/https://www.ilsoftware.it/app/uploads/2026/05/25-anni-ilsoftware-it-evoluzione-tecnologia-digitale.jpg "IlSoftware.it compie 25 anni: dal modem 56k all'AI, tutto quello che è cambiato")
“Cu cu! Eravamo felici e non lo sapevamo“. Un’uscita scherzosa in una discussione interna tra colleghi fotografa perfettamente una sensazione che accomuna chi ha vissuto davvero l’informatica degli anni ’90 e dei primi 2000: il mondo digitale era più complicato, più lento, più fragile… ma anche tremendamente aperto alla sperimentazione.
Quando nel maggio 2001, 25 anni fa, nasceva IlSoftware.it, Internet era una rete molto diversa da quella attuale. Era composta da siti indipendenti, forum, server IRC, FTP pubblici, portali, newsgroup Usenet e comunità tecniche. Oggi il panorama è profondamente cambiato: cloud, smartphone e piattaforme globali hanno semplificato enormemente l’accesso alla tecnologia, rendendo possibili servizi che nel 2001 erano inimmaginabili: streaming in tempo rale, collaborazione globale, sincronizzazione continua, infrastrutture elastiche, AI generativa.
Allo stesso tempo, però, negli ultimi anni si è rafforzata anche una spinta opposta: quella verso decentralizzazione, interoperabilità e sovranità digitale. Non è un caso se stanno tornando centrali temi come self-hosting, federazione, controllo dei dati e indipendenza dalle grandi piattaforme.
È forse proprio questo uno degli aspetti più affascinanti degli ultimi 25 anni: ogni fase tecnologica sembra superare completamente la precedente, salvo poi recuperare – in forme nuove – molte delle idee da cui tutto era partito.
Anno 2001: com’erano i PC e le connessioni Internet
Per capire davvero cosa significhi “25 anni di informatica” bisogna ricordare com’era usare un PC nel 2001. Windows XP uscì proprio il 25 ottobre di quell’anno: tra i sistemi più diffusi all’epoca c’era Windows 98, mentre gli utenti più esperti utilizzavano Windows 2000 Professional.

I PC domestici tipici montavano processori Intel Pentium III tra 800 MHz e 1 GHz, AMD Athlon Thunderbird, 128 o 256 MB di RAM SDRAM, hard disk IDE da 20-40 GB, schede video NVIDIA GeForce 2 MX oppure ATI Radeon DDR. masterizzatori CD-RW 8x/4x/32x, modem 56k oppure ISDN. La banda larga era ancora “merce rara” nel nostro Paese.

In Italia molti utenti usavano ancora connessioni Internet analogiche V.90 o V.92, standard che permettevano di collegarsi alla rete tramite la normale linea telefonica. Durante la connessione il modem occupava completamente la linea e generava il caratteristico suono di handshake, cioè la sequenza di toni usata dai dispositivi per sincronizzarsi e avviare la comunicazione, oggi considerata quasi una testimonianza dell’archeologia digitale.
In realtà TIM ha mandato in pensione le connessioni analogiche 56k soltanto nel 2023 e c’è chi ancora si è divertito, nel 2026, a creare un Internet Service Provider con Raspberry Pi e supporto dial-up.
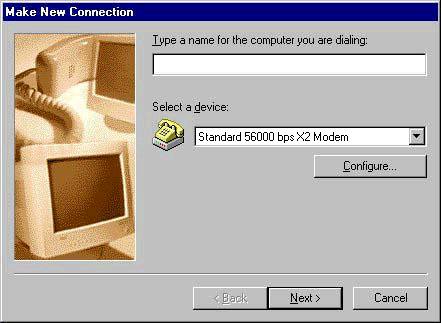
Nel 2001 c’era una ricerca spasmodica, almeno “tra gli addetti ai lavori” di offerte flat per evitare di pagare le connessioni Internet a tempo. Telecom Italia iniziava lentamente a distribuire Alice ADSL nelle grandi città, spesso con velocità da 256 Kbps o 640 Kbps, numeri che oggi fanno sorridere ma che all’epoca rappresentavano qualcosa di rivoluzionario rispetto alla “banda stretta” da 3-5 Kbps.

