se l’utente naviga normalmente e poi apre una finestra di navigazione in incognito (vedere la pagina di test anche per verificare i parametri utilizzati per la generazione dell’impronta digitale).
La versione di FingerprintJS disponibile in-cloud è tuttavia molto più precisa tanto da riconoscere univocamente l’utente nel 99,5% dei casi.
Sì, l’impronta digitale può cambiare in base alle modifiche apportate dall’utente al sistema ma ciò non accade spesso e quando succede non è nemmeno così importante. A chi utilizza meccanismi di tracciamento non interessa perdere temporaneamente le tracce di qualche utente. Finché possono rintracciare la maggior parte degli utenti, non c’è assolutamente alcun problema. Soprattutto se possono farlo senza ricorrere ai cookie.
Emblematico ciò che scrive FingerprintJS parlando di GDPR-complaining: “la nostra tecnologia è destinata ad essere utilizzata solo per il rilevamento delle frodi; per questo caso d’uso, non è richiesto il consenso dell’utente. Qualsiasi uso al di fuori del rilevamento delle frodi dovrebbe essere conforme alle regole di raccolta del consenso dell’utente previste dal GDPR; non tracciamo mai automaticamente il traffico, i nostri clienti possono configurare in quali condizioni i visitatori vengono tracciati; non facciamo mai tracking cross-domain“.
/https://www.ilsoftware.it/app/uploads/2025/07/wp_drafter_482766.jpg "OpenAI si prepara a lanciare un nuovo browser per sfidare Google Chrome")
/https://www.ilsoftware.it/app/uploads/2025/02/ILSOFTWARE-2.jpg "Microsoft Edge sarà più veloce nei caricamenti delle pagine web")
/https://www.ilsoftware.it/app/uploads/2025/07/estensioni-edge-ios-iphone.jpg "Microsoft Edge per iOS apre alle estensioni: come attivare la funzionalità nascosta")
/https://www.ilsoftware.it/app/uploads/2025/02/mozilla-firefox-ESR-windows-7.jpg "Mozilla lancia Wasm Agents: l'AI direttamente nel browser")