Driver, IRQ, DMA: l’informatica “fisica”
Oggi colleghi una periferica USB e tutto va per il verso giusto. Nel 2001 non era affatto scontato.
Le schede audio Sound Blaster potevano entrare in conflitto con modem interni PCI; le periferiche utilizzavano gli stessi IRQ, cioè le linee di interrupt usate dall’hardware per comunicare con il sistema operativo, provocando blocchi del computer e schermate blu di errore. I masterizzatori IDE richiedevano configurazioni master/slave selezionate tramite jumper fisici. Le schede madri usavano BIOS Award o AMI da configurare manualmente.

Motherboard con Slot 1 – Asus P3C2000 (foto: © Raimond Spekking / CC BY-SA 4.0)
Bisognava mettere mano a impostazioni come la frequenza del Front Side Bus (FSB), che regolava la velocità di comunicazione tra processore e scheda madre, i timing della RAM, cioè i parametri che influenzavano le prestazioni della memoria, sull’AGP Aperture Size, utilizzata per gestire la memoria dedicata alle schede video AGP, sul DMA Ultra ATA per velocizzare il trasferimento dei dati tra disco e sistema, sulla gestione ACPI per il controllo del risparmio energetico.
IlSoftware.it nacque esattamente in questo contesto tecnico.
È vero che alcune di queste operazioni si eseguono ancora oggi, anche nel 2026, come la configurazione della sequenza di avvio, la gestione delle partizioni sulle unità di memorizzazione e, in ambito avanzato, la regolazione delle frequenze della RAM e di alcuni parametri hardware tramite UEFI o BIOS. Tante altre impostazioni, tuttavia, appartengono ormai a tecnologie superate e sono state sostituite da standard più moderni e quasi completamente automatizzati.

Configurazione master/slave IDE nel 2001 (credit)
Quando Internet Explorer dominava il Web
Nel 2001 Internet Explorer 6 stava per conquistare il monopolio assoluto del browser market. Netscape era praticamente al collasso e Firefox sarebbe arrivato soltanto anni dopo, a partire dal novembre 2005. Prima, comunque, noi come moltissimi altri usavamo Phoenix e Firebird (dal settembre 2002 in avanti), gli antesignani di Firefox.
Il Web era ancora fortemente basato su HTML statico, tabelle, frame, CGI, applet Java e tecnologie ormai abbondantemente accantonate come Flash e ActiveX. Questi ultimi apparivano sia come strumenti per rendere più dinamiche le pagine, sia – come si scoprì molto rapidamente – un enorme problema di sicurezza.
Molte applicazioni bancarie, gestionali e pubbliche italiane richiedevano Internet Explorer, controlli ActiveX, Java Runtime Environment, plugin proprietari. Oggi un’architettura simile sarebbe considerata estremamente vulnerabile.
Ed è proprio in quel periodo che IlSoftware.it iniziava a seguire in profondità le problematiche legate alla sicurezza informatica, prima ancora che si iniziasse a usare il termine cybersecurity per riferirsi non soltanto alla protezione dei sistemi ma anche a quella delle persone, degli account, delle identità digitali.
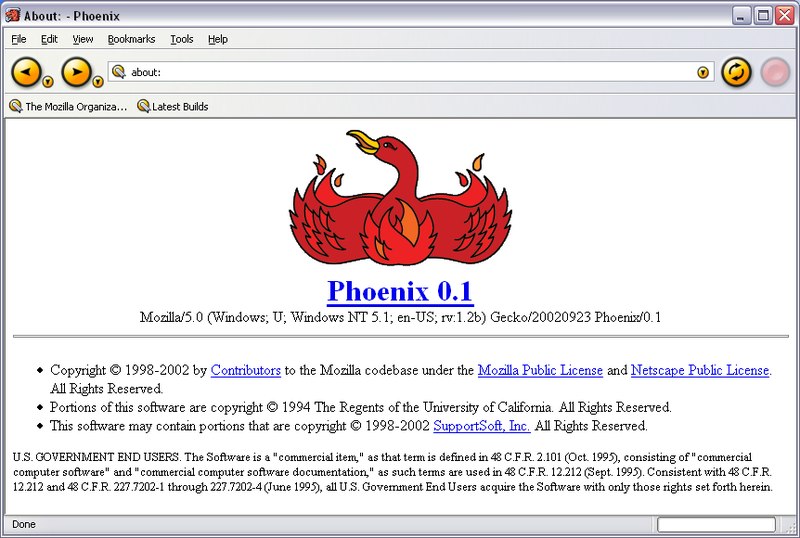
Fonte dell’immagine: Mozilla Corporation
Worm, exploit e firewall: quando Internet diventò ostile
Tra il 2001 e il 2005 la rete cambiò radicalmente. I worm Code Red (2001), SQL Slammer (2003), Blaster (2003), Sasser (2004) e Mydoom (2004) mostrarono per la prima volta cosa significasse un’infrastruttura Internet globale vulnerabile.
Questi malware si diffondevano automaticamente sfruttando falle di sicurezza nei sistemi Windows o nei servizi esposti su Internet, senza richiedere alcuna azione da parte dell’utente: alcuni riuscivano a propagarsi in pochi minuti, saturando reti e mandando in crisi server, aziende e infrastrutture pubbliche.
Colsero molti alla sprovvista perché, fino a quel momento, si sottovalutava la velocità con cui un attacco poteva diffondersi su scala mondiale e perché gran parte dei sistemi non veniva aggiornata regolarmente con le patch di sicurezza disponibili. A inizio degli anni 2000, inoltre, molti sistemi erano collegati alla rete con un semplice modem senza l’integrazione di funzionalità firewall efficaci. Chi non si era documentato abbastanza e non installava le patch rilasciate da Microsoft, ha visto i suoi sistemi personali automaticamente infettati. Nel caso di SQL Slammer bastarono circa 10 minuti per infettare decine di migliaia di server nel mondo.
Software come ZoneAlarm, Kerio Personal Firewall, Sygate, Norton Internet Security diventarono strumenti essenziali.
IlSoftware.it seguì quella fase con approfondimenti tecnici: ricordiamo ancora il suggerimento del tool Microsoft Baseline Security Analyzer per rendere sicuro Windows, dei consigli per creare file ISO contenenti tutte le patch di Windows perché Windows Update c’era, ma il funzionamento non era automatico come oggi. In quegli anni nasceva anche il concetto di patch management.
Molti utenti scaricavano patch manualmente dal Microsoft Download Center e le aziende iniziavano a gestire WSUS, deployment centralizzati e policy di sicurezza.
Oggi parliamo di ransomware-as-a-service, supply chain attack e vulnerabilità cloud-native. Ma le fondamenta della cybersecurity nascono esattamente in quel periodo.
L’epoca dei messenger: ICQ, IRC, MSN e la rete “sociale” prima dei social
Molto prima di WhatsApp, Telegram e Slack, la comunicazione online era un mosaico di strumenti completamente diversi. Ed è impossibile raccontare l’evoluzione dell’informatica senza parlare della messaggistica.
Chi c’era ricorda perfettamente IRC. mIRC rappresentava il cuore della “comunicazione nerd” italiana: server come Azzurra, ircnet e DalNet erano pieni di canali tematici. Bastava entrare in #italia oppure in community verticali dedicate a Linux, hacking, videogiochi o programmazione.
“Una bella room su mIRC”
“Tutti su #italia”
“Michele, mi oppi?”
Sono frammenti che oggi sembrano provenire da un’altra era informatica. IRC era qualcosa di completamente diverso dai social odierni: gli operatori di chat (“op”, da cui il termine italianizzato “oppare“) gestivano canali, ban e moderazione in modo manuale. Non esistevano algoritmi, feed o piattaforme centralizzate.
Portato al debutto nel 1996, c’era anche ICQ: per milioni di utenti il celebre suono “uh-oh!” diventò il simbolo della messaggistica istantanea. Quell’applicazione, ormai abbandonata, introdusse concetti oggi dati per scontati: presenza online, stato, lista contatti, messaggi diretti, trasferimento file, notifiche in tempo reale.
Molti italiani pionieri dell’informatica moderna ricordano ancora orgogliosamente, noi compresi, il proprio numero ICQ a 5 cifre.
![]()
Nel frattempo Microsoft lanciava MSN Messenger (la prima versione risale al luglio 1999): fu probabilmente il primo vero fenomeno di massa della messaggistica istantanea in Italia. I trilli, le emoticon personalizzate, i nickname colorati, i messaggi personali e le immagini dinamiche diventarono elementi culturali di un’intera generazione.
“Sarebbe bellissimo, oggi, un sacco di trilli al capo quando non risponde entro un ragionevole tempo di 14 secondi”.

In parallelo esistevano anche:
L’italianissimo C6 Messenger (nato in Atlantide.it, di proprietà di Tin.it, poi inglobato in Telecom Italia/Virgilio), Yahoo! Messenger, AIM (AOL Instant Messenger) e NetMeeting. Basti pensare che Skype sarebbe arrivato solo ad agosto 2003, chiuso a maggio 2025 dopo 22 anni di attività per lasciare spazio a Microsoft Teams.
Come funzionava la messaggistica 25 anni fa
All’epoca i protocolli di messaggistica erano relativamente aperti, federati o interoperabili. Oggi gran parte della comunicazione passa attraverso ecosistemi chiusi controllati da poche aziende.
D’altra parte, la messaggistica moderna è anche molto più complessa dal punto di vista tecnico: spesso (non sempre!…) utilizza la cifratura end-to-end per proteggere i messaggi in modo che possano essere letti solo dai partecipanti alla conversazione; la sincronizzazione cloud per mantenere chat e contenuti aggiornati su tutti i dispositivi; il supporto multi-device in tempo reale per usare lo stesso account contemporaneamente da smartphone, PC e tablet; infrastrutture VoIP distribuite per le chiamate vocali via Internet; notifiche push per ricevere avvisi immediati anche quando l’app non è aperta; meccanismi di federazione dell’identità per gestire autenticazione e accesso tra servizi differenti e integrazioni con sistemi di intelligenza artificiale per funzioni avanzate come suggerimenti, traduzioni e assistenza automatica.
Nel 2001 tutto questo non esisteva.
Linux: da sistema “per pochi” a infrastruttura del mondo digitale
Nel 2001 Linux era ancora percepito come un sistema operativo per appassionati, sistemisti e sviluppatori. Distribuzioni come Slackware, Debian, Red Hat Linux, Mandrake e SUSE richiedevano conoscenze tecniche approfondite.
Configurare l’ambiente grafico XFree86 significava spesso modificare manualmente file come XF86Config, impostare frequenze orizzontali e verticali del monitor, configurare modeline e sperare che la scheda video fosse supportata correttamente. Molte periferiche semplicemente non funzionavano.
I modem software (winmodem) erano un incubo ricorrente; le stampanti richiedevano configurazioni manuali tramite CUPS o Ghostscript; le schede WiFi necessitavano spesso di wrapper NDIS per utilizzare driver Windows sotto Linux.
Eppure, proprio in quegli anni, Linux iniziava lentamente a costruire le fondamenta della propria espansione globale tanto che oggi abbiamo dovuto sfatare tanti falsi miti su Linux.
Nel mondo server Apache dominava il Web: intere infrastrutture Internet iniziavano già a funzionare su stack LAMP (Linux, Apache, MySQL, PHP). Nel frattempo il desktop Linux viveva una fase pionieristica: KDE e GNOME stavano maturando rapidamente, OpenOffice iniziava a rappresentare un’alternativa concreta a Microsoft Office, Mozilla gettava le basi di quello che sarebbe poi diventato Firefox (lo abbiamo detto prima).
Progressivamente, Linux smise di essere “un sistema operativo alternativo” (nella sua forma GNU/Linux, a stretto rigore Linux è il kernel ma come abbiamo ripetuto non ha davvero più senso fare polemica su questo punto…) per diventare la piattaforma infrastrutturale dominante dell’intero ecosistema digitale. Oggi Linux gira praticamente ovunque: server cloud, hyperscaler, container Docker, Kubernetes, smartphone Android, smart TV, NAS, router, IoT, supercomputer, sistemi automotive, infrastrutture AI.
Perfino Microsoft, storicamente antagonista del mondo Linux, è diventata uno dei maggiori contributori al kernel attraverso Azure, WSL (con Windows Subsystem for Linux, Linux è integrato in Windows!!…) e l’integrazione cloud-native.
È cambiato anche il modo di amministrare Linux
Nel 2001 la gestione di sistemi Linux avveniva quasi esclusivamente tramite shell SSH, configurazioni manuali e editing diretto dei file di sistema.
Oggi esistono orchestrazione Kubernetes, Infrastructure as Code, Ansible, Terraform, deployment CI/CD, containerizzazione, osservabilità distribuita, cloud-native computing (di tutto questo parliamo più avanti…): il Linux “romantico” dei primi anni 2000, fatto di kernel compilati manualmente e notti passate a risolvere dependency hell, pare ormai cosa del passato.
Nel frattempo Linux è diventato l’infrastruttura che sostiene il mondo digitale moderno. Nel 2001 Linux sembrava marginale nel desktop consumer ma centrale tra gli appassionati. 25 anni dopo, sul desktop rimane minoritario, ma per tutto il resto è diventato assolutamente dominante.
Dall’assemblaggio dei PC all’era post-hardware
Per buona parte degli anni 2000 l’assemblaggio dei PC rappresentò una cultura tecnica vera e propria.
Gli utenti confrontavano chipset VIA KT133 e nForce, Pentium III Coppermine e Athlon Thunderbird, successivamente Athlon XP e Pentium 4 Northwood. Si discuteva di latenze CAS 2 o CAS 2.5, di FSB a 133 MHz, di memorie DDR appena introdotte, di AGP 4x e poi 8x, di dissipatori Thermalright SLK-800, Zalman CNPS e ventole Delta rumorosissime ma efficaci.
Gli utenti sostituivano CPU, GPU, RAM, alimentatori, ventole, controller IDE/SCSI, schede audio, schede TV, masterizzatori: per carità, lo si fa anche oggi in molte situazioni ma 25 anni fa l’hardware era assolutamente centrale. Anche i problemi erano “fisici”: temperature elevate, condensatori gonfi sulle motherboard, incompatibilità tra chipset, driver instabili, alimentatori insufficienti, IRQ condivisi.
Perfino l’installazione del sistema operativo richiedeva attenzione tecnica. Windows XP inizialmente non includeva driver SATA/AHCI: durante il setup bisognava premere F6 e caricare i driver da floppy disk.
Smartphone, notebook ultracompatti e cloud hanno progressivamente ridotto la centralità dell’hardware personalizzabile. Perfino il concetto di sistema operativo sta cambiando.
Windows è diventato una piattaforma-servizio continuamente aggiornata; Linux domina cloud e container; Android è il sistema operativo più diffuso al mondo. E oggi l’AI sta nuovamente ridefinendo tutto.
Virtualizzazione: quando il computer ha smesso di essere “fisico”
Uno dei cambiamenti più profondi e meno percepiti dal grande pubblico è stata la virtualizzazione. Il concetto di virtualizzazione nasce addirittura negli anni Sessanta in ambito mainframe IBM, ma è tra la fine degli anni ’90 e i primi anni 2000 che diventa una tecnologia realmente centrale nell’informatica moderna.
Nei primi anni 2000 un server era una macchina fisica dedicata: un sistema operativo, un’applicazione, un singolo hardware. Le aziende acquistavano rack completi di server Dell PowerEdge, HP ProLiant o IBM xSeries: ogni servizio aveva spesso un’infrastruttura separata. Poi arrivarono VMware ESX, Xen e successivamente KVM e Hyper-V.
Per la prima volta più sistemi operativi potevano convivere sullo stesso hardware fisico condividendo CPU, RAM, storage e rete tramite hypervisor. Nel giro di pochi anni le aziende smisero gradualmente di acquistare decine di server fisici per ogni servizio. Oggi un intero ambiente enterprise può vivere su cluster virtualizzati distribuiti tra più datacenter.
Dal server dedicato al cloud elastico
Nel 2001 pubblicare un sito Web significava spesso acquistare un server fisico, configurare Apache o IIS, installare manualmente PHP, gestire DNS, configurare firewall hardware, monitorare uptime e banda. L’infrastruttura richiedeva competenze sistemistiche profonde ed è proprio così che abbiamo iniziato.
Al giorno d’oggi in pochi minuti è possibile creare VPS cloud, attivare cluster Kubernetes, distribuire container Docker, configurare CDN globali, allocare storage object distribuito, scalare automaticamente CPU e RAM, attivare database gestiti, creare reti virtuali isolate. E tutto senza vedere fisicamente nemmeno una macchina.
Servizi come AWS EC2, Azure Virtual Machines, Google Cloud Compute Engine, Hetzner Cloud, OVHcloud, DigitalOcean, Aruba Cloud hanno trasformato l’infrastruttura IT in una risorsa elastica e plasmabile a proprio piacimento.
Oggi un’azienda può distribuire globalmente un’applicazione su più continenti in poche ore; nel 2001 servivano settimane di provisioning hardware.
L’ascesa dei container: applicazioni sempre più leggere e modulari
Negli anni 2010 arrivò un’altra rivoluzione fondamentale: i container. Docker ha cambiato profondamente il modo di sviluppare e distribuire software.
Prima dei container il deployment software era spesso problematico: dipendenze incompatibili, versioni librerie differenti, conflitti runtime, configurazioni inconsistenti, ambienti di sviluppo diversi dalla produzione. Con i container l’applicazione viene impacchettata insieme a runtime, librerie e dipendenze in un ambiente isolato e replicabile.
Kubernetes portò poi il concetto su scala massiva: orchestrazione automatica, autoscaling, self-healing, rolling update, service discovery, gestione cluster distribuiti. Tanto che oggi gran parte dell’infrastruttura Internet poggia su container orchestrati.
Moltissimi servizi che utilizziamo quotidianamente – streaming, ecommerce, collaboration suite, piattaforme cloud – funzionano proprio grazie a infrastrutture distribuite basate su container e microservizi.
L’infrastruttura è diventata software
Forse il cambiamento più radicale degli ultimi 25 anni è proprio questo: l’infrastruttura stessa è diventata software. Ed è un po’ quello che sostenevamo da anni: da quando IlSoftware.it è nato abbiamo sempre portato avanti l’idea di un progressivo scostamento dal “ferro” per concentrarsi sempre di più sull’architettura del software e sui suoi benefici tangibili.
Oggi esistono modelli operativi avanzati come l’Infrastructure as Code, che consente di gestire l’infrastruttura tramite codice, il Software Defined Networking e il Software Defined Storage, che virtualizzano rispettivamente reti e sistemi di archiviazione, l’Immutable Infrastructure, basata su componenti che non vengono modificati ma sostituiti integralmente e il Serverless Computing, in cui l’esecuzione delle applicazioni avviene senza gestire direttamente i server.
Un intero datacenter può essere descritto attraverso file YAML, utilizzati per definire configurazioni e risorse, e distribuito automaticamente con strumenti come Terraform, Ansible o Pulumi.
Le reti vengono virtualizzate tramite tecnologie SDN overlay, che creano infrastrutture di rete logiche indipendenti dall’hardware fisico sottostante. Anche i firewall sono diventati software distribuiti, eseguiti su infrastrutture virtuali anziché su dispositivi dedicati. Perfino i load balancer, che distribuiscono il traffico tra più server per migliorare prestazioni e affidabilità, sono ormai implementati in forma virtuale.
Nel 2001 tutto questo sarebbe sembrato fantascienza, eppure oggi è realtà.
Dal PC locale all’informatica distribuita
Anche il concetto stesso di computer personale si è trasformato. Nel 2001 quasi tutta l’elaborazione avveniva localmente: rendering, encoding, compilazione, archiviazione, backup.
Oggi gran parte del computing è distribuito: basti pensare a sincronizzazione cloud, a elaborazione AI remota, streaming gaming, SaaS, cloud rendering, desktop virtuali, edge computing. Moltissimi utenti utilizzano quotidianamente sistemi che dipendono costantemente da servizi remoti senza rendersene conto. Lo stesso smartphone moderno è in parte terminale locale e in parte interfaccia verso infrastrutture cloud globali.
E l’intelligenza artificiale sta accelerando ulteriormente questa trasformazione: i modelli linguistici richiedono cluster GPU giganteschi, reti InfiniBand, storage distribuito ad altissima velocità e consumi energetici in aumento.
Non è tutto “rose e fiori”, certo. Registriamo una crescente tendenza a ritornare a spostare parte delle elaborazioni in locale (on-premises): il motivo è spesso legato al concetto di sovranità digitale, quindi al controllo sul dato e alla protezione dei dati. D’altra parte la potenza computazionale e le tecnologie di storage evolute non mancano neppure in ambito locale.
L’intelligenza artificiale (AI): il nuovo spartiacque
Se il Web ha rappresentato la rivoluzione degli anni 2000 e lo smartphone quella degli anni 2010, l’intelligenza artificiale generativa sta diventando il grande spartiacque degli anni 2020.
Stavolta il cambiamento è ancora più profondo perché non riguarda soltanto nuove piattaforme, nuovi dispositivi o nuove modalità di accesso alla rete: riguarda il modo stesso in cui il software funziona. Per oltre 50 anni l’informatica moderna si è basata quasi esclusivamente su paradigmi procedurali e deterministici.
Il software tradizionale esegue istruzioni definite esplicitamente da uno sviluppatore: input prevedibili, logica definita, output deterministici, flussi controllabili, algoritmi descritti passo passo. Anche i sistemi più complessi – database, browser, sistemi operativi, hypervisor, motori grafici – funzionano seguendo regole rigidamente codificate.
L’AI moderna rompe questo schema: i Large Language Model (LLM) non “conoscono” realmente regole nel senso classico del termine. Operano invece tramite modelli probabilistici giganteschi addestrati su quantità enormi di dati.
Dalle reti neurali classiche ai transformer
Le reti neurali esistono da decenni, ma fino agli anni 2010 erano limitate da capacità computazionale insufficiente, dataset troppo piccoli, GPU non ottimizzate, limiti nella parallelizzazione e problemi di training.
La svolta è arrivata progressivamente con CUDA di NVIDIA, GPU programmabili, deep learning moderno, dataset massivi, accelerazione tensoriale e architetture transformer. Proprio lo studio “Attention Is All You Need” pubblicato da Google nel 2017 ha rappresentato uno dei momenti più importanti della storia recente dell’informatica.
L’architettura Transformer ha introdotto il meccanismo di self-attention, una tecnica che consente ai modelli di analizzare e comprendere le relazioni tra le parole all’interno di un testo, anche su grandi quantità di dati e contesti molto complessi. Per la prima volta il software non si limitava a eseguire comandi: iniziava a generare testo, codice, immagini, audio e contenuti coerenti.
Per decenni programmare ha significato descrivere esplicitamente cosa dovesse fare una macchina. Oggi, sempre più spesso, si definisce un obiettivo, un contesto, un prompt e dei vincoli probabilistici: il sistema genera autonomamente il risultato. Tutto questo introduce problematiche completamente nuove che si intersecano su più livelli ma è qualcosa che nel 2001 era raccontano, in termini diversi, solo nei film e nei libri di fantascienza.
L’AI sta ridefinendo tutto il software
L’intelligenza artificiale non è più un settore separato dell’informatica: sta diventando un layer trasversale integrato ovunque. Lasciamo perdere le integrazioni forzate di funzionalità AI in certi sistemi operativi, mettiamo da parte gli annunci legati solo al marketing o il “braccio di ferro” tra aziende per mostrare che sono in grado di integrare l’AI nei flussi di lavoro.
L’AI introduce invece interfacce conversazionali, agenti autonomi e sistemi capaci di interpretare linguaggio naturale. Se utilizzata in modo costruttivo, l’AI è una delle novità più stimolanti degli ultimi decenni. Senza alcuna ombra di dubbio.
Per la prima volta il software non richiede necessariamente conoscenze tecniche approfondite per essere utilizzato in modo avanzato: la barriera di accesso si abbassa drasticamente. Il software smette di essere “passivo” perché un utente può scrivere codice presentando l’obiettivo prefisso, generare script complessi, analizzare dati, creare immagini, automatizzare processi, sintetizzare documentazione, tradurre contenuti, ottenere spiegazioni tecniche contestualizzate. Il tutto semplicemente usando linguaggio naturale.
AI come copilota, non come sostituto
Gran parte della narrativa più estrema sull’intelligenza artificiale oscilla continuamente tra due poli opposti: entusiasmo incontrollato e catastrofismo assoluto. La realtà tecnica è invece molto più complessa. I modelli AI sono straordinariamente potenti ma presentano ancora limiti evidenti: per questo motivo il modello più efficace oggi non è “AI contro uomo“, ma “AI insieme all’uomo“.
L’intelligenza artificiale eccelle soprattutto quanto si parla di accelerazione operativa, automazione ripetitiva, supporto creativo, sintesi, correlazione di informazioni, generazione preliminare e assistenza contestuale ma il controllo umano rimane centrale.
Uno sviluppatore esperto utilizza l’AI per velocizzare scrittura, debugging e prototipazione, non per eliminare completamente il processo di validazione. Ed è esattamente il punto di vista, tra i tanti, di Linus Torvalds. Un sistemista può generare rapidamente configurazioni Terraform, script Bash o pipeline CI/CD, ma deve comunque verificare sicurezza, robustezza e correttezza architetturale.
Un giornalista può usare l’AI per organizzare dati e documentazione, ma l’analisi critica, la verifica delle fonti e la contestualizzazione restano attività profondamente umane.
L’AI deve amplificare le competenze, non appiattirle e uniformare tutto. L’AI deve essere un acceleratore cognitivo. Fischi e boooo degli studenti quando si parla di AI? Fanno bene quando ci sono aziende che si vantano (a torto) di usare l’AI per sostituire processi fino a ieri gestiti dagli umani.
Il lavoro cambierà, ma non sarà semplice da raccontare
Come ogni grande rivoluzione tecnologica, anche l’AI cambierà inevitabilmente il mondo lavoro. È già successo molte volte nella storia dell’informatica.
L’automazione industriale ha eliminato alcune attività manuali ma ne ha create moltissime altre; Internet ha distrutto interi modelli economici e contemporaneamente ne ha generati di nuovi; il cloud ha ridotto alcune necessità infrastrutturali locali ma ha creato enormi ecosistemi DevOps, SRE e cloud engineering. Con l’AI probabilmente assisteremo a una trasformazione simile.
Le attività più ripetitive, standardizzabili e procedurali saranno sempre più automatizzate ma, allo stesso tempo, aumenterà enormemente il valore di capacità analitica, pensiero critico, supervisione, validazione, creatività, progettazione, interpretazione, gestione della complessità.
Dall’interfaccia grafica all’interfaccia cognitiva
Guardando indietro agli ultimi 25 anni emerge una linea evolutiva molto chiara:
Negli anni ’80 la rivoluzione fu l’interfaccia grafica.
Negli anni ’90 Internet.
Negli anni 2000 il Web.
Negli anni ’10 del nuovo secolo lo smartphone e il cloud.
Negli anni ’20 potrebbe essere invece l’interfaccia cognitiva.
È forse proprio questo il punto più affascinante guardando indietro ai 25 anni di IlSoftware.it: dal modem 56k all’intelligenza artificiale generativa, ogni fase dell’evoluzione tecnologica è sembrata quasi “definitiva”. E invece era soltanto il fondamento della successiva.
/https://www.ilsoftware.it/app/uploads/2026/07/lionel-messi-argentina.jpeg "Come vedere Argentina-Svizzera in streaming dall'estero")
/https://www.ilsoftware.it/app/uploads/2025/02/2-1.jpg "Microsoft corregge una falla zero-day di Defender che riempie il disco")
/https://www.ilsoftware.it/app/uploads/2026/06/donna-davanti-al-computer.jpg "Il nuovo antivirus con AI di Avast è in offerta a oltre metà prezzo (-60%)")
/https://www.ilsoftware.it/app/uploads/2025/10/CAPTCHA-fraudolenti-riconoscerli.jpg "I CAPTCHA hanno ancora senso nell'era dell'AI?")
{kind=link}